 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
Paper and Code
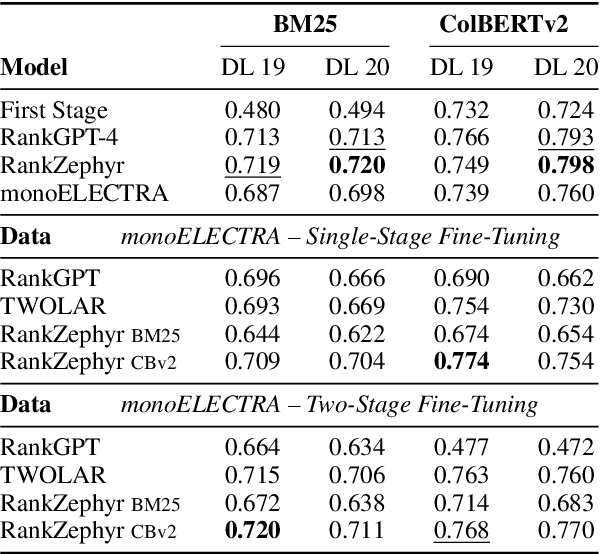
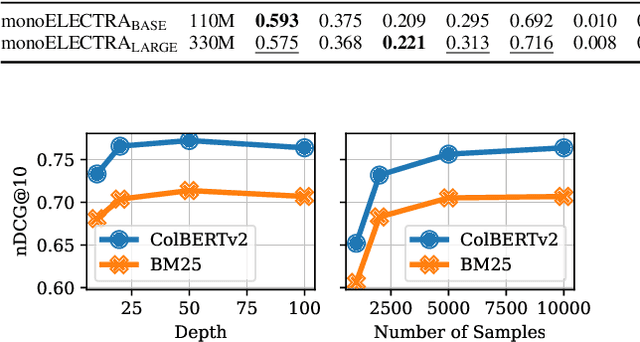
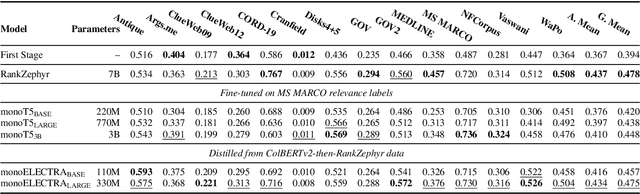
Cross-encoders distilled from large language models are more effective re-rankers than cross-encoders fine-tuned using manually labeled data. However, the distilled models do not reach the language model's effectiveness. We construct and release a new distillation dataset, named Rank-DistiLLM, to investigate whether insights from fine-tuning cross-encoders on manually labeled data -- hard-negative sampling, deep sampling, and listwise loss functions -- are transferable to large language model ranker distillation. Our dataset can be used to train cross-encoders that reach the effectiveness of large language models while being orders of magnitude more efficient. Code and data is available at: https://github.com/webis-de/msmarco-llm-distillation