 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Learning for Spectral Graph Neural Networks
Dec 16, 2024Optimizing spectral graph neural networks (GNNs) remains a critical challenge in the field, yet the underlying processes are not well understood. In this paper, we investigate the inherent differences between graph convolution parameters and feature transformation parameters in spectral GNNs and their impact on the optimization landscape. Our analysis reveals that these differences contribute to a poorly conditioned problem, resulting in suboptimal performance. To address this issue, we introduce the concept of the block condition number of the Hessian matrix, which characterizes the difficulty of poorly conditioned problems in spectral GNN optimization. We then propose an asymmetric learning approach, dynamically preconditioning gradients during training to alleviate poorly conditioned problems. Theoretically, we demonstrate that asymmetric learning can reduce block condition numbers, facilitating easier optimization. Extensive experiments on eighteen benchmark datasets show that asymmetric learning consistently improves the performance of spectral GNNs for both heterophilic and homophilic graphs. This improvement is especially notable for heterophilic graphs, where the optimization process is generally more complex than for homophilic graphs. Code is available at https://github.com/Mia-321/asym-opt.git.
Episode Adaptive Embedding Networks for Few-shot Learning
Jun 17, 2021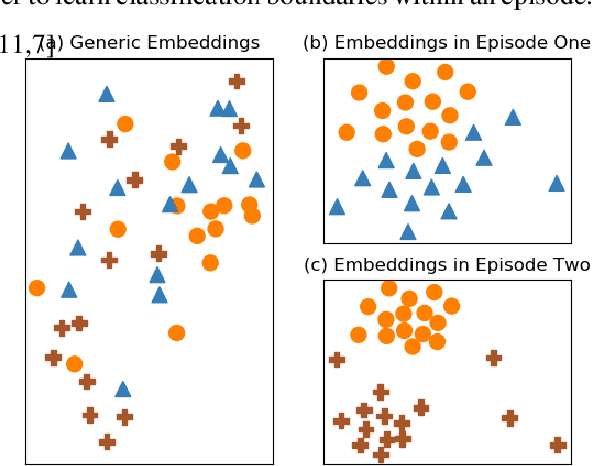
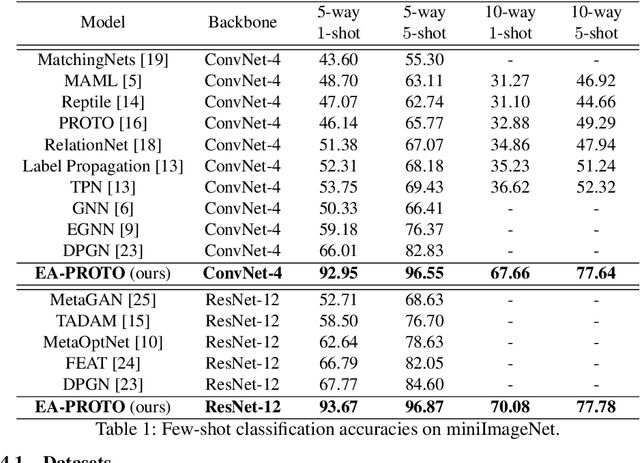
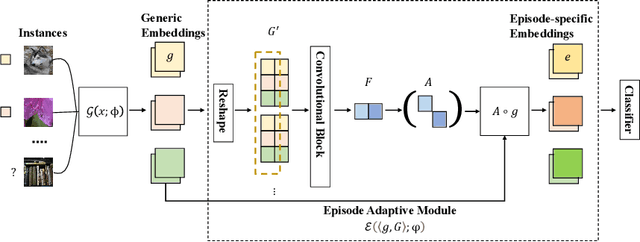
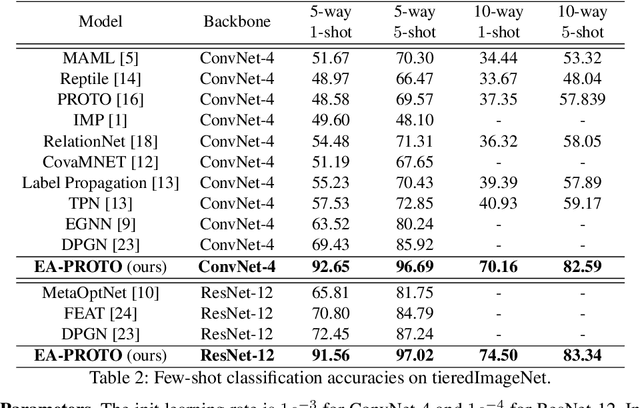
Few-shot learning aims to learn a classifier using a few labelled instances for each class. Metric-learning approaches for few-shot learning embed instances into a high-dimensional space and conduct classification based on distances among instance embeddings. However, such instance embeddings are usually shared across all episodes and thus lack the discriminative power to generalize classifiers according to episode-specific features. In this paper, we propose a novel approach, namely \emph{Episode Adaptive Embedding Network} (EAEN), to learn episode-specific embeddings of instances. By leveraging the probability distributions of all instances in an episode at each channel-pixel embedding dimension, EAEN can not only alleviate the overfitting issue encountered in few-shot learning tasks, but also capture discriminative features specific to an episode. To empirically verify the effectiveness and robustness of EAEN, we have conducted extensive experiments on three widely used benchmark datasets, under various combinations of different generic embedding backbones and different classifiers. The results show that EAEN significantly improves classification accuracy about $10\%$ to $20\%$ in different settings over the state-of-the-art methods.
Learning to Sample: an Active Learning Framework
Sep 09, 2019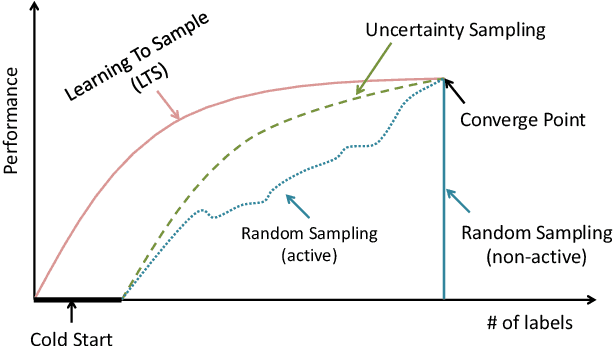
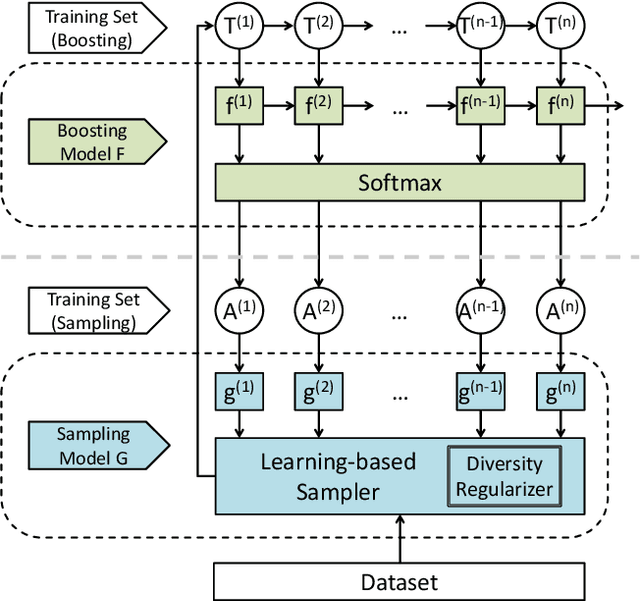

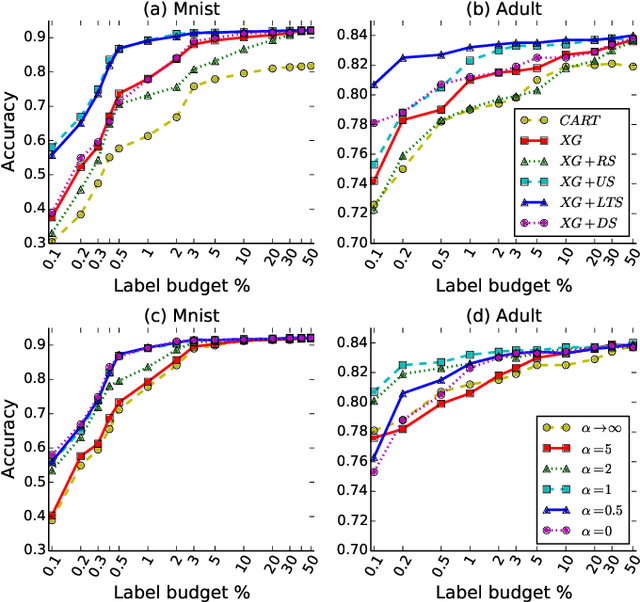
Meta-learning algorithms for active learning are emerging as a promising paradigm for learning the ``best'' active learning strategy. However, current learning-based active learning approaches still require sufficient training data so as to generalize meta-learning models for active learning. This is contrary to the nature of active learning which typically starts with a small number of labeled samples. The unavailability of large amounts of labeled samples for training meta-learning models would inevitably lead to poor performance (e.g., instabilities and overfitting). In our paper, we tackle these issues by proposing a novel learning-based active learning framework, called Learning To Sample (LTS). This framework has two key components: a sampling model and a boosting model, which can mutually learn from each other in iterations to improve the performance of each other. Within this framework, the sampling model incorporates uncertainty sampling and diversity sampling into a unified process for optimization, enabling us to actively select the most representative and informative samples based on an optimized integration of uncertainty and diversity. To evaluate the effectiveness of the LTS framework, we have conducted extensive experiments on three different classification tasks: image classification, salary level prediction, and entity resolution. The experimental results show that our LTS framework significantly outperforms all the baselines when the label budget is limited, especially for datasets with highly imbalanced classes. In addition to this, our LTS framework can effectively tackle the cold start problem occurring in many existing active learning approaches.