 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaint and Distill: Boosting 3D Object Detection with Semantic Passing Network
Jul 12, 2022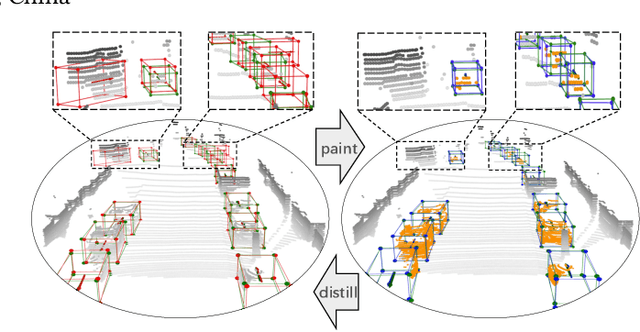
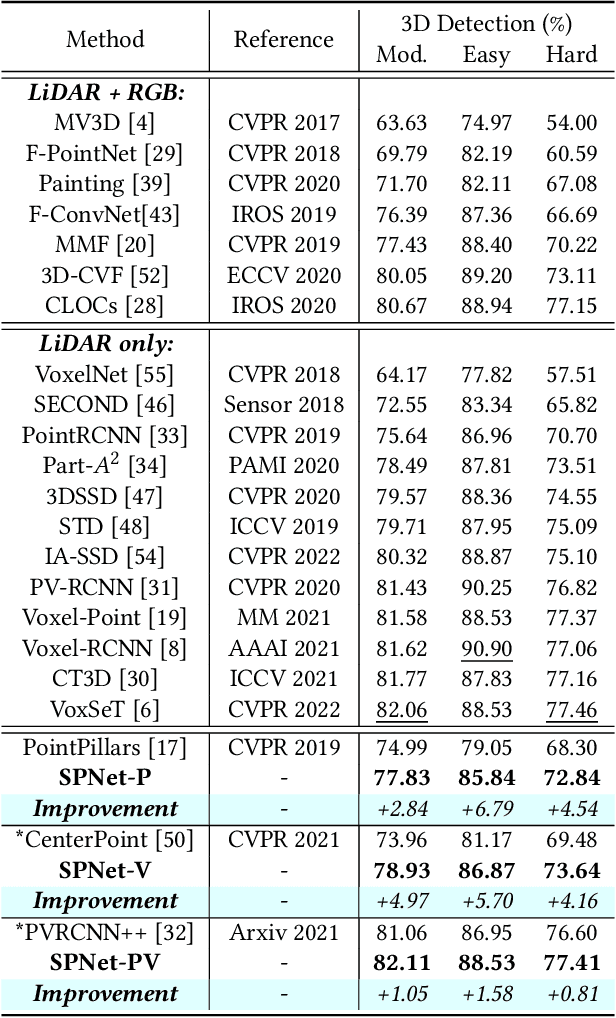
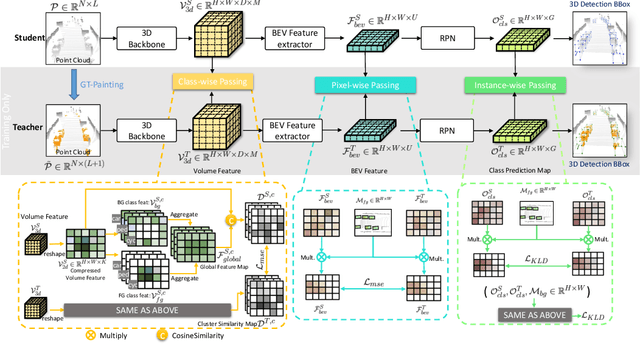
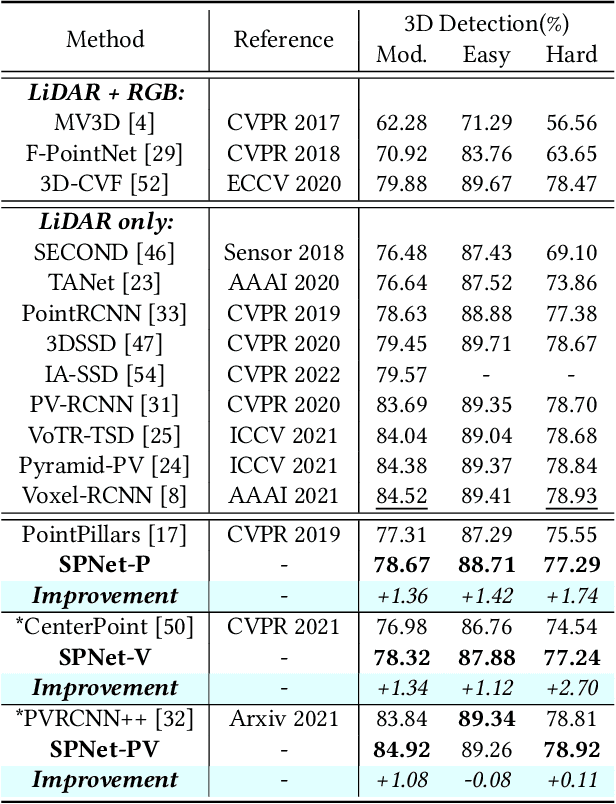
3D object detection task from lidar or camera sensors is essential for autonomous driving. Pioneer attempts at multi-modality fusion complement the sparse lidar point clouds with rich semantic texture information from images at the cost of extra network designs and overhead. In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference. Our key design is to first exploit the potential instructive semantic knowledge within the ground-truth labels by training a semantic-painted teacher model and then guide the pure-lidar network to learn the semantic-painted representation via knowledge passing modules at different granularities: class-wise passing, pixel-wise passing and instance-wise passing. Experimental results show that the proposed SPNet can seamlessly cooperate with most existing 3D detection frameworks with 1~5% AP gain and even achieve new state-of-the-art 3D detection performance on the KITTI test benchmark. Code is available at: https://github.com/jb892/SPNet.