 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Pipelines for Data Integration into Knowledge Graphs
May 21, 2026Integrating new data into knowledge graphs (KG) typically involves different tasks that are executed within workflows or pipelines There are many possible pipelines for a specific integration problem but there is not yet a general approach to evaluate the overall quality and performance of such pipelines to be able to determine the best choices. We therefore propose a new benchmark KGI-Bench to evaluate integration pipelines that ingest different kinds of input data into an existing KG. We evaluate pipelines by analyzing their output, i.e., the updated KG, with the three complementary quality metrics coverage, correctness and consistency. We also provide benchmark datasets (seed KG, overlapping input data of three formats, reference KG as a ground truth) for the movie domain. To demonstrate the applicability and usefulness of the proposed benchmark, we comparatively evaluate 12 pipelines and analyze their behavior across different input data formats and design choices.
PiGRAND: Physics-informed Graph Neural Diffusion for Intelligent Additive Manufacturing
Mar 16, 2026A comprehensive understanding of heat transport is essential for optimizing various mechanical and engineering applications, including 3D printing. Recent advances in machine learning, combined with physics-based models, have enabled a powerful fusion of numerical methods and data-driven algorithms. This progress is driven by the availability of limited sensor data in various engineering and scientific domains, where the cost of data collection and the inaccessibility of certain measurements are high. To this end, we present PiGRAND, a Physics-informed graph neural diffusion framework. In order to reduce the computational complexity of graph learning, an efficient graph construction procedure was developed. Our approach is inspired by the explicit Euler and implicit Crank-Nicolson methods for modeling continuous heat transport, leveraging sub-learning models to secure the accurate diffusion across graph nodes. To enhance computational performance, our approach is combined with efficient transfer learning. We evaluate PiGRAND on thermal images from 3D printing, demonstrating significant improvements in prediction accuracy and computational performance compared to traditional graph neural diffusion (GRAND) and physics-informed neural networks (PINNs). These enhancements are attributed to the incorporation of physical principles derived from the theoretical study of partial differential equations (PDEs) into the learning model. The PiGRAND code is open-sourced on GitHub: https://github.com/bu32loxa/PiGRAND
Learning from Anonymized and Incomplete Tabular Data
Feb 01, 2026User-driven privacy allows individuals to control whether and at what granularity their data is shared, leading to datasets that mix original, generalized, and missing values within the same records and attributes. While such representations are intuitive for privacy, they pose challenges for machine learning, which typically treats non-original values as new categories or as missing, thereby discarding generalization semantics. For learning from such tabular data, we propose novel data transformation strategies that account for heterogeneous anonymization and evaluate them alongside standard imputation and LLM-based approaches. We employ multiple datasets, privacy configurations, and deployment scenarios, demonstrating that our method reliably regains utility. Our results show that generalized values are preferable to pure suppression, that the best data preparation strategy depends on the scenario, and that consistent data representations are crucial for maintaining downstream utility. Overall, our findings highlight that effective learning is tied to the appropriate handling of anonymized values.
Federated Learning With Individualized Privacy Through Client Sampling
Jan 29, 2025

With growing concerns about user data collection, individualized privacy has emerged as a promising solution to balance protection and utility by accounting for diverse user privacy preferences. Instead of enforcing a uniform level of anonymization for all users, this approach allows individuals to choose privacy settings that align with their comfort levels. Building on this idea, we propose an adapted method for enabling Individualized Differential Privacy (IDP) in Federated Learning (FL) by handling clients according to their personal privacy preferences. By extending the SAMPLE algorithm from centralized settings to FL, we calculate client-specific sampling rates based on their heterogeneous privacy budgets and integrate them into a modified IDP-FedAvg algorithm. We test this method under realistic privacy distributions and multiple datasets. The experimental results demonstrate that our approach achieves clear improvements over uniform DP baselines, reducing the trade-off between privacy and utility. Compared to the alternative SCALE method in related work, which assigns differing noise scales to clients, our method performs notably better. However, challenges remain for complex tasks with non-i.i.d. data, primarily stemming from the constraints of the decentralized setting.
Multi-Layer Privacy-Preserving Record Linkage with Clerical Review based on gradual information disclosure
Dec 05, 2024



Privacy-Preserving Record linkage (PPRL) is an essential component in data integration tasks of sensitive information. The linkage quality determines the usability of combined datasets and (machine learning) applications based on them. We present a novel privacy-preserving protocol that integrates clerical review in PPRL using a multi-layer active learning process. Uncertain match candidates are reviewed on several layers by human and non-human oracles to reduce the amount of disclosed information per record and in total. Predictions are propagated back to update previous layers, resulting in an improved linkage performance for non-reviewed candidates as well. The data owners remain in control of the amount of information they share for each record. Therefore, our approach follows need-to-know and data sovereignty principles. The experimental evaluation on real-world datasets shows considerable linkage quality improvements with limited labeling effort and privacy risks.
Assessing the Impact of Image Dataset Features on Privacy-Preserving Machine Learning
Sep 02, 2024



Machine Learning (ML) is crucial in many sectors, including computer vision. However, ML models trained on sensitive data face security challenges, as they can be attacked and leak information. Privacy-Preserving Machine Learning (PPML) addresses this by using Differential Privacy (DP) to balance utility and privacy. This study identifies image dataset characteristics that affect the utility and vulnerability of private and non-private Convolutional Neural Network (CNN) models. Through analyzing multiple datasets and privacy budgets, we find that imbalanced datasets increase vulnerability in minority classes, but DP mitigates this issue. Datasets with fewer classes improve both model utility and privacy, while high entropy or low Fisher Discriminant Ratio (FDR) datasets deteriorate the utility-privacy trade-off. These insights offer valuable guidance for practitioners and researchers in estimating and optimizing the utility-privacy trade-off in image datasets, helping to inform data and privacy modifications for better outcomes based on dataset characteristics.
Graph-based Active Learning for Entity Cluster Repair
Jan 26, 2024



Cluster repair methods aim to determine errors in clusters and modify them so that each cluster consists of records representing the same entity. Current cluster repair methodologies primarily assume duplicate-free data sources, where each record from one source corresponds to a unique record from another. However, real-world data often deviates from this assumption due to quality issues. Recent approaches apply clustering methods in combination with link categorization methods so they can be applied to data sources with duplicates. Nevertheless, the results do not show a clear picture since the quality highly varies depending on the configuration and dataset. In this study, we introduce a novel approach for cluster repair that utilizes graph metrics derived from the underlying similarity graphs. These metrics are pivotal in constructing a classification model to distinguish between correct and incorrect edges. To address the challenge of limited training data, we integrate an active learning mechanism tailored to cluster-specific attributes. The evaluation shows that the method outperforms existing cluster repair methods without distinguishing between duplicate-free or dirty data sources. Notably, our modified active learning strategy exhibits enhanced performance when dealing with datasets containing duplicates, showcasing its effectiveness in such scenarios.
Generating Synthetic Health Sensor Data for Privacy-Preserving Wearable Stress Detection
Jan 24, 2024
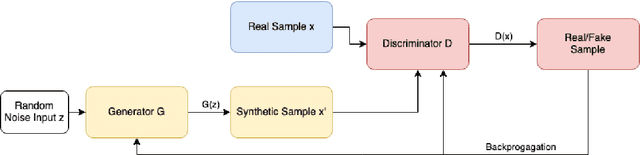
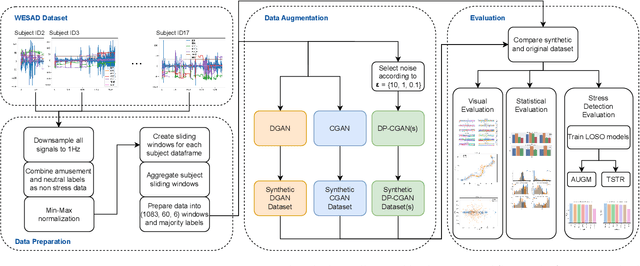

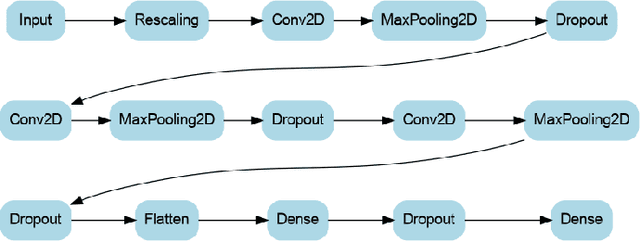
Smartwatch health sensor data is increasingly utilized in smart health applications and patient monitoring, including stress detection. However, such medical data often comprises sensitive personal information and is resource-intensive to acquire for research purposes. In response to this challenge, we introduce the privacy-aware synthetization of multi-sensor smartwatch health readings related to moments of stress. Our method involves the generation of synthetic sequence data through Generative Adversarial Networks (GANs), coupled with the implementation of Differential Privacy (DP) safeguards for protecting patient information during model training. To ensure the integrity of our synthetic data, we employ a range of quality assessments and monitor the plausibility between synthetic and original data. To test the usefulness, we create private machine learning models on a commonly used, albeit small, stress detection dataset, exploring strategies for enhancing the existing data foundation with our synthetic data. Through our GAN-based augmentation methods, we observe improvements in model performance, both in non-private (0.45% F1) and private (11.90-15.48% F1) training scenarios. We underline the potential of differentially private synthetic data in optimizing utility-privacy trade-offs, especially with limited availability of real training samples.
Construction of Knowledge Graphs: State and Challenges
Feb 22, 2023



With knowledge graphs (KGs) at the center of numerous applications such as recommender systems and question answering, the need for generalized pipelines to construct and continuously update such KGs is increasing. While the individual steps that are necessary to create KGs from unstructured (e.g. text) and structured data sources (e.g. databases) are mostly well-researched for their one-shot execution, their adoption for incremental KG updates and the interplay of the individual steps have hardly been investigated in a systematic manner so far. In this work, we first discuss the main graph models for KGs and introduce the major requirement for future KG construction pipelines. Next, we provide an overview of the necessary steps to build high-quality KGs, including cross-cutting topics such as metadata management, ontology development, and quality assurance. We then evaluate the state of the art of KG construction w.r.t the introduced requirements for specific popular KGs as well as some recent tools and strategies for KG construction. Finally, we identify areas in need of further research and improvement.
Privacy in Practice: Private COVID-19 Detection in X-Ray Images
Nov 21, 2022



Machine learning (ML) can help fight the COVID-19 pandemic by enabling rapid screening of large volumes of chest X-ray images. To perform such data analysis while maintaining patient privacy, we create ML models that satisfy Differential Privacy (DP). Previous works exploring private COVID-19 ML models are in part based on small or skewed datasets, are lacking in their privacy guarantees, and do not investigate practical privacy. In this work, we therefore suggest several improvements to address these open gaps. We account for inherent class imbalances in the data and evaluate the utility-privacy trade-off more extensively and over stricter privacy budgets than in previous work. Our evaluation is supported by empirically estimating practical privacy leakage through actual attacks. Based on theory, the introduced DP should help limit and mitigate information leakage threats posed by black-box Membership Inference Attacks (MIAs). Our practical privacy analysis is the first to test this hypothesis on the COVID-19 detection task. In addition, we also re-examine the evaluation on the MNIST database. Our results indicate that based on the task-dependent threat from MIAs, DP does not always improve practical privacy, which we show on the COVID-19 task. The results further suggest that with increasing DP guarantees, empirical privacy leakage reaches an early plateau and DP therefore appears to have a limited impact on MIA defense. Our findings identify possibilities for better utility-privacy trade-offs, and we thus believe that empirical attack-specific privacy estimation can play a vital role in tuning for practical privacy.