 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStegaINR4MIH: steganography by implicit neural representation for multi-image hiding
Oct 14, 2024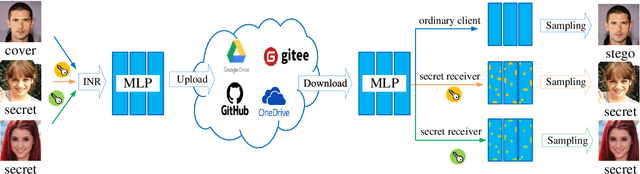

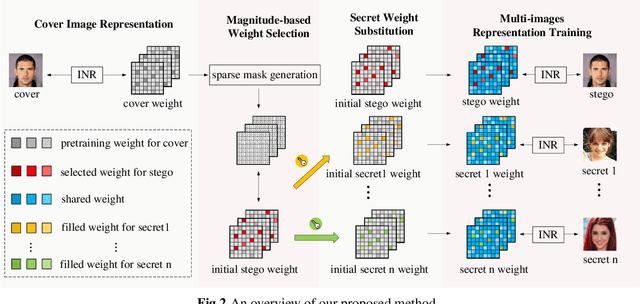
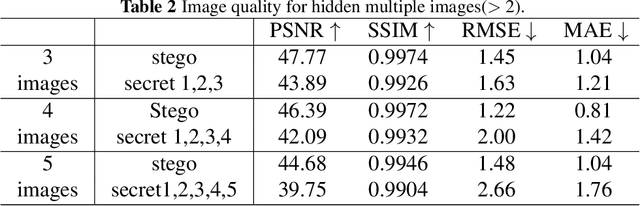
Multi-image hiding, which embeds multiple secret images into a cover image and is able to recover these images with high quality, has gradually become a research hotspot in the field of image steganography. However, due to the need to embed a large amount of data in a limited cover image space, issues such as contour shadowing or color distortion often arise, posing significant challenges for multi-image hiding. In this paper, we propose StegaINR4MIH, a novel implicit neural representation steganography framework that enables the hiding of multiple images within a single implicit representation function. In contrast to traditional methods that use multiple encoders to achieve multi-image embedding, our approach leverages the redundancy of implicit representation function parameters and employs magnitude-based weight selection and secret weight substitution on pre-trained cover image functions to effectively hide and independently extract multiple secret images. We conduct experiments on images with a resolution of from three different datasets: CelebA-HQ, COCO, and DIV2K. When hiding two secret images, the PSNR values of both the secret images and the stego images exceed 42. When hiding five secret images, the PSNR values of both the secret images and the stego images exceed 39. Extensive experiments demonstrate the superior performance of the proposed method in terms of visual quality and undetectability.
Skeleton Ground Truth Extraction: Methodology, Annotation Tool and Benchmarks
Oct 10, 2023Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN) but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target's context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
Jul 19, 2020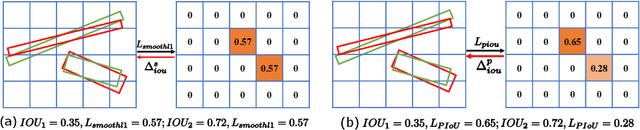
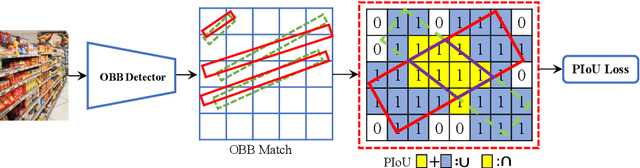
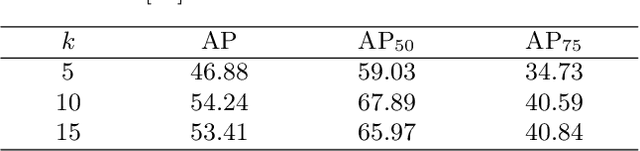
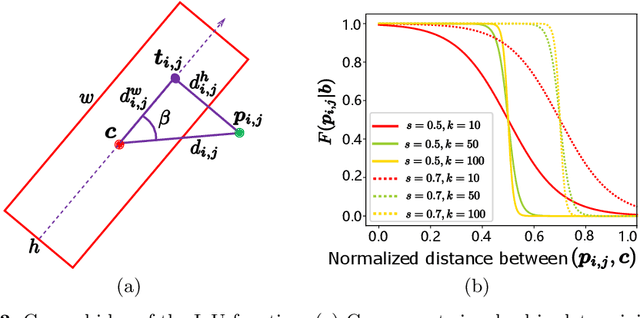
Object detection using an oriented bounding box (OBB) can better target rotated objects by reducing the overlap with background areas. Existing OBB approaches are mostly built on horizontal bounding box detectors by introducing an additional angle dimension optimized by a distance loss. However, as the distance loss only minimizes the angle error of the OBB and that it loosely correlates to the IoU, it is insensitive to objects with high aspect ratios. Therefore, a novel loss, Pixels-IoU (PIoU) Loss, is formulated to exploit both the angle and IoU for accurate OBB regression. The PIoU loss is derived from IoU metric with a pixel-wise form, which is simple and suitable for both horizontal and oriented bounding box. To demonstrate its effectiveness, we evaluate the PIoU loss on both anchor-based and anchor-free frameworks. The experimental results show that PIoU loss can dramatically improve the performance of OBB detectors, particularly on objects with high aspect ratios and complex backgrounds. Besides, previous evaluation datasets did not include scenarios where the objects have high aspect ratios, hence a new dataset, Retail50K, is introduced to encourage the community to adapt OBB detectors for more complex environments.
Generative Steganography by Sampling
Apr 26, 2018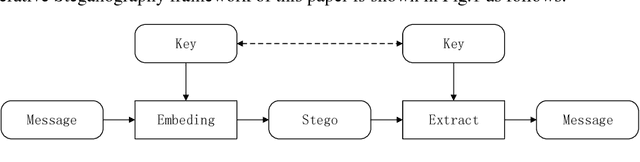
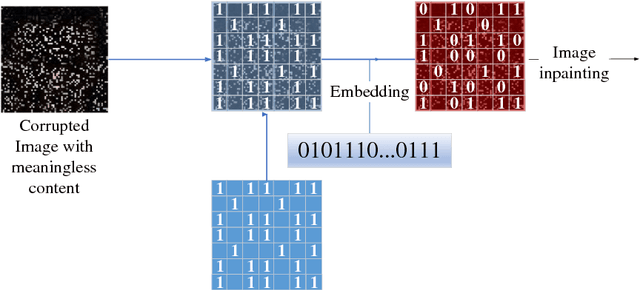
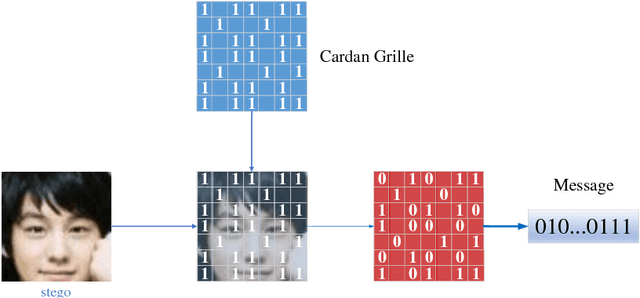

In this paper, a new data-driven information hiding scheme called generative steganography by sampling (GSS) is proposed. The stego is directly sampled by a powerful generator without an explicit cover. Secret key shared by both parties is used for message embedding and extraction, respectively. Jensen-Shannon Divergence is introduced as new criteria for evaluation of the security of the generative steganography. Based on these principles, a simple practical generative steganography method is proposed using semantic image inpainting. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated stego images.