 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Active Learning for Entity Cluster Repair
Jan 26, 2024



Cluster repair methods aim to determine errors in clusters and modify them so that each cluster consists of records representing the same entity. Current cluster repair methodologies primarily assume duplicate-free data sources, where each record from one source corresponds to a unique record from another. However, real-world data often deviates from this assumption due to quality issues. Recent approaches apply clustering methods in combination with link categorization methods so they can be applied to data sources with duplicates. Nevertheless, the results do not show a clear picture since the quality highly varies depending on the configuration and dataset. In this study, we introduce a novel approach for cluster repair that utilizes graph metrics derived from the underlying similarity graphs. These metrics are pivotal in constructing a classification model to distinguish between correct and incorrect edges. To address the challenge of limited training data, we integrate an active learning mechanism tailored to cluster-specific attributes. The evaluation shows that the method outperforms existing cluster repair methods without distinguishing between duplicate-free or dirty data sources. Notably, our modified active learning strategy exhibits enhanced performance when dealing with datasets containing duplicates, showcasing its effectiveness in such scenarios.
Construction of Knowledge Graphs: State and Challenges
Feb 22, 2023With knowledge graphs (KGs) at the center of numerous applications such as recommender systems and question answering, the need for generalized pipelines to construct and continuously update such KGs is increasing. While the individual steps that are necessary to create KGs from unstructured (e.g. text) and structured data sources (e.g. databases) are mostly well-researched for their one-shot execution, their adoption for incremental KG updates and the interplay of the individual steps have hardly been investigated in a systematic manner so far. In this work, we first discuss the main graph models for KGs and introduce the major requirement for future KG construction pipelines. Next, we provide an overview of the necessary steps to build high-quality KGs, including cross-cutting topics such as metadata management, ontology development, and quality assurance. We then evaluate the state of the art of KG construction w.r.t the introduced requirements for specific popular KGs as well as some recent tools and strategies for KG construction. Finally, we identify areas in need of further research and improvement.
EAGER: Embedding-Assisted Entity Resolution for Knowledge Graphs
Jan 15, 2021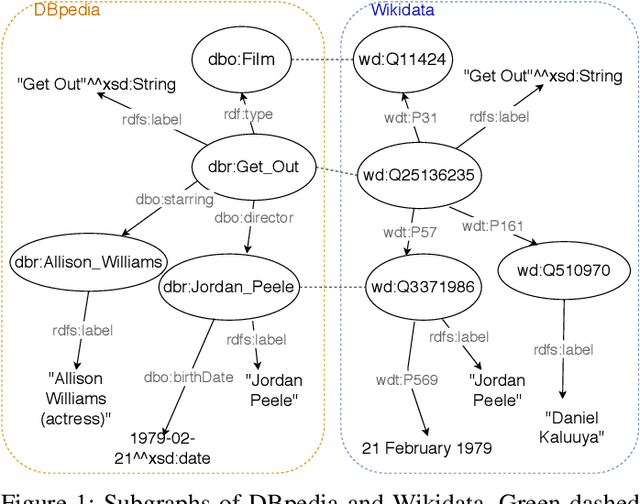
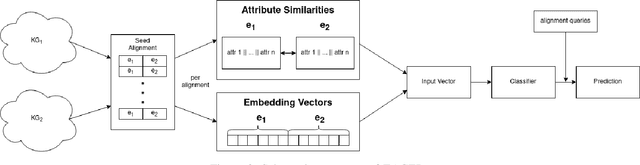
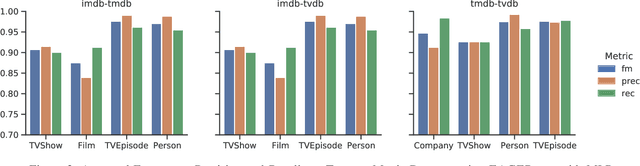
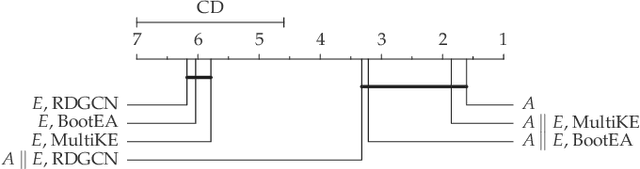
Entity Resolution (ER) is a constitutional part for integrating different knowledge graphs in order to identify entities referring to the same real-world object. A promising approach is the use of graph embeddings for ER in order to determine the similarity of entities based on the similarity of their graph neighborhood. The similarity computations for such embeddings translates to calculating the distance between them in the embedding space which is comparatively simple. However, previous work has shown that the use of graph embeddings alone is not sufficient to achieve high ER quality. We therefore propose a more comprehensive ER approach for knowledge graphs called EAGER (Embedding-Assisted Knowledge Graph Entity Resolution) to flexibly utilize both the similarity of graph embeddings and attribute values within a supervised machine learning approach. We evaluate our approach on 23 benchmark datasets with differently sized and structured knowledge graphs and use hypothesis tests to ensure statistical significance of our results. Furthermore we compare our approach with state-of-the-art ER solutions, where our approach yields competitive results for table-oriented ER problems and shallow knowledge graphs but much better results for deeper knowledge graphs.