 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErGAN: Generative Adversarial Networks for Entity Resolution
Dec 18, 2020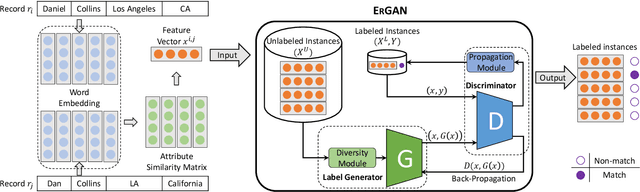
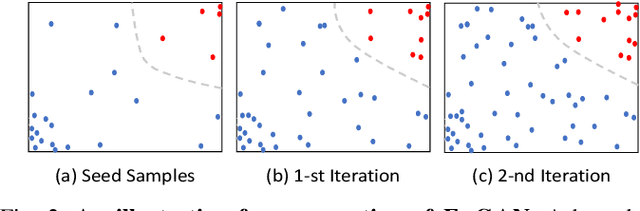
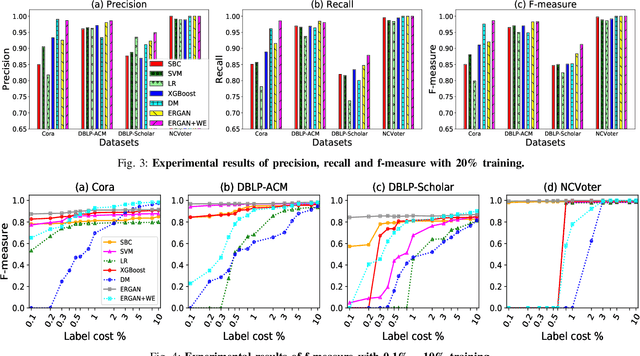
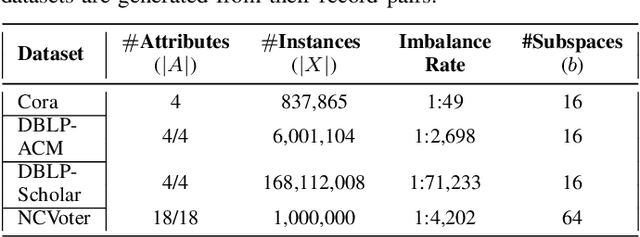
Entity resolution targets at identifying records that represent the same real-world entity from one or more datasets. A major challenge in learning-based entity resolution is how to reduce the label cost for training. Due to the quadratic nature of record pair comparison, labeling is a costly task that often requires a significant effort from human experts. Inspired by recent advances of generative adversarial network (GAN), we propose a novel deep learning method, called ErGAN, to address the challenge. ErGAN consists of two key components: a label generator and a discriminator which are optimized alternatively through adversarial learning. To alleviate the issues of overfitting and highly imbalanced distribution, we design two novel modules for diversity and propagation, which can greatly improve the model generalization power. We have conducted extensive experiments to empirically verify the labeling and learning efficiency of ErGAN. The experimental results show that ErGAN beats the state-of-the-art baselines, including unsupervised, semi-supervised, and unsupervised learning methods.
Learning to Sample: an Active Learning Framework
Sep 09, 2019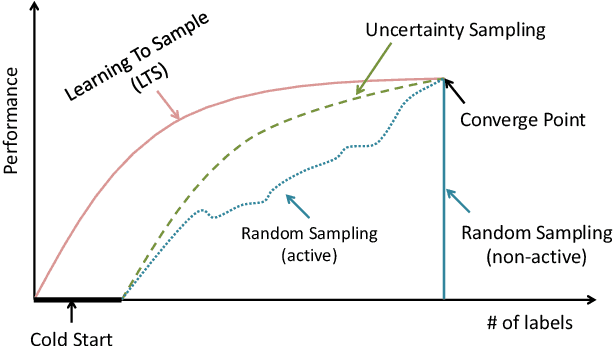
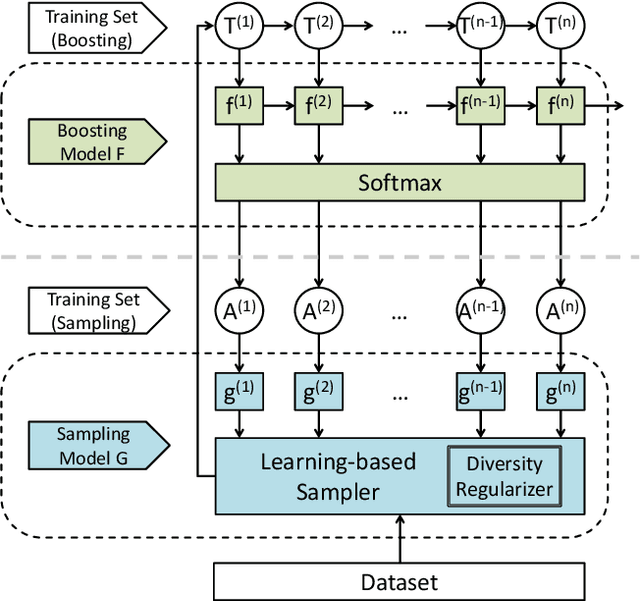

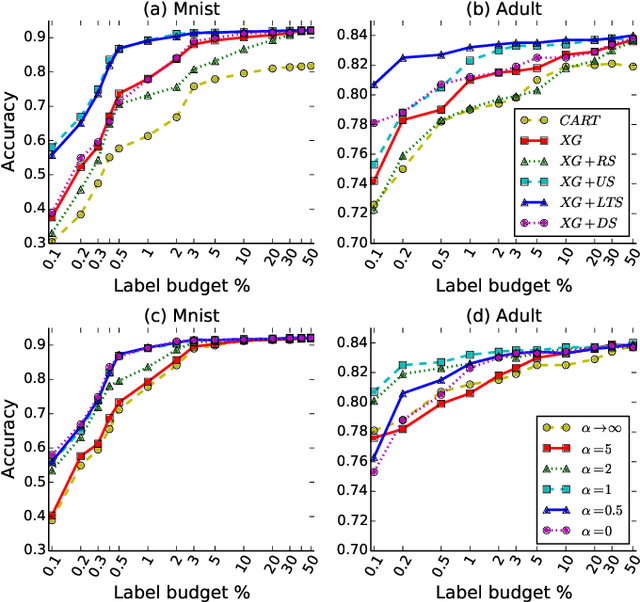
Meta-learning algorithms for active learning are emerging as a promising paradigm for learning the ``best'' active learning strategy. However, current learning-based active learning approaches still require sufficient training data so as to generalize meta-learning models for active learning. This is contrary to the nature of active learning which typically starts with a small number of labeled samples. The unavailability of large amounts of labeled samples for training meta-learning models would inevitably lead to poor performance (e.g., instabilities and overfitting). In our paper, we tackle these issues by proposing a novel learning-based active learning framework, called Learning To Sample (LTS). This framework has two key components: a sampling model and a boosting model, which can mutually learn from each other in iterations to improve the performance of each other. Within this framework, the sampling model incorporates uncertainty sampling and diversity sampling into a unified process for optimization, enabling us to actively select the most representative and informative samples based on an optimized integration of uncertainty and diversity. To evaluate the effectiveness of the LTS framework, we have conducted extensive experiments on three different classification tasks: image classification, salary level prediction, and entity resolution. The experimental results show that our LTS framework significantly outperforms all the baselines when the label budget is limited, especially for datasets with highly imbalanced classes. In addition to this, our LTS framework can effectively tackle the cold start problem occurring in many existing active learning approaches.
Depth from a Single Image by Harmonizing Overcomplete Local Network Predictions
Sep 07, 2016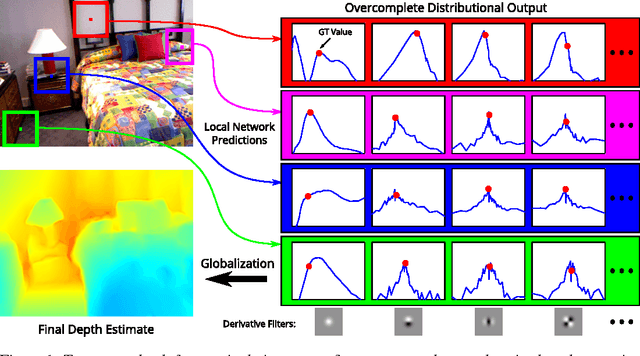
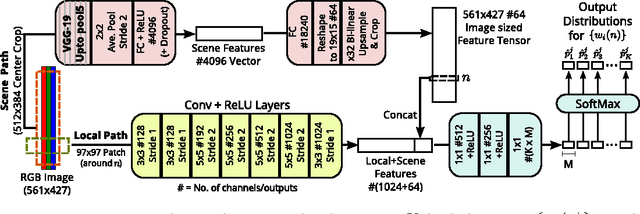
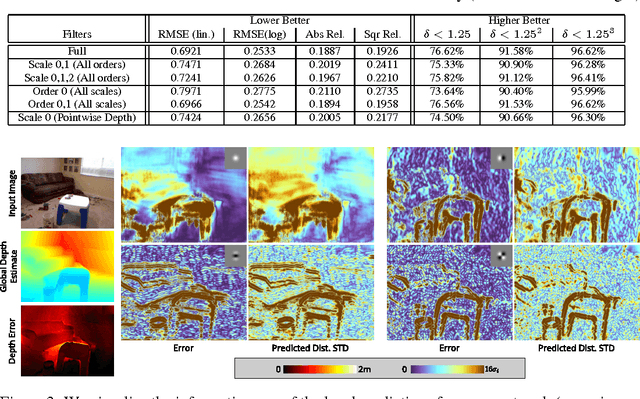
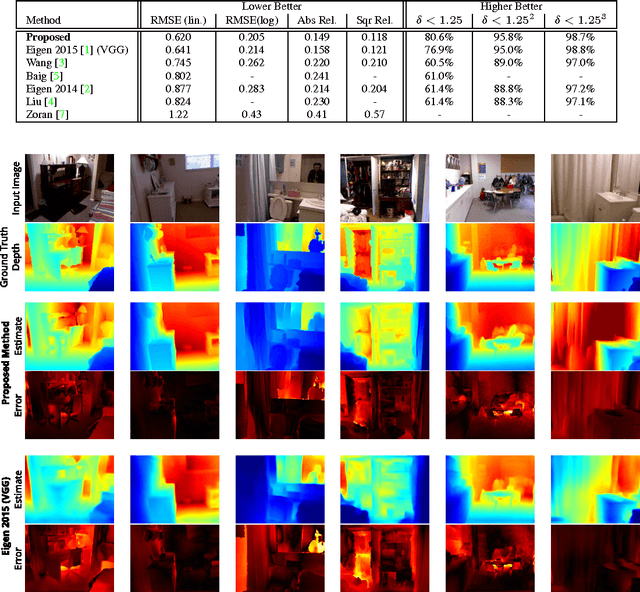
A single color image can contain many cues informative towards different aspects of local geometric structure. We approach the problem of monocular depth estimation by using a neural network to produce a mid-level representation that summarizes these cues. This network is trained to characterize local scene geometry by predicting, at every image location, depth derivatives of different orders, orientations and scales. However, instead of a single estimate for each derivative, the network outputs probability distributions that allow it to express confidence about some coefficients, and ambiguity about others. Scene depth is then estimated by harmonizing this overcomplete set of network predictions, using a globalization procedure that finds a single consistent depth map that best matches all the local derivative distributions. We demonstrate the efficacy of this approach through evaluation on the NYU v2 depth data set.