 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAPME: Learning-based Property Matching with Embeddings
Oct 05, 2020

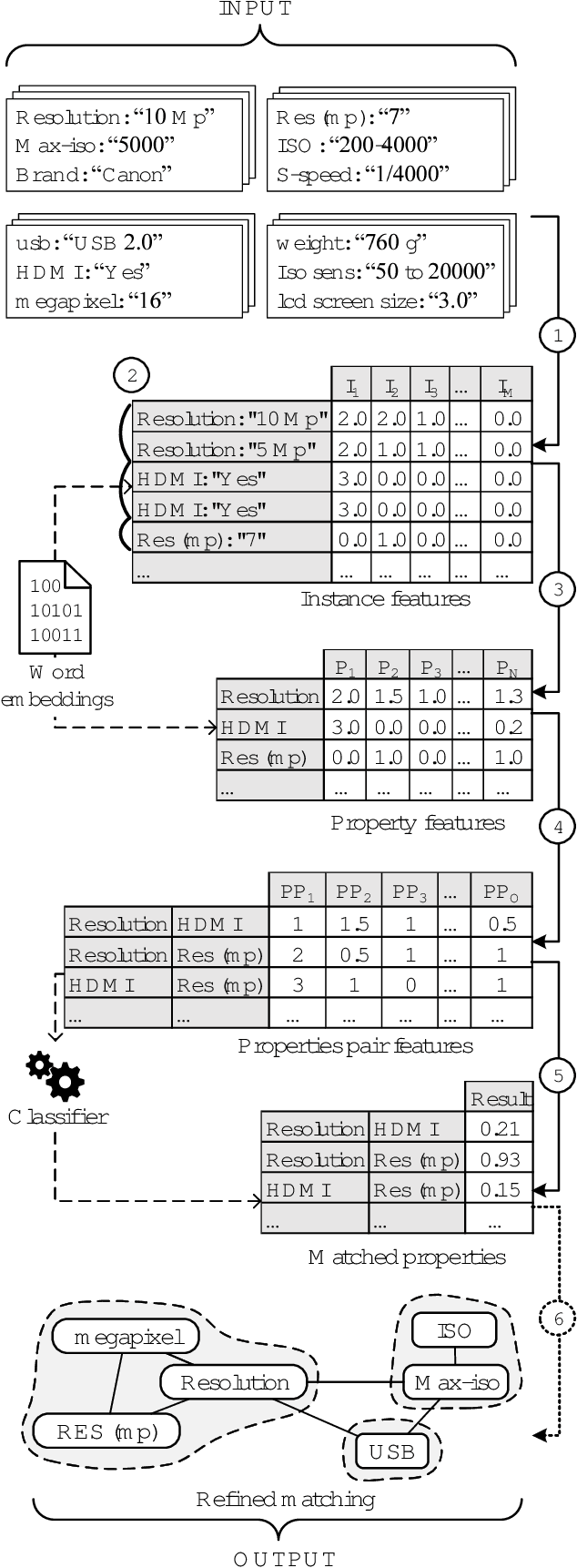

Data integration tasks such as the creation and extension of knowledge graphs involve the fusion of heterogeneous entities from many sources. Matching and fusion of such entities require to also match and combine their properties (attributes). However, previous schema matching approaches mostly focus on two sources only and often rely on simple similarity measurements. They thus face problems in challenging use cases such as the integration of heterogeneous product entities from many sources. We therefore present a new machine learning-based property matching approach called LEAPME (LEArning-based Property Matching with Embeddings) that utilizes numerous features of both property names and instance values. The approach heavily makes use of word embeddings to better utilize the domain-specific semantics of both property names and instance values. The use of supervised machine learning helps exploit the predictive power of word embeddings. Our comparative evaluation against five baselines for several multi-source datasets with real-world data shows the high effectiveness of LEAPME. We also show that our approach is even effective when training data from another domain (transfer learning) is used.