 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reference Documents for Zero-Shot Ranking via Large Language Models
Jun 13, 2025Large Language Models (LLMs) have demonstrated exceptional performance in the task of text ranking for information retrieval. While Pointwise ranking approaches offer computational efficiency by scoring documents independently, they often yield biased relevance estimates due to the lack of inter-document comparisons. In contrast, Pairwise methods improve ranking accuracy by explicitly comparing document pairs, but suffer from substantial computational overhead with quadratic complexity ($O(n^2)$). To address this tradeoff, we propose \textbf{RefRank}, a simple and effective comparative ranking method based on a fixed reference document. Instead of comparing all document pairs, RefRank prompts the LLM to evaluate each candidate relative to a shared reference anchor. By selecting the reference anchor that encapsulates the core query intent, RefRank implicitly captures relevance cues, enabling indirect comparison between documents via this common anchor. This reduces computational cost to linear time ($O(n)$) while importantly, preserving the advantages of comparative evaluation. To further enhance robustness, we aggregate multiple RefRank outputs using a weighted averaging scheme across different reference choices. Experiments on several benchmark datasets and with various LLMs show that RefRank significantly outperforms Pointwise baselines and could achieve performance at least on par with Pairwise approaches with a significantly lower computational cost.
Accelerating High-Efficiency Organic Photovoltaic Discovery via Pretrained Graph Neural Networks and Generative Reinforcement Learning
Mar 31, 2025Organic photovoltaic (OPV) materials offer a promising avenue toward cost-effective solar energy utilization. However, optimizing donor-acceptor (D-A) combinations to achieve high power conversion efficiency (PCE) remains a significant challenge. In this work, we propose a framework that integrates large-scale pretraining of graph neural networks (GNNs) with a GPT-2 (Generative Pretrained Transformer 2)-based reinforcement learning (RL) strategy to design OPV molecules with potentially high PCE. This approach produces candidate molecules with predicted efficiencies approaching 21\%, although further experimental validation is required. Moreover, we conducted a preliminary fragment-level analysis to identify structural motifs recognized by the RL model that may contribute to enhanced PCE, thus providing design guidelines for the broader research community. To facilitate continued discovery, we are building the largest open-source OPV dataset to date, expected to include nearly 3,000 donor-acceptor pairs. Finally, we discuss plans to collaborate with experimental teams on synthesizing and characterizing AI-designed molecules, which will provide new data to refine and improve our predictive and generative models.
TransDiffSBDD: Causality-Aware Multi-Modal Structure-Based Drug Design
Mar 26, 2025Structure-based drug design (SBDD) is a critical task in drug discovery, requiring the generation of molecular information across two distinct modalities: discrete molecular graphs and continuous 3D coordinates. However, existing SBDD methods often overlook two key challenges: (1) the multi-modal nature of this task and (2) the causal relationship between these modalities, limiting their plausibility and performance. To address both challenges, we propose TransDiffSBDD, an integrated framework combining autoregressive transformers and diffusion models for SBDD. Specifically, the autoregressive transformer models discrete molecular information, while the diffusion model samples continuous distributions, effectively resolving the first challenge. To address the second challenge, we design a hybrid-modal sequence for protein-ligand complexes that explicitly respects the causality between modalities. Experiments on the CrossDocked2020 benchmark demonstrate that TransDiffSBDD outperforms existing baselines.
3DMolFormer: A Dual-channel Framework for Structure-based Drug Discovery
Feb 07, 2025



Structure-based drug discovery, encompassing the tasks of protein-ligand docking and pocket-aware 3D drug design, represents a core challenge in drug discovery. However, no existing work can deal with both tasks to effectively leverage the duality between them, and current methods for each task are hindered by challenges in modeling 3D information and the limitations of available data. To address these issues, we propose 3DMolFormer, a unified dual-channel transformer-based framework applicable to both docking and 3D drug design tasks, which exploits their duality by utilizing docking functionalities within the drug design process. Specifically, we represent 3D pocket-ligand complexes using parallel sequences of discrete tokens and continuous numbers, and we design a corresponding dual-channel transformer model to handle this format, thereby overcoming the challenges of 3D information modeling. Additionally, we alleviate data limitations through large-scale pre-training on a mixed dataset, followed by supervised and reinforcement learning fine-tuning techniques respectively tailored for the two tasks. Experimental results demonstrate that 3DMolFormer outperforms previous approaches in both protein-ligand docking and pocket-aware 3D drug design, highlighting its promising application in structure-based drug discovery. The code is available at: https://github.com/HXYfighter/3DMolFormer .
When Will Gradient Regularization Be Harmful?
Jun 14, 2024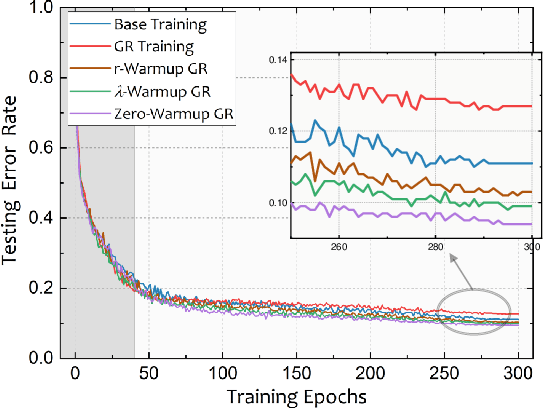

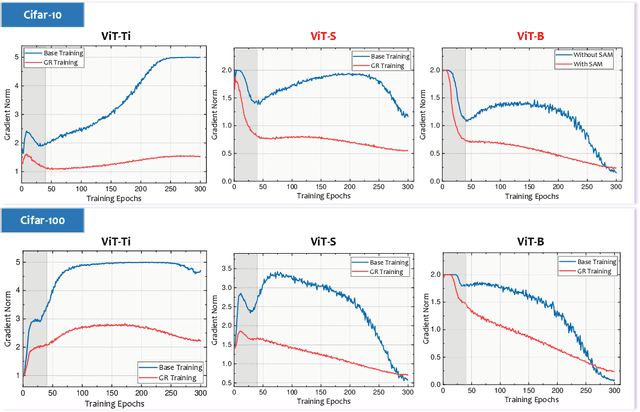
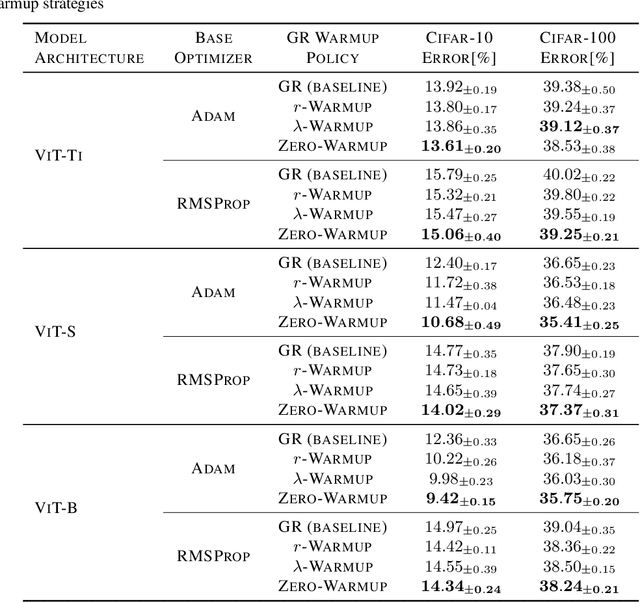
Gradient regularization (GR), which aims to penalize the gradient norm atop the loss function, has shown promising results in training modern over-parameterized deep neural networks. However, can we trust this powerful technique? This paper reveals that GR can cause performance degeneration in adaptive optimization scenarios, particularly with learning rate warmup. Our empirical and theoretical analyses suggest this is due to GR inducing instability and divergence in gradient statistics of adaptive optimizers at the initial training stage. Inspired by the warmup heuristic, we propose three GR warmup strategies, each relaxing the regularization effect to a certain extent during the warmup course to ensure the accurate and stable accumulation of gradients. With experiments on Vision Transformer family, we confirm the three GR warmup strategies can effectively circumvent these issues, thereby largely improving the model performance. Meanwhile, we note that scalable models tend to rely more on the GR warmup, where the performance can be improved by up to 3\% on Cifar10 compared to baseline GR. Code is available at \href{https://github.com/zhaoyang-0204/gnp}{https://github.com/zhaoyang-0204/gnp}.
Empirical Evidence for the Fragment level Understanding on Drug Molecular Structure of LLMs
Jan 15, 2024

AI for drug discovery has been a research hotspot in recent years, and SMILES-based language models has been increasingly applied in drug molecular design. However, no work has explored whether and how language models understand the chemical spatial structure from 1D sequences. In this work, we pre-train a transformer model on chemical language and fine-tune it toward drug design objectives, and investigate the correspondence between high-frequency SMILES substrings and molecular fragments. The results indicate that language models can understand chemical structures from the perspective of molecular fragments, and the structural knowledge learned through fine-tuning is reflected in the high-frequency SMILES substrings generated by the model.
De novo Drug Design using Reinforcement Learning with Multiple GPT Agents
Dec 21, 2023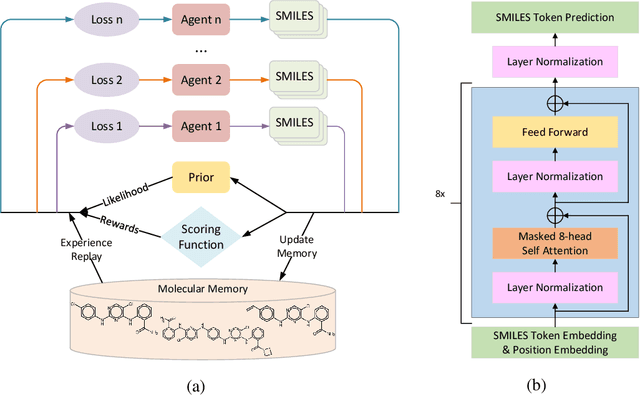
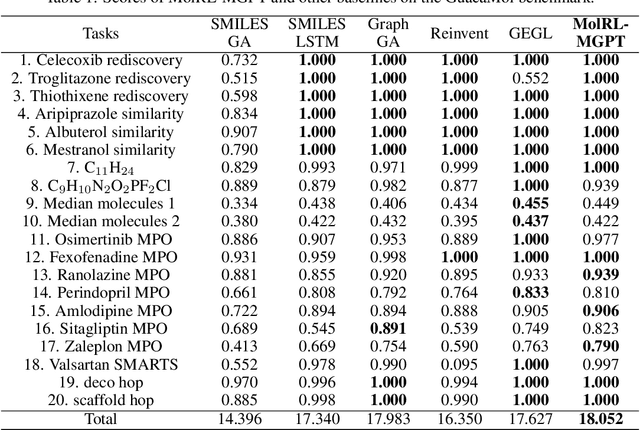
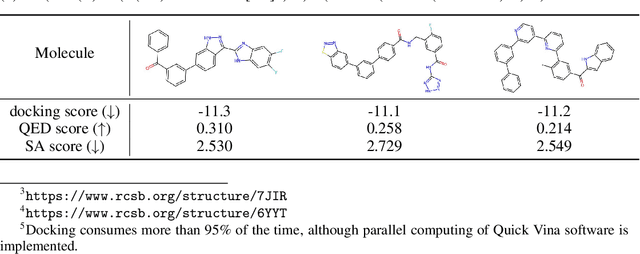
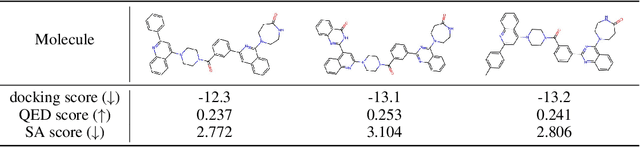
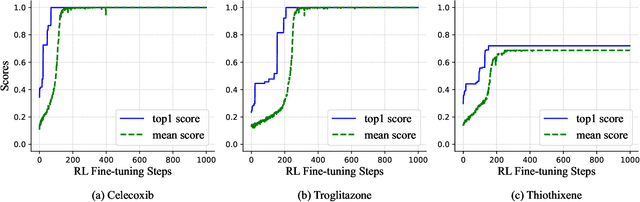
De novo drug design is a pivotal issue in pharmacology and a new area of focus in AI for science research. A central challenge in this field is to generate molecules with specific properties while also producing a wide range of diverse candidates. Although advanced technologies such as transformer models and reinforcement learning have been applied in drug design, their potential has not been fully realized. Therefore, we propose MolRL-MGPT, a reinforcement learning algorithm with multiple GPT agents for drug molecular generation. To promote molecular diversity, we encourage the agents to collaborate in searching for desirable molecules in diverse directions. Our algorithm has shown promising results on the GuacaMol benchmark and exhibits efficacy in designing inhibitors against SARS-CoV-2 protein targets. The codes are available at: https://github.com/HXYfighter/MolRL-MGPT.
SS-SAM : Stochastic Scheduled Sharpness-Aware Minimization for Efficiently Training Deep Neural Networks
Mar 18, 2022
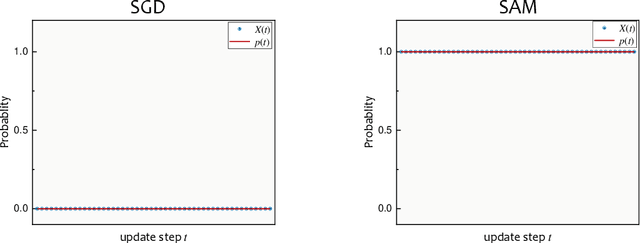

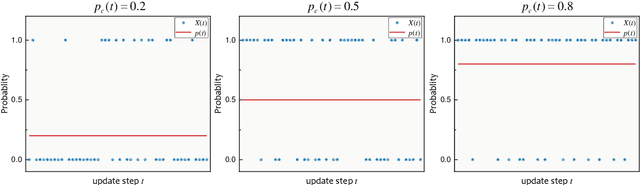
By driving optimizers to converge to flat minima, sharpness-aware minimization (SAM) has shown the power to improve the model generalization. However, SAM requires to perform two forward-backward propagations for one parameter update, which largely burdens the practical computation. In this paper, we propose a novel and efficient training scheme, called Stochastic Scheduled SAM (SS-SAM). Specifically, in SS-SAM, the optimizer is arranged by a predefined scheduling function to perform a random trial at each update step, which would randomly select to perform the SGD optimization or the SAM optimization. In this way, the overall count of propagation pair could be largely reduced. Then, we empirically investigate four typical types of scheduling functions, and demonstrates the computational efficiency and their impact on model performance respectively. We show that with proper scheduling functions, models could be trained to achieve comparable or even better performance with much lower computation cost compared to models trained with only SAM training scheme.
Penalizing Gradient Norm for Efficiently Improving Generalization in Deep Learning
Feb 08, 2022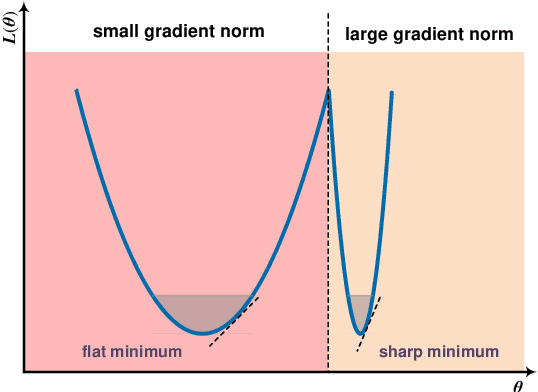
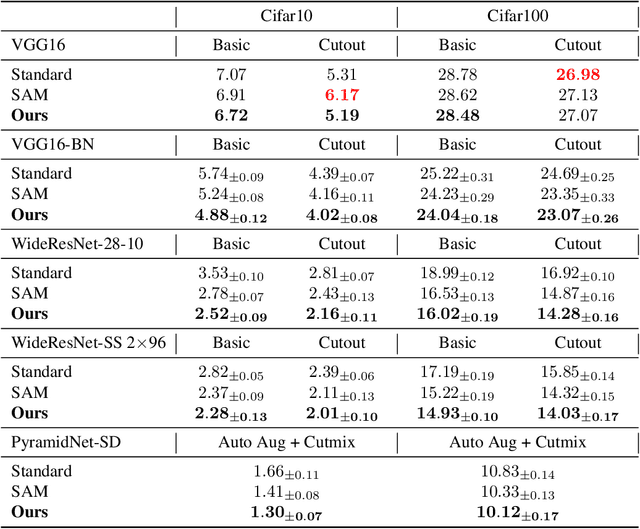
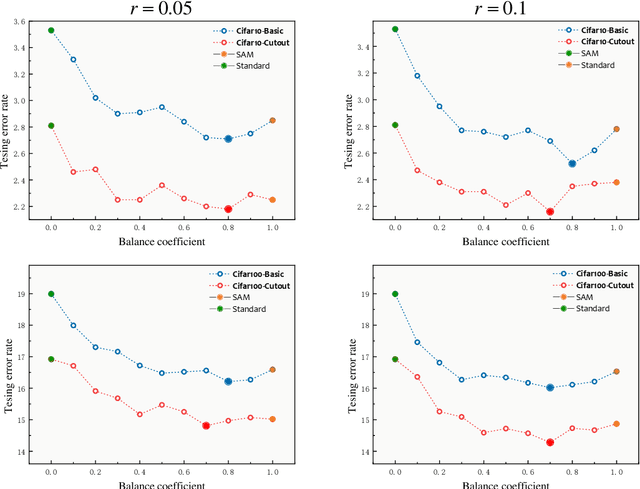
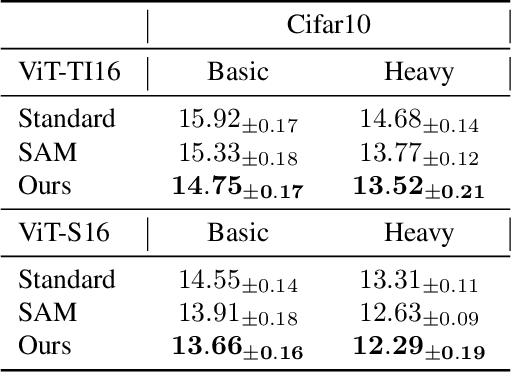
How to train deep neural networks (DNNs) to generalize well is a central concern in deep learning, especially for severely overparameterized networks nowadays. In this paper, we propose an effective method to improve the model generalization by additionally penalizing the gradient norm of loss function during optimization. We demonstrate that confining the gradient norm of loss function could help lead the optimizers towards finding flat minima. We leverage the first-order approximation to efficiently implement the corresponding gradient to fit well in the gradient descent framework. In our experiments, we confirm that when using our methods, generalization performance of various models could be improved on different datasets. Also, we show that the recent sharpness-aware minimization method \cite{DBLP:conf/iclr/ForetKMN21} is a special, but not the best, case of our method, where the best case of our method could give new state-of-art performance on these tasks.