 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning With Individualized Privacy Through Client Sampling
Jan 29, 2025With growing concerns about user data collection, individualized privacy has emerged as a promising solution to balance protection and utility by accounting for diverse user privacy preferences. Instead of enforcing a uniform level of anonymization for all users, this approach allows individuals to choose privacy settings that align with their comfort levels. Building on this idea, we propose an adapted method for enabling Individualized Differential Privacy (IDP) in Federated Learning (FL) by handling clients according to their personal privacy preferences. By extending the SAMPLE algorithm from centralized settings to FL, we calculate client-specific sampling rates based on their heterogeneous privacy budgets and integrate them into a modified IDP-FedAvg algorithm. We test this method under realistic privacy distributions and multiple datasets. The experimental results demonstrate that our approach achieves clear improvements over uniform DP baselines, reducing the trade-off between privacy and utility. Compared to the alternative SCALE method in related work, which assigns differing noise scales to clients, our method performs notably better. However, challenges remain for complex tasks with non-i.i.d. data, primarily stemming from the constraints of the decentralized setting.
Trigger Warnings: Bootstrapping a Violence Detector for FanFiction
Sep 09, 2022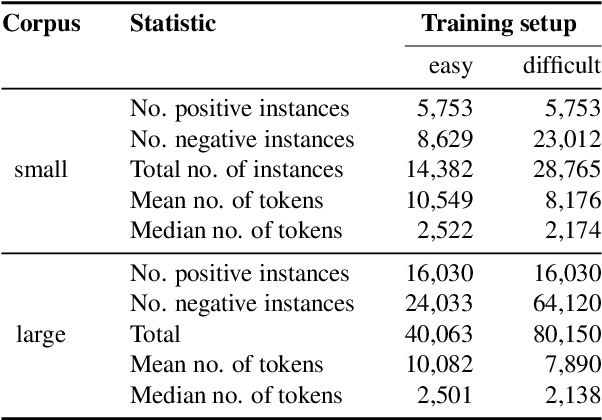

We present the first dataset and evaluation results on a newly defined computational task of trigger warning assignment. Labeled corpus data has been compiled from narrative works hosted on Archive of Our Own (AO3), a well-known fanfiction site. In this paper, we focus on the most frequently assigned trigger type--violence--and define a document-level binary classification task of whether or not to assign a violence trigger warning to a fanfiction, exploiting warning labels provided by AO3 authors. SVM and BERT models trained in four evaluation setups on the corpora we compiled yield $F_1$ results ranging from 0.585 to 0.798, proving the violence trigger warning assignment to be a doable, however, non-trivial task.