 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised learning algorithms resilient to discriminatory data perturbations
Dec 17, 2019
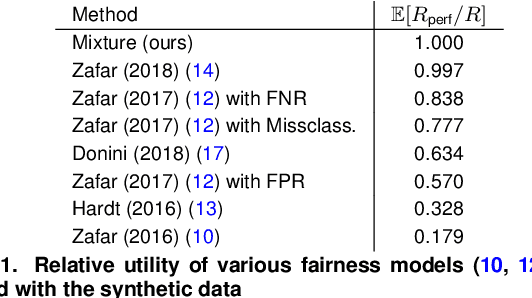
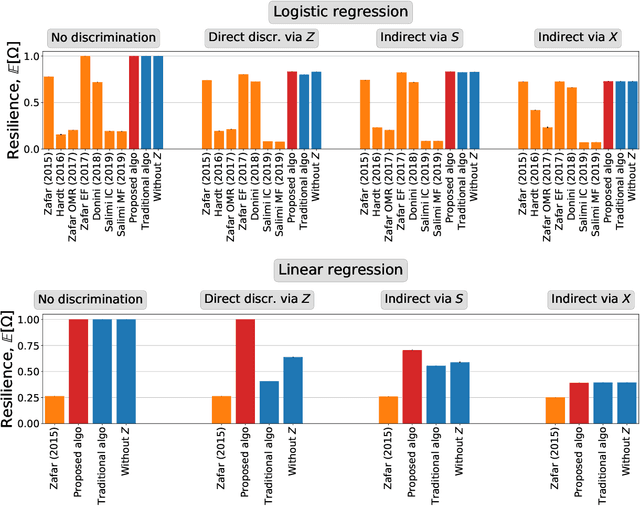

The actions of individuals can be discriminatory with respect to certain protected attributes, such as race or sex. Recently, discrimination has become a focal concern in supervised learning algorithms augmenting human decision-making. These systems are trained using historical data, which may have been tainted by discrimination, and may learn biases against the protected groups. An important question is how to train models without propagating discrimination. Such discrimination can be either direct, when one or more of protected attributes are used in the decision-making directly, or indirect, when other attributes correlated with the protected attributes are used in an unjustified manner. In this work, we i) model discrimination as a perturbation of data-generating process; ii) introduce a measure of resilience of a supervised learning algorithm to potentially discriminatory data perturbations; and iii) propose a novel supervised learning method that is more resilient to such discriminatory perturbations than state-of-the-art learning algorithms addressing discrimination. The proposed method can be used with general supervised learning algorithms, prevents direct discrimination and avoids inducement of indirect discrimination, while maximizing model accuracy.