 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Learning: A Novel Combination of Self-Supervised and Supervised Learning for MRI Reconstruction without High-Quality Training Reference
May 09, 2025Purpose: Deep learning has demonstrated strong potential for MRI reconstruction, but conventional supervised learning methods require high-quality reference images, which are often unavailable in practice. Self-supervised learning offers an alternative, yet its performance degrades at high acceleration rates. To overcome these limitations, we propose hybrid learning, a novel two-stage training framework that combines self-supervised and supervised learning for robust image reconstruction. Methods: Hybrid learning is implemented in two sequential stages. In the first stage, self-supervised learning is employed to generate improved images from noisy or undersampled reference data. These enhanced images then serve as pseudo-ground truths for the second stage, which uses supervised learning to refine reconstruction performance and support higher acceleration rates. We evaluated hybrid learning in two representative applications: (1) accelerated 0.55T spiral-UTE lung MRI using noisy reference data, and (2) 3D T1 mapping of the brain without access to fully sampled ground truth. Results: For spiral-UTE lung MRI, hybrid learning consistently improved image quality over both self-supervised and conventional supervised methods across different acceleration rates, as measured by SSIM and NMSE. For 3D T1 mapping, hybrid learning achieved superior T1 quantification accuracy across a wide dynamic range, outperforming self-supervised learning in all tested conditions. Conclusions: Hybrid learning provides a practical and effective solution for training deep MRI reconstruction networks when only low-quality or incomplete reference data are available. It enables improved image quality and accurate quantitative mapping across different applications and field strengths, representing a promising technique toward broader clinical deployment of deep learning-based MRI.
DeepEMC-T2 Mapping: Deep Learning-Enabled T2 Mapping Based on Echo Modulation Curve Modeling
Feb 29, 2024Purpose: Echo modulation curve (EMC) modeling can provide accurate and reproducible quantification of T2 relaxation times. The standard EMC-T2 mapping framework, however, requires sufficient echoes and cumbersome pixel-wise dictionary-matching steps. This work proposes a deep learning version of EMC-T2 mapping, called DeepEMC-T2 mapping, to efficiently estimate accurate T2 maps from fewer echoes without a dictionary. Methods: DeepEMC-T2 mapping was developed using a modified U-Net to estimate both T2 and Proton Density (PD) maps directly from multi-echo spin-echo (MESE) images. The modified U-Net employs several new features to improve the accuracy of T2/PD estimation. MESE datasets from 68 subjects were used for training and evaluation of the DeepEMC-T2 mapping technique. Multiple experiments were conducted to evaluate the impact of the proposed new features on DeepEMC-T2 mapping. Results: DeepEMC-T2 mapping achieved T2 estimation errors ranging from 3%-12% in different T2 ranges and 0.8%-1.7% for PD estimation with 10/7/5/3 echoes, which yielded more accurate parameter estimation than standard EMC-T2 mapping. The new features proposed in DeepEMC-T2 mapping enabled improved parameter estimation. The use of a larger echo spacing with fewer echoes can maintain the accuracy of T2 and PD estimations while reducing the number of 180-degree refocusing pulses. Conclusions: DeepEMC-T2 mapping enables simplified, efficient, and accurate T2 quantification directly from MESE images without a time-consuming dictionary-matching step and requires fewer echoes. This allows for increased volumetric coverage and/or decreased SAR by reducing the number of 180-degree refocusing pulses.
Self-Supervised Learning based Depth Estimation from Monocular Images
Apr 14, 2023Depth Estimation has wide reaching applications in the field of Computer vision such as target tracking, augmented reality, and self-driving cars. The goal of Monocular Depth Estimation is to predict the depth map, given a 2D monocular RGB image as input. The traditional depth estimation methods are based on depth cues and used concepts like epipolar geometry. With the evolution of Convolutional Neural Networks, depth estimation has undergone tremendous strides. In this project, our aim is to explore possible extensions to existing SoTA Deep Learning based Depth Estimation Models and to see whether performance metrics could be further improved. In a broader sense, we are looking at the possibility of implementing Pose Estimation, Efficient Sub-Pixel Convolution Interpolation, Semantic Segmentation Estimation techniques to further enhance our proposed architecture and to provide fine-grained and more globally coherent depth map predictions. We also plan to do away with camera intrinsic parameters during training and apply weather augmentations to further generalize our model.
Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance
Sep 17, 2022
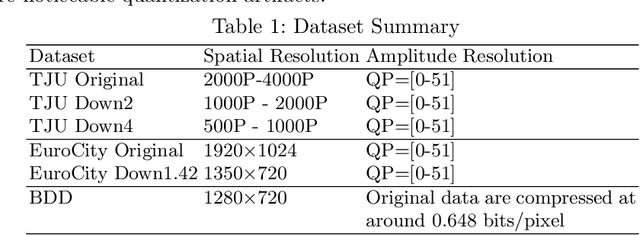


Deep learning has made great strides for object detection in images. The detection accuracy and computational cost of object detection depend on the spatial resolution of an image, which may be constrained by both the camera and storage considerations. Compression is often achieved by reducing either spatial or amplitude resolution or, at times, both, both of which have well-known effects on performance. Detection accuracy also depends on the distance of the object of interest from the camera. Our work examines the impact of spatial and amplitude resolution, as well as object distance, on object detection accuracy and computational cost. We develop a resolution-adaptive variant of YOLOv5 (RA-YOLO), which varies the number of scales in the feature pyramid and detection head based on the spatial resolution of the input image. To train and evaluate this new method, we created a dataset of images with diverse spatial and amplitude resolutions by combining images from the TJU and Eurocity datasets and generating different resolutions by applying spatial resizing and compression. We first show that RA-YOLO achieves a good trade-off between detection accuracy and inference time over a large range of spatial resolutions. We then evaluate the impact of spatial and amplitude resolutions on object detection accuracy using the proposed RA-YOLO model. We demonstrate that the optimal spatial resolution that leads to the highest detection accuracy depends on the 'tolerated' image size. We further assess the impact of the distance of an object to the camera on the detection accuracy and show that higher spatial resolution enables a greater detection range. These results provide important guidelines for choosing the image spatial resolution and compression settings predicated on available bandwidth, storage, desired inference time, and/or desired detection range, in practical applications.
Network-Aware 5G Edge Computing for Object Detection: Augmenting Wearables to "See'' More, Farther and Faster
Dec 25, 2021


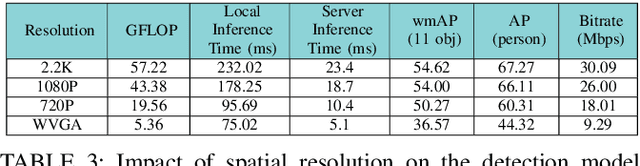
Advanced wearable devices are increasingly incorporating high-resolution multi-camera systems. As state-of-the-art neural networks for processing the resulting image data are computationally demanding, there has been growing interest in leveraging fifth generation (5G) wireless connectivity and mobile edge computing for offloading this processing to the cloud. To assess this possibility, this paper presents a detailed simulation and evaluation of 5G wireless offloading for object detection within a powerful, new smart wearable called VIS4ION, for the Blind-and-Visually Impaired (BVI). The current VIS4ION system is an instrumented book-bag with high-resolution cameras, vision processing and haptic and audio feedback. The paper considers uploading the camera data to a mobile edge cloud to perform real-time object detection and transmitting the detection results back to the wearable. To determine the video requirements, the paper evaluates the impact of video bit rate and resolution on object detection accuracy and range. A new street scene dataset with labeled objects relevant to BVI navigation is leveraged for analysis. The vision evaluation is combined with a detailed full-stack wireless network simulation to determine the distribution of throughputs and delays with real navigation paths and ray-tracing from new high-resolution 3D models in an urban environment. For comparison, the wireless simulation considers both a standard 4G-Long Term Evolution (LTE) carrier and high-rate 5G millimeter-wave (mmWave) carrier. The work thus provides a thorough and realistic assessment of edge computing with mmWave connectivity in an application with both high bandwidth and low latency requirements.