 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Gray Area: Characterizing Moderator Disagreement on Reddit
Jan 07, 2026Volunteer moderators play a crucial role in sustaining online dialogue, but they often disagree about what should or should not be allowed. In this paper, we study the complexity of content moderation with a focus on disagreements between moderators, which we term the ``gray area'' of moderation. Leveraging 5 years and 4.3 million moderation log entries from 24 subreddits of different topics and sizes, we characterize how gray area, or disputed cases, differ from undisputed cases. We show that one-in-seven moderation cases are disputed among moderators, often addressing transgressions where users' intent is not directly legible, such as in trolling and brigading, as well as tensions around community governance. This is concerning, as almost half of all gray area cases involved automated moderation decisions. Through information-theoretic evaluations, we demonstrate that gray area cases are inherently harder to adjudicate than undisputed cases and show that state-of-the-art language models struggle to adjudicate them. We highlight the key role of expert human moderators in overseeing the moderation process and provide insights about the challenges of current moderation processes and tools.
Robustness and Confounders in the Demographic Alignment of LLMs with Human Perceptions of Offensiveness
Nov 13, 2024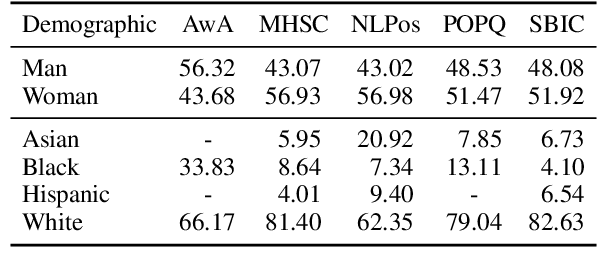
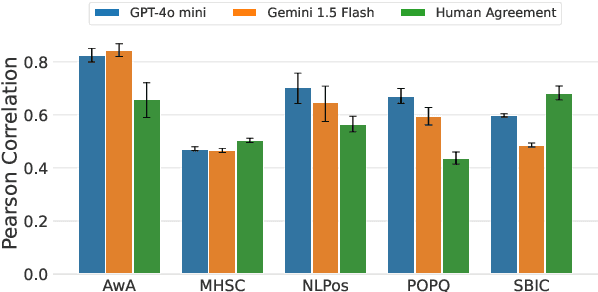
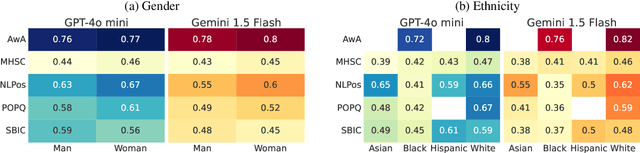
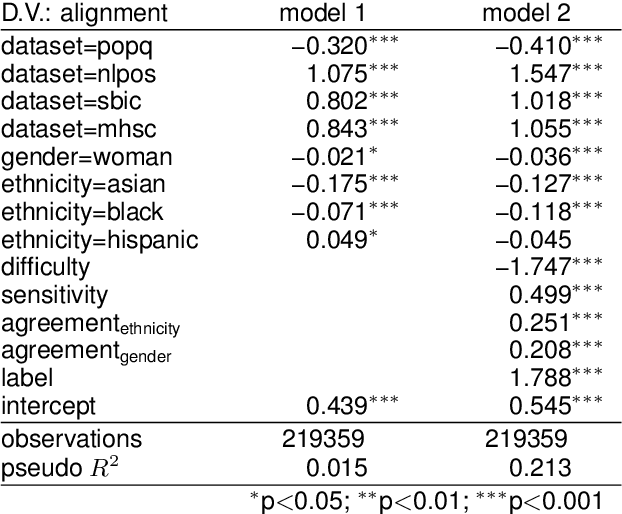
Large language models (LLMs) are known to exhibit demographic biases, yet few studies systematically evaluate these biases across multiple datasets or account for confounding factors. In this work, we examine LLM alignment with human annotations in five offensive language datasets, comprising approximately 220K annotations. Our findings reveal that while demographic traits, particularly race, influence alignment, these effects are inconsistent across datasets and often entangled with other factors. Confounders -- such as document difficulty, annotator sensitivity, and within-group agreement -- account for more variation in alignment patterns than demographic traits alone. Specifically, alignment increases with higher annotator sensitivity and group agreement, while greater document difficulty corresponds to reduced alignment. Our results underscore the importance of multi-dataset analyses and confounder-aware methodologies in developing robust measures of demographic bias in LLMs.
A Multilingual Similarity Dataset for News Article Frame
May 22, 2024Understanding the writing frame of news articles is vital for addressing social issues, and thus has attracted notable attention in the fields of communication studies. Yet, assessing such news article frames remains a challenge due to the absence of a concrete and unified standard dataset that considers the comprehensive nuances within news content. To address this gap, we introduce an extended version of a large labeled news article dataset with 16,687 new labeled pairs. Leveraging the pairwise comparison of news articles, our method frees the work of manual identification of frame classes in traditional news frame analysis studies. Overall we introduce the most extensive cross-lingual news article similarity dataset available to date with 26,555 labeled news article pairs across 10 languages. Each data point has been meticulously annotated according to a codebook detailing eight critical aspects of news content, under a human-in-the-loop framework. Application examples demonstrate its potential in unearthing country communities within global news coverage, exposing media bias among news outlets, and quantifying the factors related to news creation. We envision that this news similarity dataset will broaden our understanding of the media ecosystem in terms of news coverage of events and perspectives across countries, locations, languages, and other social constructs. By doing so, it can catalyze advancements in social science research and applied methodologies, thereby exerting a profound impact on our society.
The Unseen Targets of Hate -- A Systematic Review of Hateful Communication Datasets
May 14, 2024Machine learning (ML)-based content moderation tools are essential to keep online spaces free from hateful communication. Yet, ML tools can only be as capable as the quality of the data they are trained on allows them. While there is increasing evidence that they underperform in detecting hateful communications directed towards specific identities and may discriminate against them, we know surprisingly little about the provenance of such bias. To fill this gap, we present a systematic review of the datasets for the automated detection of hateful communication introduced over the past decade, and unpack the quality of the datasets in terms of the identities that they embody: those of the targets of hateful communication that the data curators focused on, as well as those unintentionally included in the datasets. We find, overall, a skewed representation of selected target identities and mismatches between the targets that research conceptualizes and ultimately includes in datasets. Yet, by contextualizing these findings in the language and location of origin of the datasets, we highlight a positive trend towards the broadening and diversification of this research space.
Global News Synchrony and Diversity During the Start of the COVID-19 Pandemic
May 01, 2024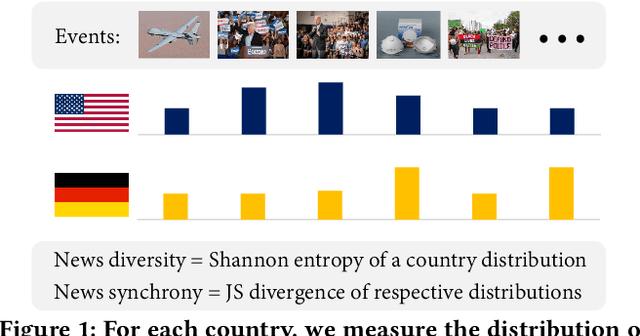
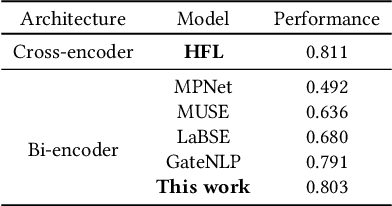
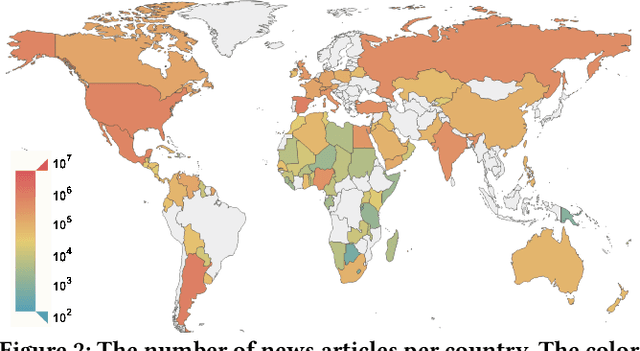

News coverage profoundly affects how countries and individuals behave in international relations. Yet, we have little empirical evidence of how news coverage varies across countries. To enable studies of global news coverage, we develop an efficient computational methodology that comprises three components: (i) a transformer model to estimate multilingual news similarity; (ii) a global event identification system that clusters news based on a similarity network of news articles; and (iii) measures of news synchrony across countries and news diversity within a country, based on country-specific distributions of news coverage of the global events. Each component achieves state-of-the art performance, scaling seamlessly to massive datasets of millions of news articles. We apply the methodology to 60 million news articles published globally between January 1 and June 30, 2020, across 124 countries and 10 languages, detecting 4357 news events. We identify the factors explaining diversity and synchrony of news coverage across countries. Our study reveals that news media tend to cover a more diverse set of events in countries with larger Internet penetration, more official languages, larger religious diversity, higher economic inequality, and larger populations. Coverage of news events is more synchronized between countries that not only actively participate in commercial and political relations -- such as, pairs of countries with high bilateral trade volume, and countries that belong to the NATO military alliance or BRICS group of major emerging economies -- but also countries that share certain traits: an official language, high GDP, and high democracy indices.
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Nov 02, 2023



NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
May 09, 2022
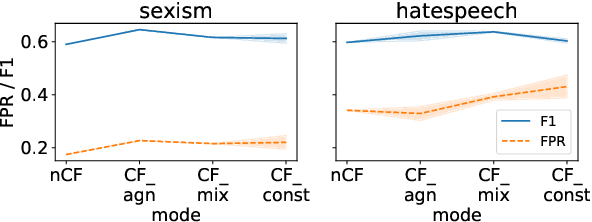
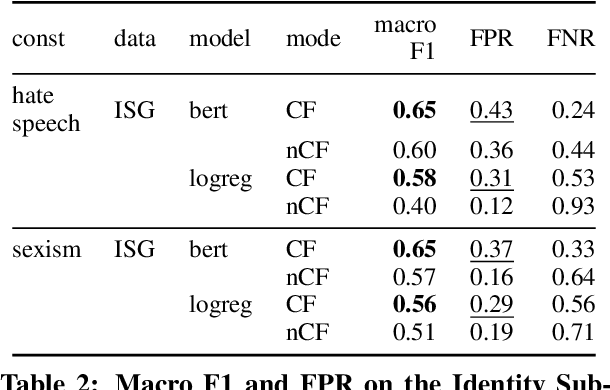
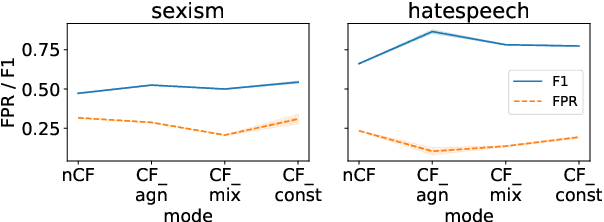
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement is credited with promoting core features of the construct over spurious artifacts that happen to correlate with it. Yet, over-relying on core features may lead to unintended model bias. Especially, construct-driven CAD -- perturbations of core features -- may induce models to ignore the context in which core features are used. Here, we test models for sexism and hate speech detection on challenging data: non-hateful and non-sexist usage of identity and gendered terms. In these hard cases, models trained on CAD, especially construct-driven CAD, show higher false-positive rates than models trained on the original, unperturbed data. Using a diverse set of CAD -- construct-driven and construct-agnostic -- reduces such unintended bias.
Pathways through Conspiracy: The Evolution of Conspiracy Radicalization through Engagement in Online Conspiracy Discussions
Apr 22, 2022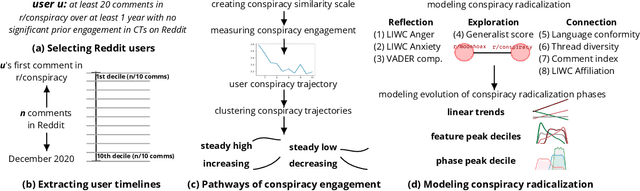

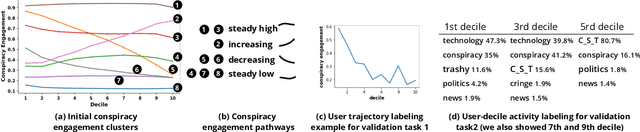

The disruptive offline mobilization of participants in online conspiracy theory (CT) discussions has highlighted the importance of understanding how online users may form radicalized conspiracy beliefs. While prior work researched the factors leading up to joining online CT discussions and provided theories of how conspiracy beliefs form, we have little understanding of how conspiracy radicalization evolves after users join CT discussion communities. In this paper, we provide the empirical modeling of various radicalization phases in online CT discussion participants. To unpack how conspiracy engagement is related to radicalization, we first characterize the users' journey through CT discussions via conspiracy engagement pathways. Specifically, by studying 36K Reddit users through their 169M contributions, we uncover four distinct pathways of conspiracy engagement: steady high, increasing, decreasing, and steady low. We further model three successive stages of radicalization guided by prior theoretical works. Specific sub-populations of users, namely those on steady high and increasing conspiracy engagement pathways, progress successively through various radicalization stages. In contrast, users on the decreasing engagement pathway show distinct behavior: they limit their CT discussions to specialized topics, participate in diverse discussion groups, and show reduced conformity with conspiracy subreddits. By examining users who disengage from online CT discussions, this paper provides promising insights about conspiracy recovery process.
Characterizing Social Imaginaries and Self-Disclosures of Dissonance in Online Conspiracy Discussion Communities
Jul 21, 2021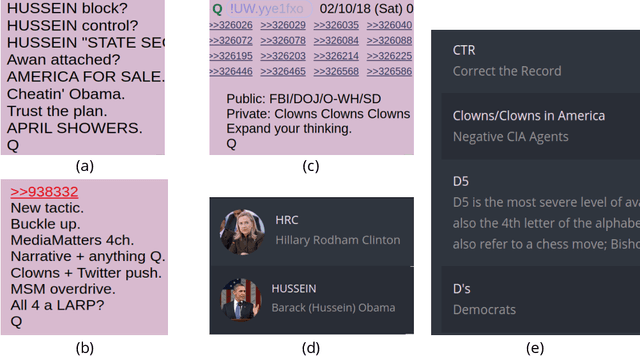

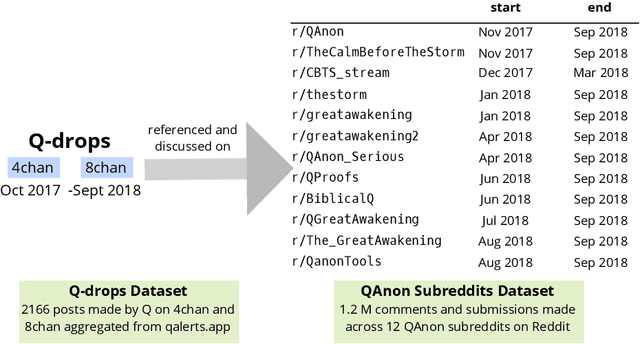
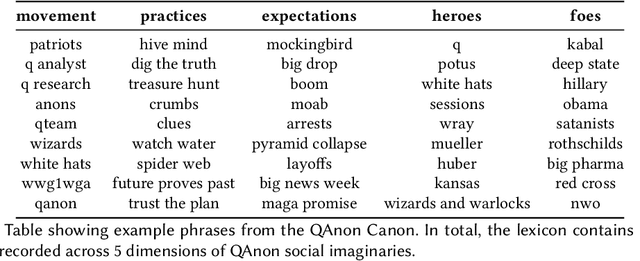
Online discussion platforms offer a forum to strengthen and propagate belief in misinformed conspiracy theories. Yet, they also offer avenues for conspiracy theorists to express their doubts and experiences of cognitive dissonance. Such expressions of dissonance may shed light on who abandons misguided beliefs and under which circumstances. This paper characterizes self-disclosures of dissonance about QAnon, a conspiracy theory initiated by a mysterious leader Q and popularized by their followers, anons in conspiracy theory subreddits. To understand what dissonance and disbelief mean within conspiracy communities, we first characterize their social imaginaries, a broad understanding of how people collectively imagine their social existence. Focusing on 2K posts from two image boards, 4chan and 8chan, and 1.2 M comments and posts from 12 subreddits dedicated to QAnon, we adopt a mixed methods approach to uncover the symbolic language representing the movement, expectations, practices, heroes and foes of the QAnon community. We use these social imaginaries to create a computational framework for distinguishing belief and dissonance from general discussion about QAnon. Further, analyzing user engagement with QAnon conspiracy subreddits, we find that self-disclosures of dissonance correlate with a significant decrease in user contributions and ultimately with their departure from the community. We contribute a computational framework for identifying dissonance self-disclosures and measuring the changes in user engagement surrounding dissonance. Our work can provide insights into designing dissonance-based interventions that can potentially dissuade conspiracists from online conspiracy discussion communities.
"Unsex me here": Revisiting Sexism Detection Using Psychological Scales and Adversarial Samples
Apr 27, 2020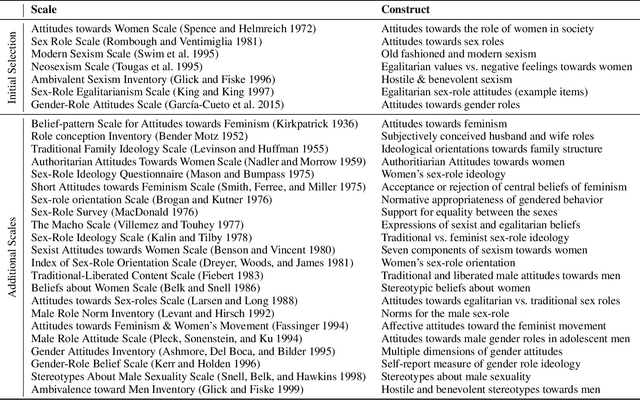
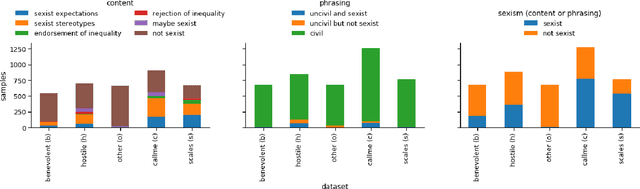

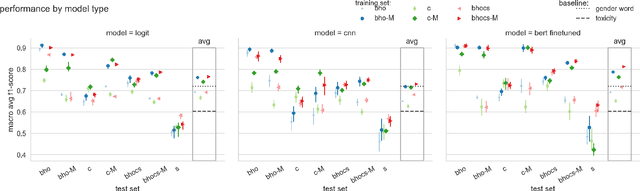
To effectively tackle sexism online, research has focused on automated methods for detecting sexism. In this paper, we use items from psychological scales and adversarial sample generation to 1) provide a codebook for different types of sexism in theory-driven scales and in social media text; 2) test the performance of different sexism detection methods across multiple data sets; 3) provide an overview of strategies employed by humans to remove sexism through minimal changes. Results highlight that current methods seem inadequate in detecting all but the most blatant forms of sexism and do not generalize well to out-of-domain examples. By providing a scale-based codebook for sexism and insights into what makes a statement sexist, we hope to contribute to the development of better and broader models for sexism detection, including reflections on theory-driven approaches to data collection.