 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating OCR Performance for Assistive Technology: Effects of Walking Speed, Camera Placement, and Camera Type
Feb 02, 2026Optical character recognition (OCR), which converts printed or handwritten text into machine-readable form, is widely used in assistive technology for people with blindness and low vision. Yet, most evaluations rely on static datasets that do not reflect the challenges of mobile use. In this study, we systematically evaluated OCR performance under both static and dynamic conditions. Static tests measured detection range across distances of 1-7 meters and viewing angles of 0-75 degrees horizontally. Dynamic tests examined the impact of motion by varying walking speed from slow (0.8 m/s) to very fast (1.8 m/s) and comparing three camera mounting positions: head-mounted, shoulder-mounted, and hand-held. We evaluated both a smartphone and smart glasses, using the phone's main and ultra-wide cameras. Four OCR engines were benchmarked to assess accuracy at different distances and viewing angles: Google Vision, PaddleOCR 3.0, EasyOCR, and Tesseract. PaddleOCR 3.0 was then used to evaluate accuracy at different walking speeds. Accuracy was computed at the character level using the Levenshtein ratio against manually defined ground truth. Results showed that recognition accuracy declined with increased walking speed and wider viewing angles. Google Vision achieved the highest overall accuracy, with PaddleOCR close behind as the strongest open-source alternative. Across devices, the phone's main camera achieved the highest accuracy, and a shoulder-mounted placement yielded the highest average among body positions; however, differences among shoulder, head, and hand were not statistically significant.
Robust Computer-Vision based Construction Site Detection for Assistive-Technology Applications
Mar 06, 2025Navigating urban environments poses significant challenges for people with disabilities, particularly those with blindness and low vision. Environments with dynamic and unpredictable elements like construction sites are especially challenging. Construction sites introduce hazards like uneven surfaces, obstructive barriers, hazardous materials, and excessive noise, and they can alter routing, complicating safe mobility. Existing assistive technologies are limited, as navigation apps do not account for construction sites during trip planning, and detection tools that attempt hazard recognition struggle to address the extreme variability of construction paraphernalia. This study introduces a novel computer vision-based system that integrates open-vocabulary object detection, a YOLO-based scaffolding-pole detection model, and an optical character recognition (OCR) module to comprehensively identify and interpret construction site elements for assistive navigation. In static testing across seven construction sites, the system achieved an overall accuracy of 88.56\%, reliably detecting objects from 2m to 10m within a 0$^\circ$ -- 75$^\circ$ angular offset. At closer distances (2--4m), the detection rate was 100\% at all tested angles. At
Detect and Approach: Close-Range Navigation Support for People with Blindness and Low Vision
Aug 17, 2022

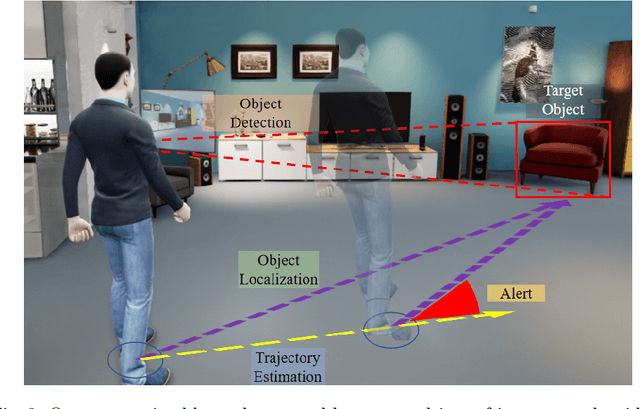
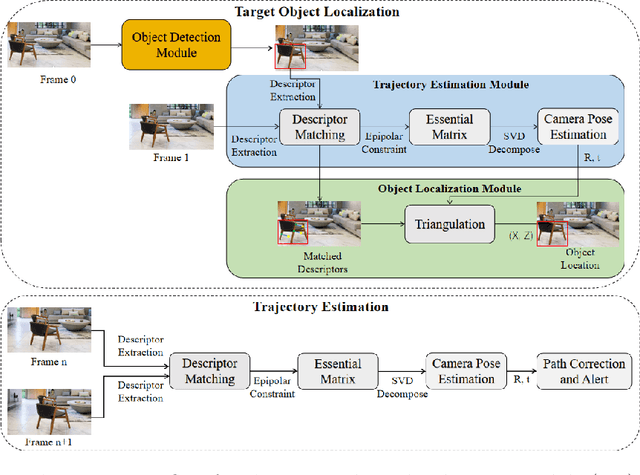
People with blindness and low vision (pBLV) experience significant challenges when locating final destinations or targeting specific objects in unfamiliar environments. Furthermore, besides initially locating and orienting oneself to a target object, approaching the final target from one's present position is often frustrating and challenging, especially when one drifts away from the initial planned path to avoid obstacles. In this paper, we develop a novel wearable navigation solution to provide real-time guidance for a user to approach a target object of interest efficiently and effectively in unfamiliar environments. Our system contains two key visual computing functions: initial target object localization in 3D and continuous estimation of the user's trajectory, both based on the 2D video captured by a low-cost monocular camera mounted on in front of the chest of the user. These functions enable the system to suggest an initial navigation path, continuously update the path as the user moves, and offer timely recommendation about the correction of the user's path. Our experiments demonstrate that our system is able to operate with an error of less than 0.5 meter both outdoor and indoor. The system is entirely vision-based and does not need other sensors for navigation, and the computation can be run with the Jetson processor in the wearable system to facilitate real-time navigation assistance.