 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Model-Based Optimization: Comprehensive Review
Mar 21, 2025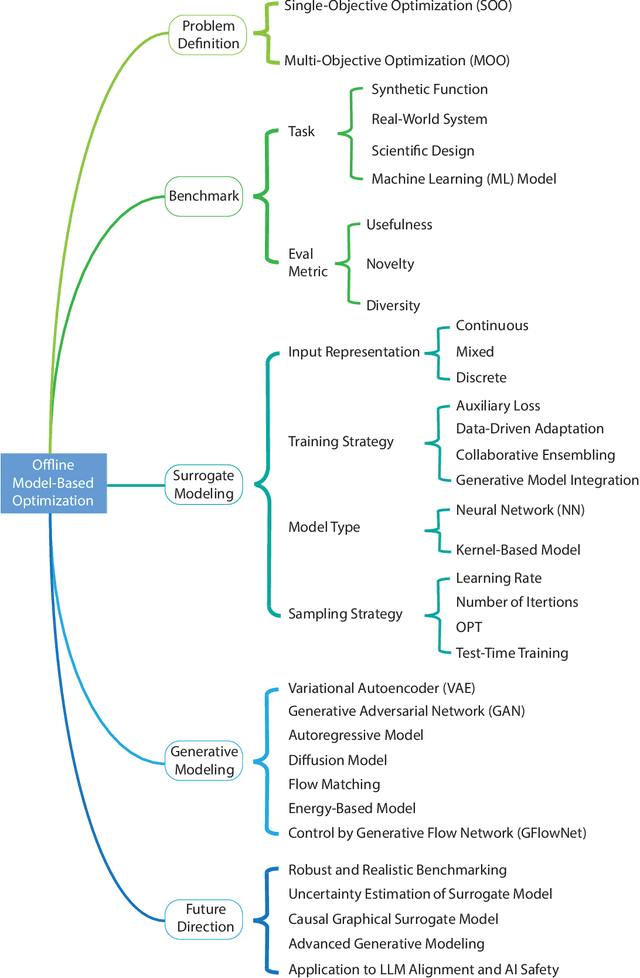
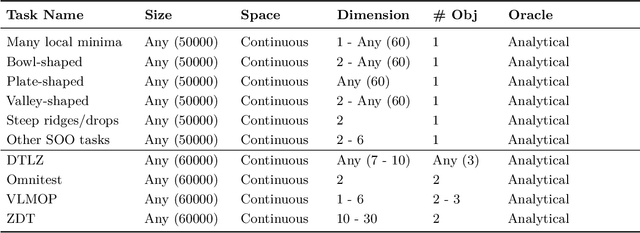

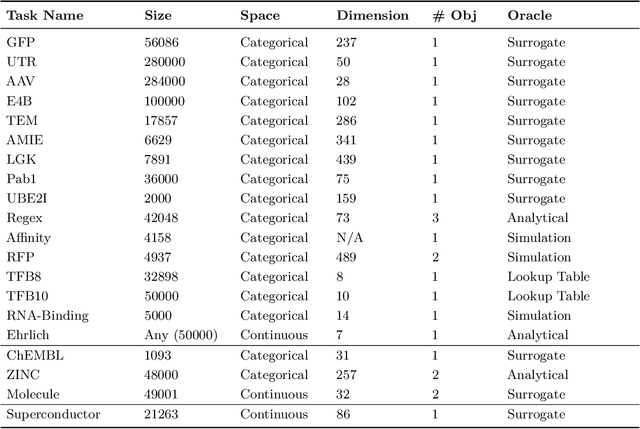
Offline optimization is a fundamental challenge in science and engineering, where the goal is to optimize black-box functions using only offline datasets. This setting is particularly relevant when querying the objective function is prohibitively expensive or infeasible, with applications spanning protein engineering, material discovery, neural architecture search, and beyond. The main difficulty lies in accurately estimating the objective landscape beyond the available data, where extrapolations are fraught with significant epistemic uncertainty. This uncertainty can lead to objective hacking(reward hacking), exploiting model inaccuracies in unseen regions, or other spurious optimizations that yield misleadingly high performance estimates outside the training distribution. Recent advances in model-based optimization(MBO) have harnessed the generalization capabilities of deep neural networks to develop offline-specific surrogate and generative models. Trained with carefully designed strategies, these models are more robust against out-of-distribution issues, facilitating the discovery of improved designs. Despite its growing impact in accelerating scientific discovery, the field lacks a comprehensive review. To bridge this gap, we present the first thorough review of offline MBO. We begin by formalizing the problem for both single-objective and multi-objective settings and by reviewing recent benchmarks and evaluation metrics. We then categorize existing approaches into two key areas: surrogate modeling, which emphasizes accurate function approximation in out-of-distribution regions, and generative modeling, which explores high-dimensional design spaces to identify high-performing designs. Finally, we examine the key challenges and propose promising directions for advancement in this rapidly evolving field including safe control of superintelligent systems.
Investigating the Impact of Data Selection Strategies on Language Model Performance
Jan 07, 2025Data selection is critical for enhancing the performance of language models, particularly when aligning training datasets with a desired target distribution. This study explores the effects of different data selection methods and feature types on model performance. We evaluate whether selecting data subsets can influence downstream tasks, whether n-gram features improve alignment with target distributions, and whether embedding-based neural features provide complementary benefits. Through comparative experiments using baseline random selection methods and distribution aligned approaches, we provide insights into the interplay between data selection strategies and model training efficacy. All code for this study can be found on \href{https://github.com/jgu13/HIR-Hybrid-Importance-Resampling-for-Language-Models}{github repository}.