 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMexPub: Deep Transfer Learning for Metadata Extraction from German Publications
Paper and Code
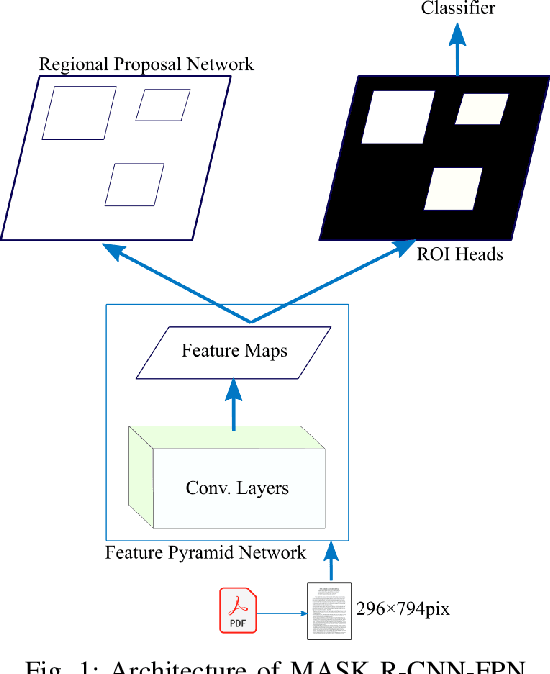


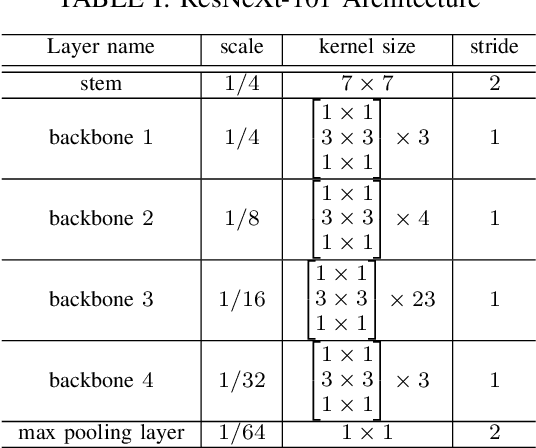
Extracting metadata from scientific papers can be considered a solved problem in NLP due to the high accuracy of state-of-the-art methods. However, this does not apply to German scientific publications, which have a variety of styles and layouts. In contrast to most of the English scientific publications that follow standard and simple layouts, the order, content, position and size of metadata in German publications vary greatly among publications. This variety makes traditional NLP methods fail to accurately extract metadata from these publications. In this paper, we present a method that extracts metadata from PDF documents with different layouts and styles by viewing the document as an image. We used Mask R-CNN that is trained on COCO dataset and finetuned with PubLayNet dataset that consists of ~200K PDF snapshots with five basic classes (e.g. text, figure, etc). We refine-tuned the model on our proposed synthetic dataset consisting of ~30K article snapshots to extract nine patterns (i.e. author, title, etc). Our synthetic dataset is generated using contents in both languages German and English and a finite set of challenging templates obtained from German publications. Our method achieved an average accuracy of around $90\%$ which validates its capability to accurately extract metadata from a variety of PDF documents with challenging templates.