 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Gray Area: Characterizing Moderator Disagreement on Reddit
Jan 07, 2026Volunteer moderators play a crucial role in sustaining online dialogue, but they often disagree about what should or should not be allowed. In this paper, we study the complexity of content moderation with a focus on disagreements between moderators, which we term the ``gray area'' of moderation. Leveraging 5 years and 4.3 million moderation log entries from 24 subreddits of different topics and sizes, we characterize how gray area, or disputed cases, differ from undisputed cases. We show that one-in-seven moderation cases are disputed among moderators, often addressing transgressions where users' intent is not directly legible, such as in trolling and brigading, as well as tensions around community governance. This is concerning, as almost half of all gray area cases involved automated moderation decisions. Through information-theoretic evaluations, we demonstrate that gray area cases are inherently harder to adjudicate than undisputed cases and show that state-of-the-art language models struggle to adjudicate them. We highlight the key role of expert human moderators in overseeing the moderation process and provide insights about the challenges of current moderation processes and tools.
When Attention Becomes Exposure in Generative Search
Jan 05, 2026Generative search engines are reshaping information access by replacing traditional ranked lists with synthesized answers and references. In parallel, with the growth of Web3 platforms, incentive-driven creator ecosystems have become an essential part of how enterprises build visibility and community by rewarding creators for contributing to shared narratives. However, the extent to which exposure in generative search engine citations is shaped by external attention markets remains uncertain. In this study, we audit the exposure for 44 Web3 enterprises. First, we show that the creator community around each enterprise is persistent over time. Second, enterprise-specific queries reveal that more popular voices systematically receive greater citation exposure than others. Third, we find that larger follower bases and enterprises with more concentrated creator cores are associated with higher-ranked exposure. Together, these results show that generative search engine citations exhibit exposure bias toward already prominent voices, which risks entrenching incumbents and narrowing viewpoint diversity.
Robustness and Confounders in the Demographic Alignment of LLMs with Human Perceptions of Offensiveness
Nov 13, 2024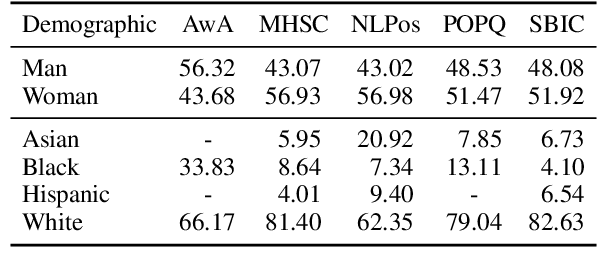
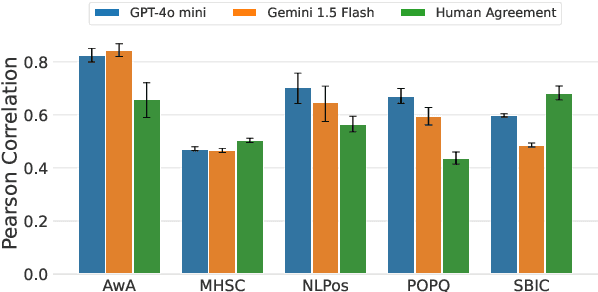
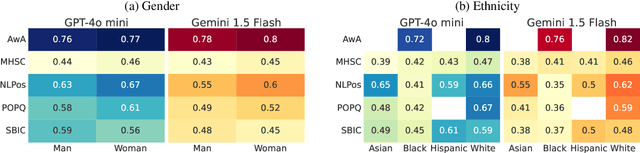
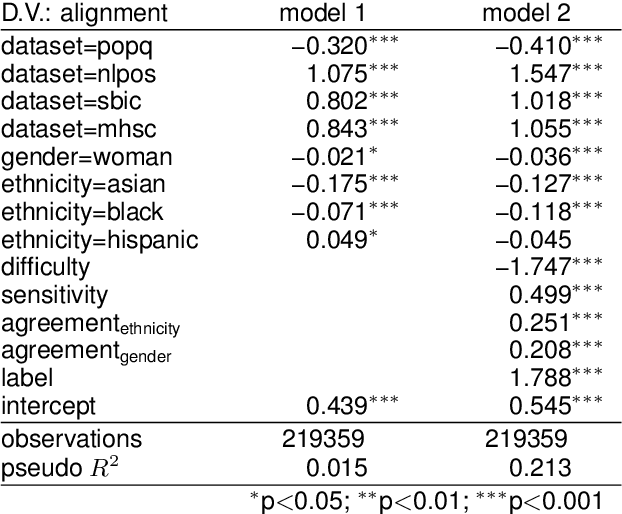
Large language models (LLMs) are known to exhibit demographic biases, yet few studies systematically evaluate these biases across multiple datasets or account for confounding factors. In this work, we examine LLM alignment with human annotations in five offensive language datasets, comprising approximately 220K annotations. Our findings reveal that while demographic traits, particularly race, influence alignment, these effects are inconsistent across datasets and often entangled with other factors. Confounders -- such as document difficulty, annotator sensitivity, and within-group agreement -- account for more variation in alignment patterns than demographic traits alone. Specifically, alignment increases with higher annotator sensitivity and group agreement, while greater document difficulty corresponds to reduced alignment. Our results underscore the importance of multi-dataset analyses and confounder-aware methodologies in developing robust measures of demographic bias in LLMs.