 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestions for Flat-Minima Optimization of Modern Neural Networks
Paper and Code
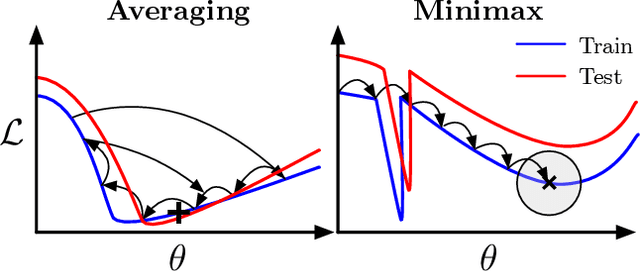
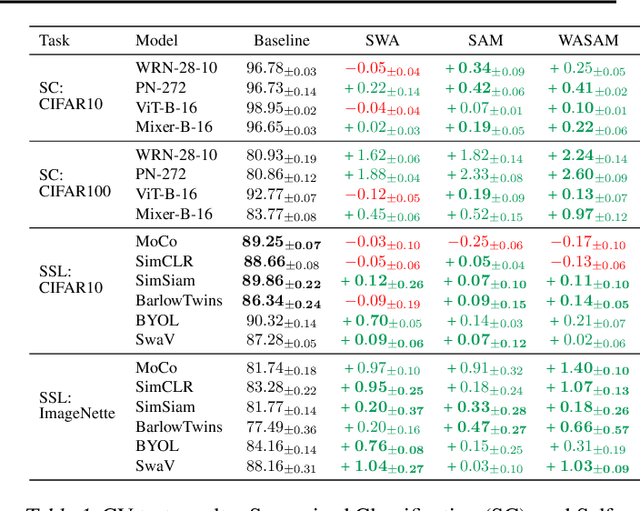
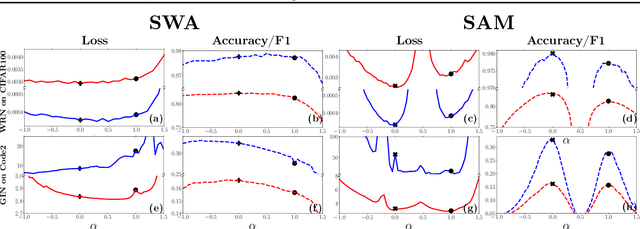
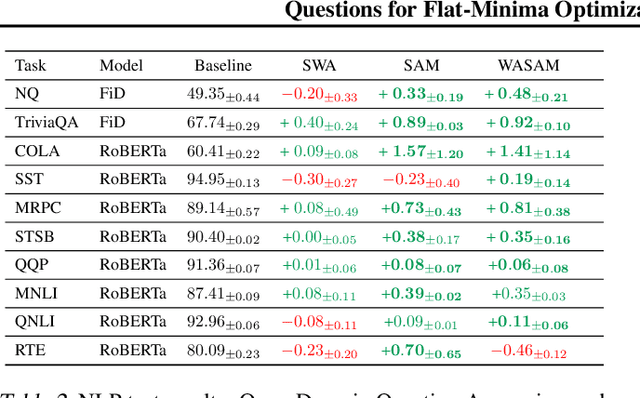
For training neural networks, flat-minima optimizers that seek to find parameters in neighborhoods having uniformly low loss (flat minima) have been shown to improve upon stochastic and adaptive gradient-based methods. Two methods for finding flat minima stand out: 1. Averaging methods (i.e., Stochastic Weight Averaging, SWA), and 2. Minimax methods (i.e., Sharpness Aware Minimization, SAM). However, despite similar motivations, there has been limited investigation into their properties and no comprehensive comparison between them. In this work, we investigate the loss surfaces from a systematic benchmarking of these approaches across computer vision, natural language processing, and graph learning tasks. The results lead to a simple hypothesis: since both approaches find different flat solutions, combining them should improve generalization even further. We verify this improves over either flat-minima approach in 39 out of 42 cases. When it does not, we investigate potential reasons. We hope our results across image, graph, and text data will help researchers to improve deep learning optimizers, and practitioners to pinpoint the optimizer for the problem at hand.