 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariations in Relevance Judgments and the Shelf Life of Test Collections
Feb 28, 2025The fundamental property of Cranfield-style evaluations, that system rankings are stable even when assessors disagree on individual relevance decisions, was validated on traditional test collections. However, the paradigm shift towards neural retrieval models affected the characteristics of modern test collections, e.g., documents are short, judged with four grades of relevance, and information needs have no descriptions or narratives. Under these changes, it is unclear whether assessor disagreement remains negligible for system comparisons. We investigate this aspect under the additional condition that the few modern test collections are heavily re-used. Given more possible query interpretations due to less formalized information needs, an ''expiration date'' for test collections might be needed if top-effectiveness requires overfitting to a single interpretation of relevance. We run a reproducibility study and re-annotate the relevance judgments of the 2019 TREC Deep Learning track. We can reproduce prior work in the neural retrieval setting, showing that assessor disagreement does not affect system rankings. However, we observe that some models substantially degrade with our new relevance judgments, and some have already reached the effectiveness of humans as rankers, providing evidence that test collections can expire.
Lightning IR: Straightforward Fine-tuning and Inference of Transformer-based Language Models for Information Retrieval
Nov 07, 2024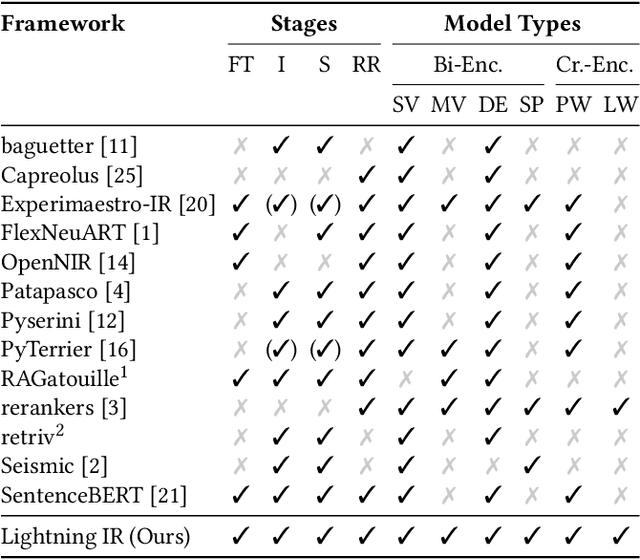

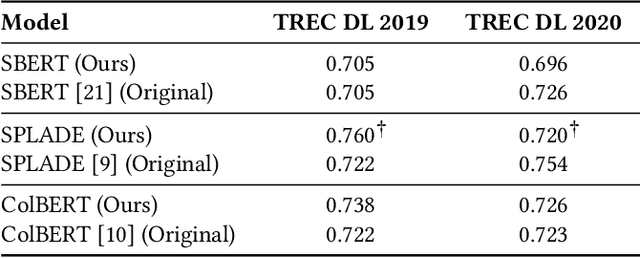
A wide range of transformer-based language models have been proposed for information retrieval tasks. However, fine-tuning and inference of these models is often complex and requires substantial engineering effort. This paper introduces Lightning IR, a PyTorch Lightning-based framework for fine-tuning and inference of transformer-based language models for information retrieval. Lightning IR provides a modular and extensible architecture that supports all stages of an information retrieval pipeline: from fine-tuning and indexing to searching and re-ranking. It is designed to be straightforward to use, scalable, and reproducible. Lightning IR is available as open-source: https://github.com/webis-de/lightning-ir.
A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
May 13, 2024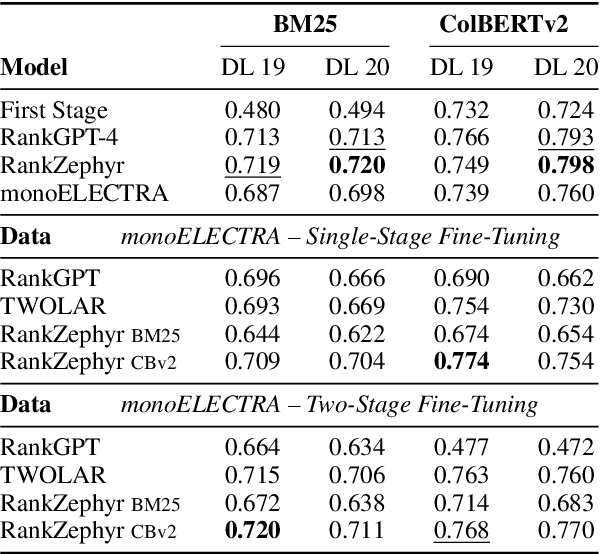
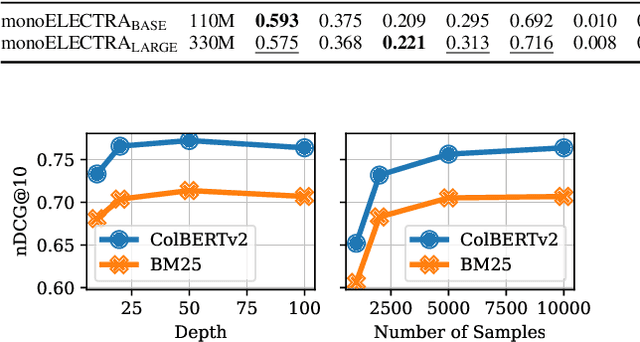
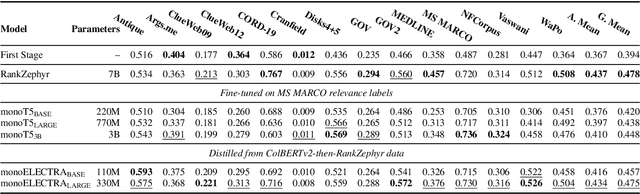
Cross-encoders distilled from large language models are more effective re-rankers than cross-encoders fine-tuned using manually labeled data. However, the distilled models do not reach the language model's effectiveness. We construct and release a new distillation dataset, named Rank-DistiLLM, to investigate whether insights from fine-tuning cross-encoders on manually labeled data -- hard-negative sampling, deep sampling, and listwise loss functions -- are transferable to large language model ranker distillation. Our dataset can be used to train cross-encoders that reach the effectiveness of large language models while being orders of magnitude more efficient. Code and data is available at: https://github.com/webis-de/msmarco-llm-distillation
Set-Encoder: Permutation-Invariant Inter-Passage Attention for Listwise Passage Re-Ranking with Cross-Encoders
Apr 11, 2024Cross-encoders are effective passage re-rankers. But when re-ranking multiple passages at once, existing cross-encoders inefficiently optimize the output ranking over several input permutations, as their passage interactions are not permutation-invariant. Moreover, their high memory footprint constrains the number of passages during listwise training. To tackle these issues, we propose the Set-Encoder, a new cross-encoder architecture that (1) introduces inter-passage attention with parallel passage processing to ensure permutation invariance between input passages, and that (2) uses fused-attention kernels to enable training with more passages at a time. In experiments on TREC Deep Learning and TIREx, the Set-Encoder is more effective than previous cross-encoders with a similar number of parameters. Compared to larger models, the Set-Encoder is more efficient and either on par or even more effective.
Investigating the Effects of Sparse Attention on Cross-Encoders
Dec 29, 2023Cross-encoders are effective passage and document re-rankers but less efficient than other neural or classic retrieval models. A few previous studies have applied windowed self-attention to make cross-encoders more efficient. However, these studies did not investigate the potential and limits of different attention patterns or window sizes. We close this gap and systematically analyze how token interactions can be reduced without harming the re-ranking effectiveness. Experimenting with asymmetric attention and different window sizes, we find that the query tokens do not need to attend to the passage or document tokens for effective re-ranking and that very small window sizes suffice. In our experiments, even windows of 4 tokens still yield effectiveness on par with previous cross-encoders while reducing the memory requirements to at most 78% / 41% and being 1% / 43% faster at inference time for passages / documents.