 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoSD: Topology-Enhanced Lane Segment Perception with SDMap Prior
Nov 22, 2024



Recent advances in autonomous driving systems have shifted towards reducing reliance on high-definition maps (HDMaps) due to the huge costs of annotation and maintenance. Instead, researchers are focusing on online vectorized HDMap construction using on-board sensors. However, sensor-only approaches still face challenges in long-range perception due to the restricted views imposed by the mounting angles of onboard cameras, just as human drivers also rely on bird's-eye-view navigation maps for a comprehensive understanding of road structures. To address these issues, we propose to train the perception model to "see" standard definition maps (SDMaps). We encode SDMap elements into neural spatial map representations and instance tokens, and then incorporate such complementary features as prior information to improve the bird's eye view (BEV) feature for lane geometry and topology decoding. Based on the lane segment representation framework, the model simultaneously predicts lanes, centrelines and their topology. To further enhance the ability of geometry prediction and topology reasoning, we also use a topology-guided decoder to refine the predictions by exploiting the mutual relationships between topological and geometric features. We perform extensive experiments on OpenLane-V2 datasets to validate the proposed method. The results show that our model outperforms state-of-the-art methods by a large margin, with gains of +6.7 and +9.1 on the mAP and topology metrics. Our analysis also reveals that models trained with SDMap noise augmentation exhibit enhanced robustness.
MGMapNet: Multi-Granularity Representation Learning for End-to-End Vectorized HD Map Construction
Oct 10, 2024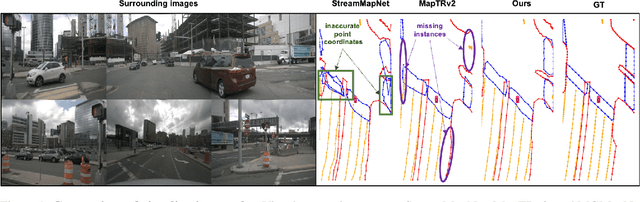
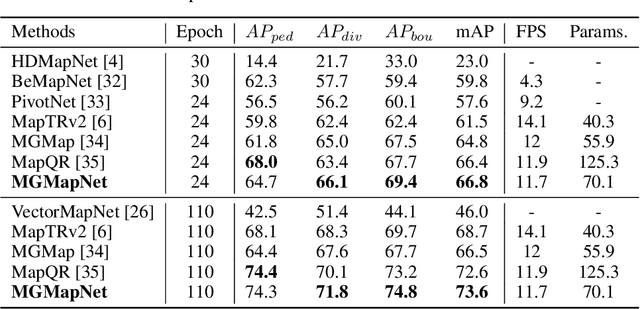
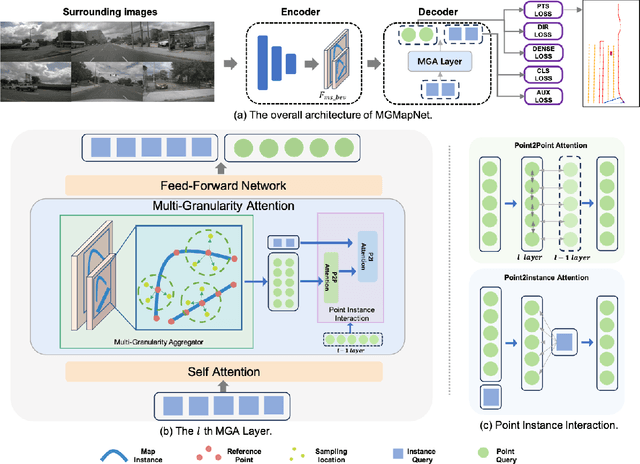

The construction of Vectorized High-Definition (HD) map typically requires capturing both category and geometry information of map elements. Current state-of-the-art methods often adopt solely either point-level or instance-level representation, overlooking the strong intrinsic relationships between points and instances. In this work, we propose a simple yet efficient framework named MGMapNet (Multi-Granularity Map Network) to model map element with a multi-granularity representation, integrating both coarse-grained instance-level and fine-grained point-level queries. Specifically, these two granularities of queries are generated from the multi-scale bird's eye view (BEV) features using a proposed Multi-Granularity Aggregator. In this module, instance-level query aggregates features over the entire scope covered by an instance, and the point-level query aggregates features locally. Furthermore, a Point Instance Interaction module is designed to encourage information exchange between instance-level and point-level queries. Experimental results demonstrate that the proposed MGMapNet achieves state-of-the-art performance, surpassing MapTRv2 by 5.3 mAP on nuScenes and 4.4 mAP on Argoverse2 respectively.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

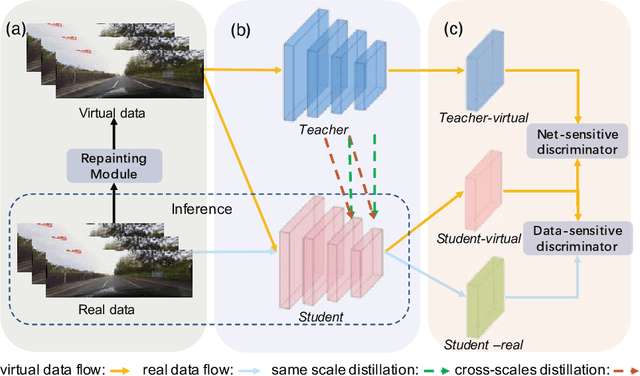
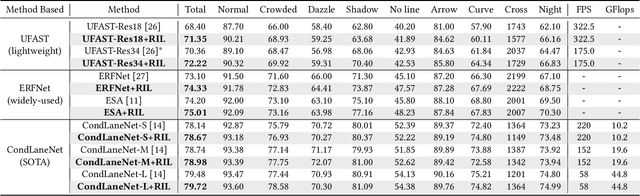
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
Paint and Distill: Boosting 3D Object Detection with Semantic Passing Network
Jul 12, 2022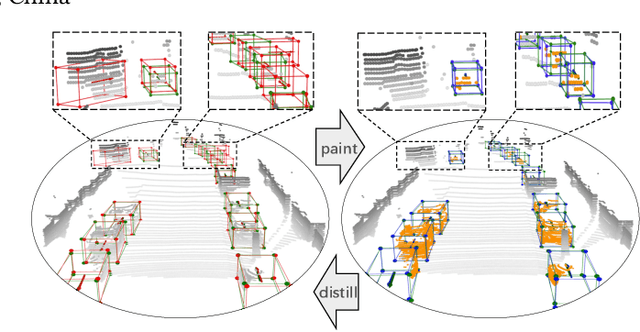
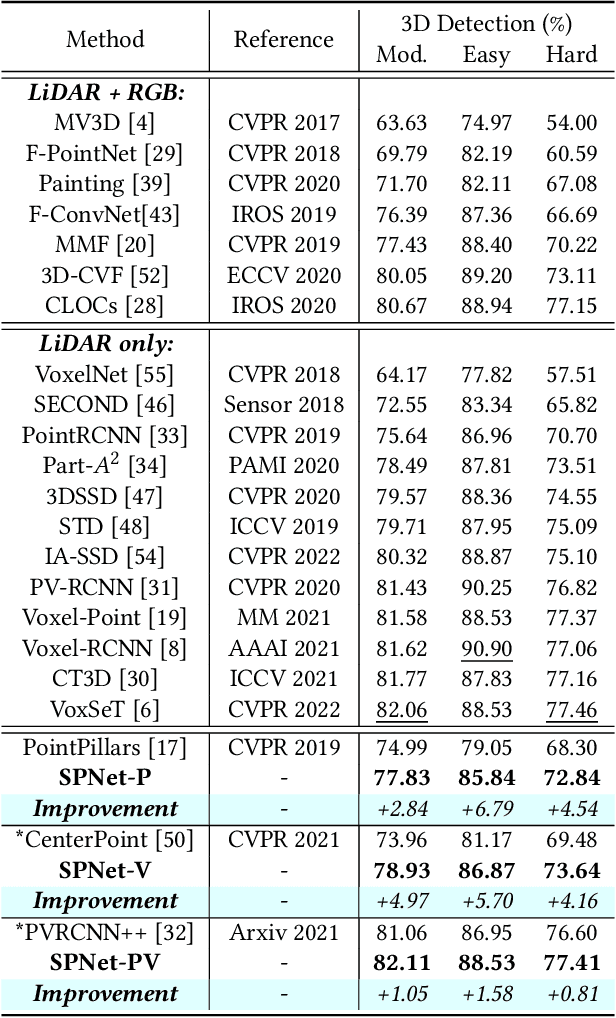
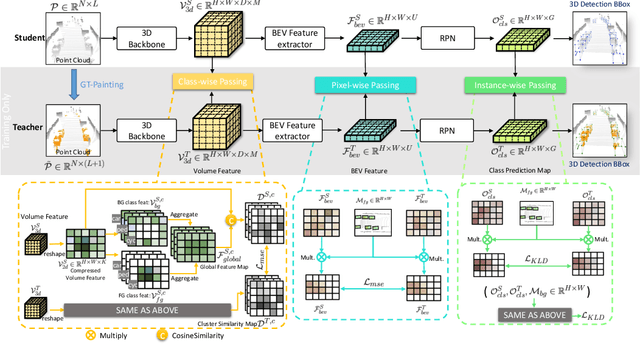
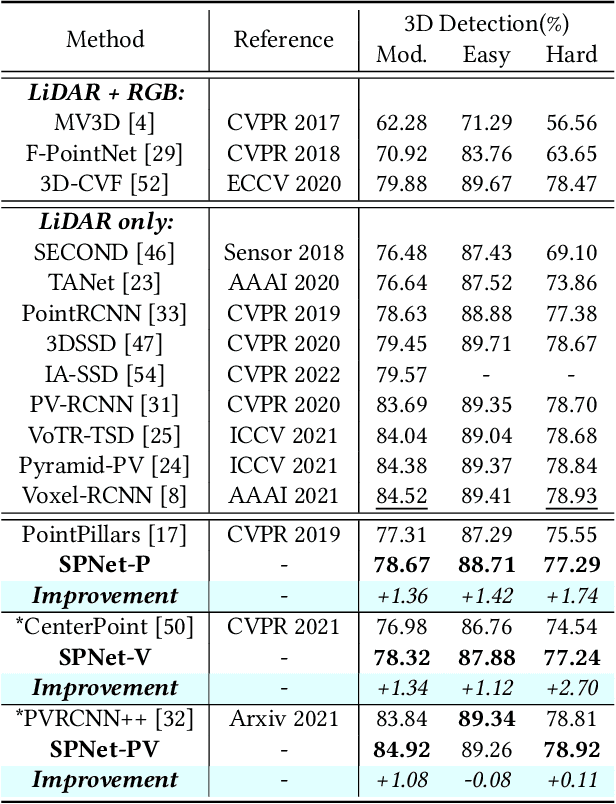
3D object detection task from lidar or camera sensors is essential for autonomous driving. Pioneer attempts at multi-modality fusion complement the sparse lidar point clouds with rich semantic texture information from images at the cost of extra network designs and overhead. In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference. Our key design is to first exploit the potential instructive semantic knowledge within the ground-truth labels by training a semantic-painted teacher model and then guide the pure-lidar network to learn the semantic-painted representation via knowledge passing modules at different granularities: class-wise passing, pixel-wise passing and instance-wise passing. Experimental results show that the proposed SPNet can seamlessly cooperate with most existing 3D detection frameworks with 1~5% AP gain and even achieve new state-of-the-art 3D detection performance on the KITTI test benchmark. Code is available at: https://github.com/jb892/SPNet.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 29, 2020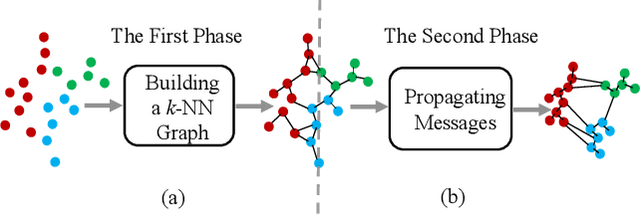

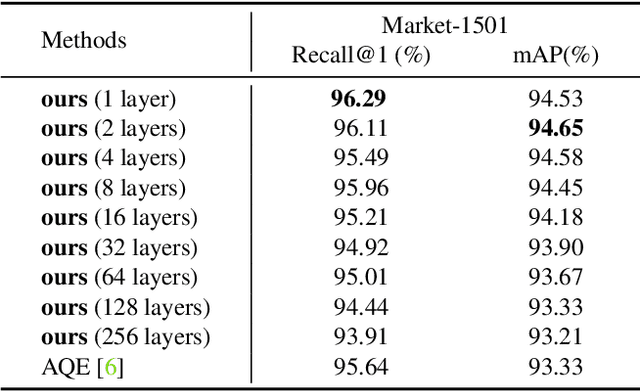
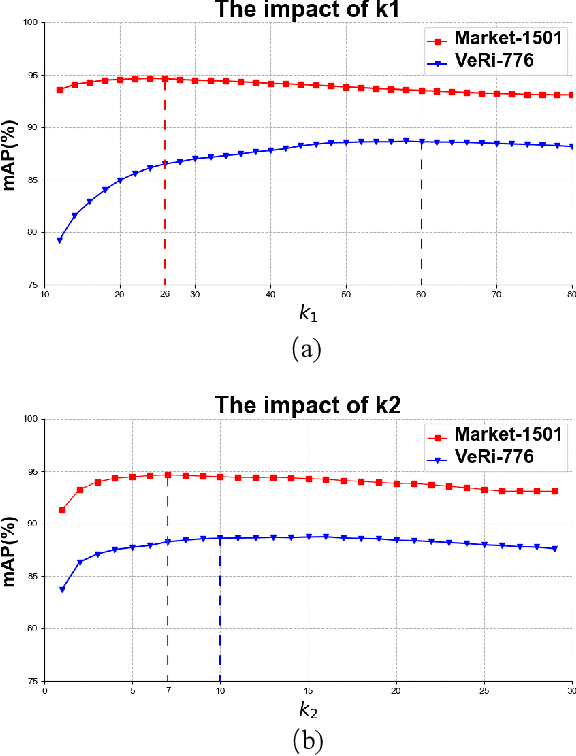
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
Discriminative Sounding Objects Localization via Self-supervised Audiovisual Matching
Oct 12, 2020
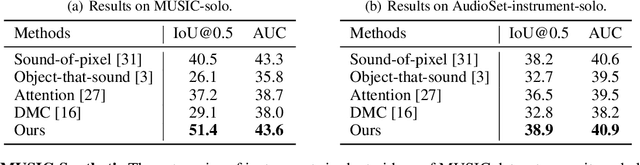
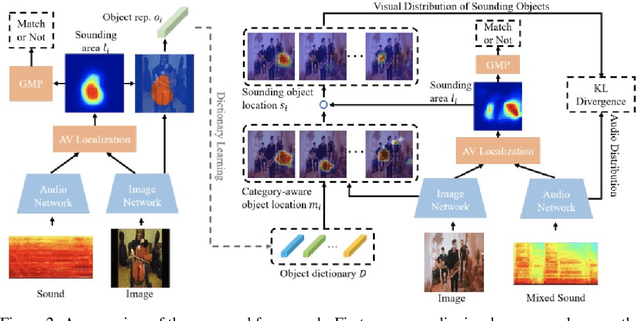
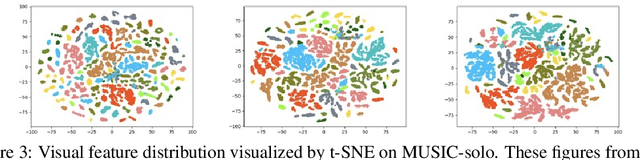
Discriminatively localizing sounding objects in cocktail-party, i.e., mixed sound scenes, is commonplace for humans, but still challenging for machines. In this paper, we propose a two-stage learning framework to perform self-supervised class-aware sounding object localization. First, we propose to learn robust object representations by aggregating the candidate sound localization results in the single source scenes. Then, class-aware object localization maps are generated in the cocktail-party scenarios by referring the pre-learned object knowledge, and the sounding objects are accordingly selected by matching audio and visual object category distributions, where the audiovisual consistency is viewed as the self-supervised signal. Experimental results in both realistic and synthesized cocktail-party videos demonstrate that our model is superior in filtering out silent objects and pointing out the location of sounding objects of different classes. Code is available at https://github.com/DTaoo/Discriminative-Sounding-Objects-Localization.