 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Paper and Code
Apr 13, 2025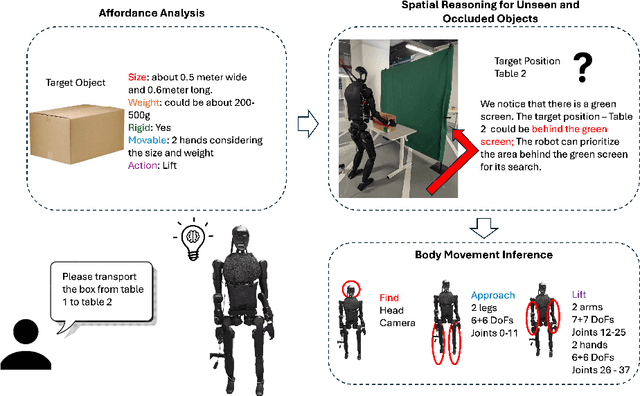
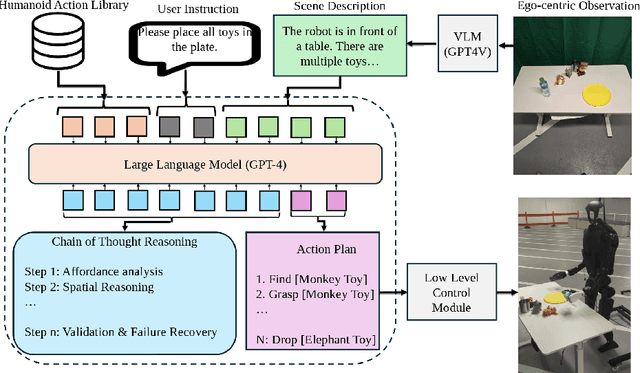
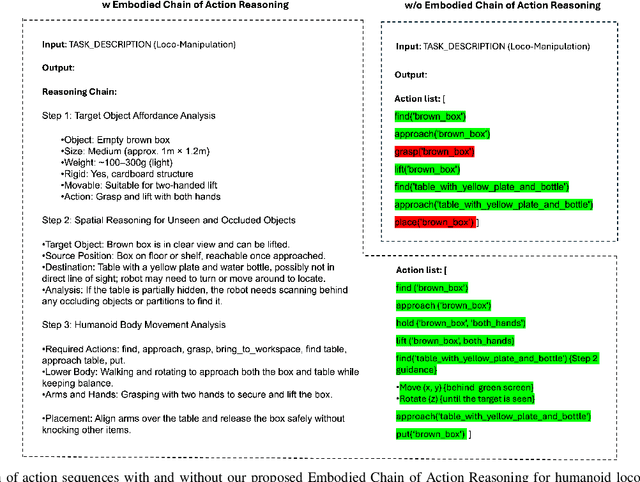

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.