 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies
May 23, 2025We present a hierarchical policy-learning framework that enables a legged humanoid to cooperatively carry extended loads with a human partner using only haptic cues for intent inference. At the upper tier, a lightweight behavior-cloning network consumes six-axis force/torque streams from dual wrist-mounted sensors and outputs whole-body planar velocity commands that capture the leader's applied forces. At the lower tier, a deep-reinforcement-learning policy, trained under randomized payloads (0-3 kg) and friction conditions in Isaac Gym and validated in MuJoCo and on a real Unitree G1, maps these high-level twists to stable, under-load joint trajectories. By decoupling intent interpretation (force -> velocity) from legged locomotion (velocity -> joints), our method combines intuitive responsiveness to human inputs with robust, load-adaptive walking. We collect training data without motion-capture or markers, only synchronized RGB video and F/T readings, employing SAM2 and WHAM to extract 3D human pose and velocity. In real-world trials, our humanoid achieves cooperative carry-and-move performance (completion time, trajectory deviation, velocity synchrony, and follower-force) on par with a blindfolded human-follower baseline. This work is the first to demonstrate learned haptic guidance fused with full-body legged control for fluid human-humanoid co-manipulation. Code and videos are available on the H2-COMPACT website.
Embodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Apr 13, 2025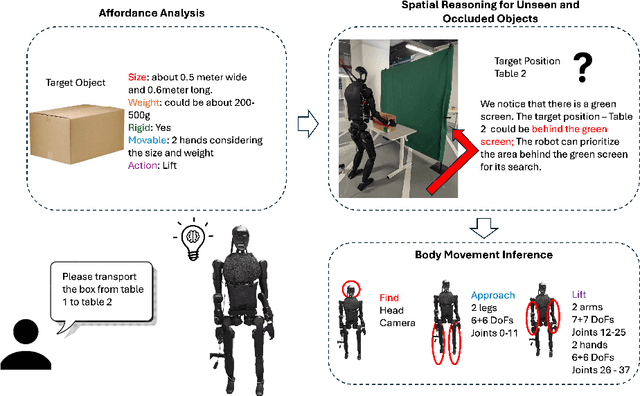
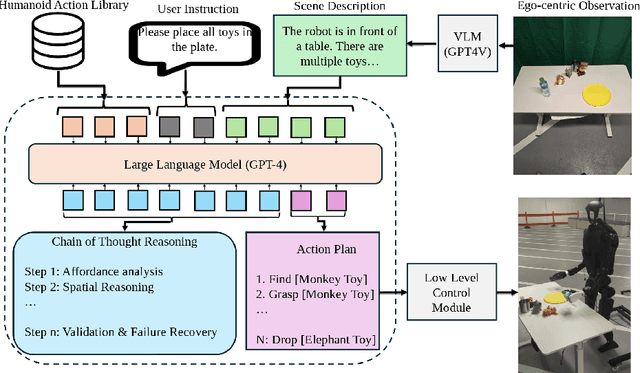
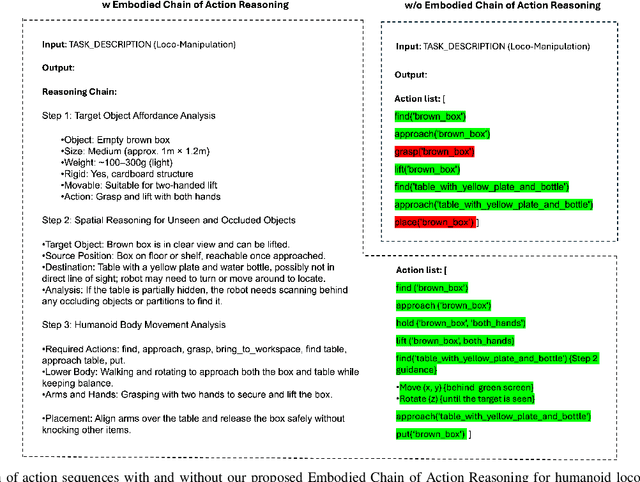

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.
SPAQ-DL-SLAM: Towards Optimizing Deep Learning-based SLAM for Resource-Constrained Embedded Platforms
Sep 22, 2024



Optimizing Deep Learning-based Simultaneous Localization and Mapping (DL-SLAM) algorithms is essential for efficient implementation on resource-constrained embedded platforms, enabling real-time on-board computation in autonomous mobile robots. This paper presents SPAQ-DL-SLAM, a framework that strategically applies Structured Pruning and Quantization (SPAQ) to the architecture of one of the state-ofthe-art DL-SLAM algorithms, DROID-SLAM, for resource and energy-efficiency. Specifically, we perform structured pruning with fine-tuning based on layer-wise sensitivity analysis followed by 8-bit post-training static quantization (PTQ) on the deep learning modules within DROID-SLAM. Our SPAQ-DROIDSLAM model, optimized version of DROID-SLAM model using our SPAQ-DL-SLAM framework with 20% structured pruning and 8-bit PTQ, achieves an 18.9% reduction in FLOPs and a 79.8% reduction in overall model size compared to the DROID-SLAM model. Our evaluations on the TUM-RGBD benchmark shows that SPAQ-DROID-SLAM model surpasses the DROID-SLAM model by an average of 10.5% on absolute trajectory error (ATE) metric. Additionally, our results on the ETH3D SLAM training benchmark demonstrate enhanced generalization capabilities of the SPAQ-DROID-SLAM model, seen by a higher Area Under the Curve (AUC) score and success in 2 additional data sequences compared to the DROIDSLAM model. Despite these improvements, the model exhibits performance variance on the distinct Vicon Room sequences from the EuRoC dataset, which are captured at high angular velocities. This varying performance at some distinct scenarios suggests that designing DL-SLAM algorithms taking operating environments and tasks in consideration can achieve optimal performance and resource efficiency for deployment in resource-constrained embedded platforms.