 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegviGen: Repurposing 3D Generative Model for Part Segmentation
Mar 17, 2026We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer
Mar 25, 2021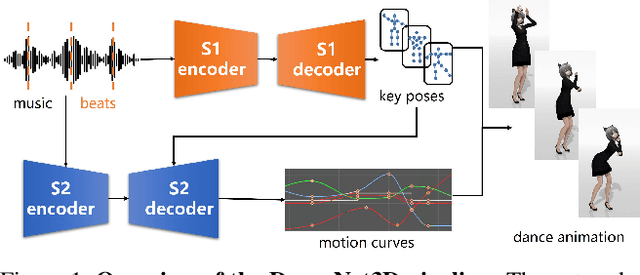

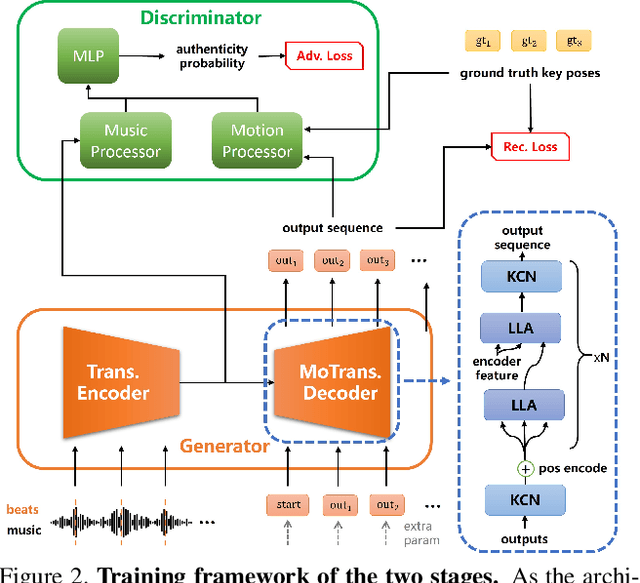
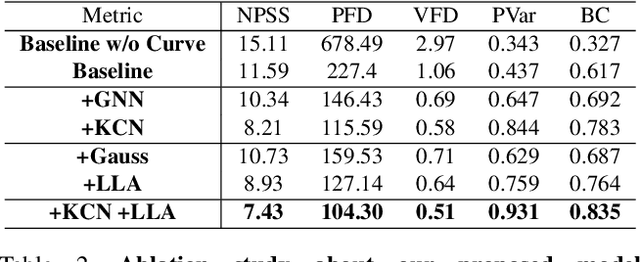
In this work, we propose a novel deep learning framework that can generate a vivid dance from a whole piece of music. In contrast to previous works that define the problem as generation of frames of motion state parameters, we formulate the task as a prediction of motion curves between key poses, which is inspired by the animation industry practice. The proposed framework, named DanceNet3D, first generates key poses on beats of the given music and then predicts the in-between motion curves. DanceNet3D adopts the encoder-decoder architecture and the adversarial schemes for training. The decoders in DanceNet3D are constructed on MoTrans, a transformer tailored for motion generation. In MoTrans we introduce the kinematic correlation by the Kinematic Chain Networks, and we also propose the Learned Local Attention module to take the temporal local correlation of human motion into consideration. Furthermore, we propose PhantomDance, the first large-scale dance dataset produced by professional animatiors, with accurate synchronization with music. Extensive experiments demonstrate that the proposed approach can generate fluent, elegant, performative and beat-synchronized 3D dances, which significantly surpasses previous works quantitatively and qualitatively.
MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection
Sep 24, 2020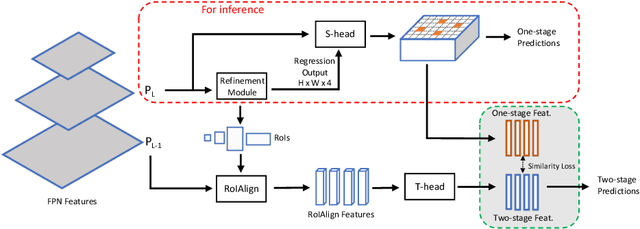
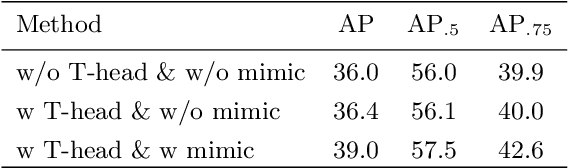
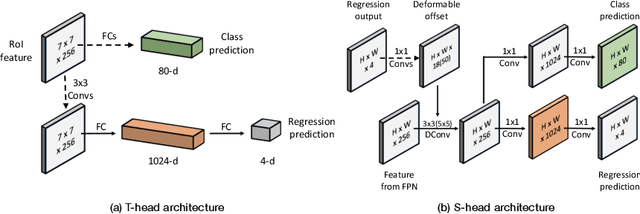
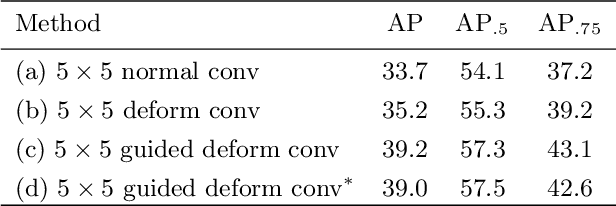
Modern object detection methods can be divided into one-stage approaches and two-stage ones. One-stage detectors are more efficient owing to straightforward architectures, but the two-stage detectors still take the lead in accuracy. Although recent work try to improve the one-stage detectors by imitating the structural design of the two-stage ones, the accuracy gap is still significant. In this paper, we propose MimicDet, a novel and efficient framework to train a one-stage detector by directly mimic the two-stage features, aiming to bridge the accuracy gap between one-stage and two-stage detectors. Unlike conventional mimic methods, MimicDet has a shared backbone for one-stage and two-stage detectors, then it branches into two heads which are well designed to have compatible features for mimicking. Thus MimicDet can be end-to-end trained without the pre-train of the teacher network. And the cost does not increase much, which makes it practical to adopt large networks as backbones. We also make several specialized designs such as dual-path mimicking and staggered feature pyramid to facilitate the mimicking process. Experiments on the challenging COCO detection benchmark demonstrate the effectiveness of MimicDet. It achieves 46.1 mAP with ResNeXt-101 backbone on the COCO test-dev set, which significantly surpasses current state-of-the-art methods.
Equalization Loss for Long-Tailed Object Recognition
Apr 14, 2020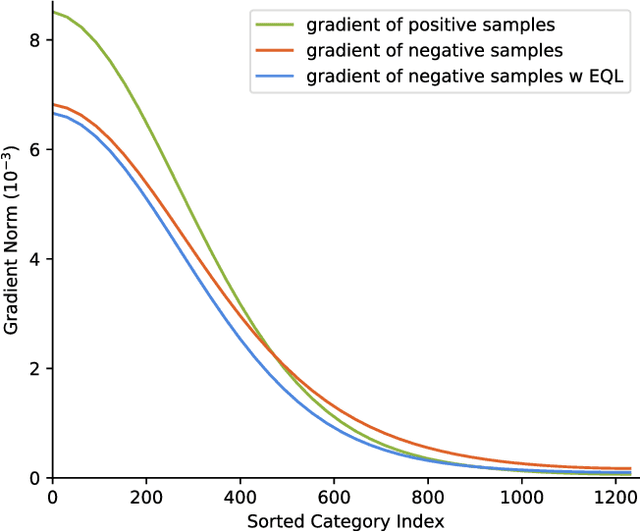
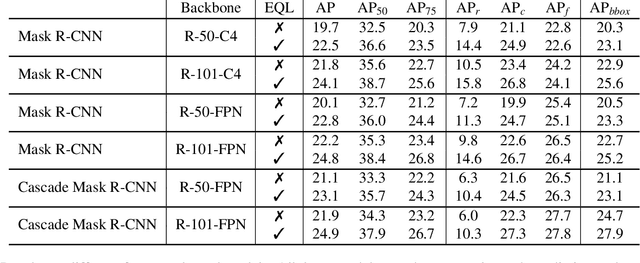
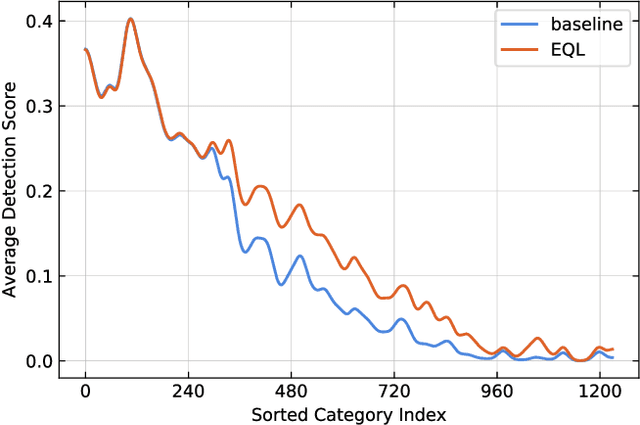
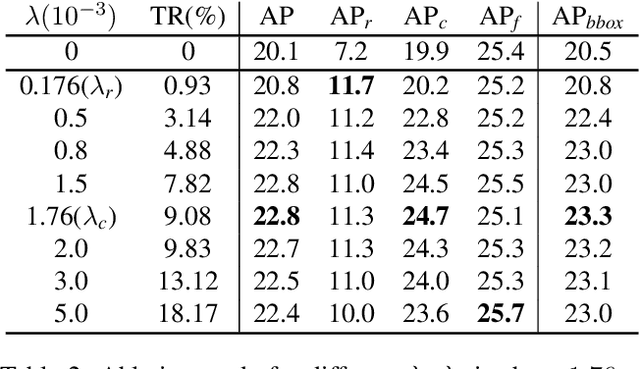
Object recognition techniques using convolutional neural networks (CNN) have achieved great success. However, state-of-the-art object detection methods still perform poorly on large vocabulary and long-tailed datasets, e.g. LVIS. In this work, we analyze this problem from a novel perspective: each positive sample of one category can be seen as a negative sample for other categories, making the tail categories receive more discouraging gradients. Based on it, we propose a simple but effective loss, named equalization loss, to tackle the problem of long-tailed rare categories by simply ignoring those gradients for rare categories. The equalization loss protects the learning of rare categories from being at a disadvantage during the network parameter updating. Thus the model is capable of learning better discriminative features for objects of rare classes. Without any bells and whistles, our method achieves AP gains of 4.1% and 4.8% for the rare and common categories on the challenging LVIS benchmark, compared to the Mask R-CNN baseline. With the utilization of the effective equalization loss, we finally won the 1st place in the LVIS Challenge 2019. Code has been made available at: https: //github.com/tztztztztz/eql.detectron2
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation
Feb 05, 2020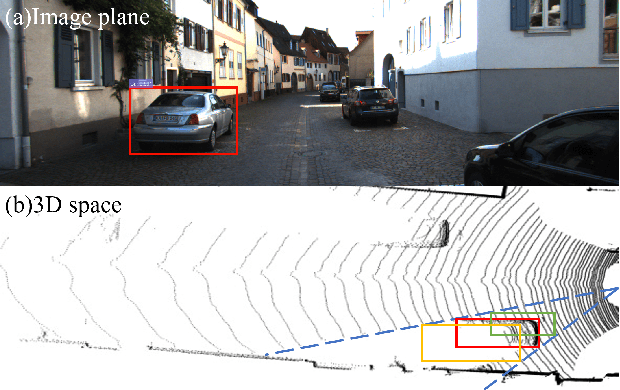
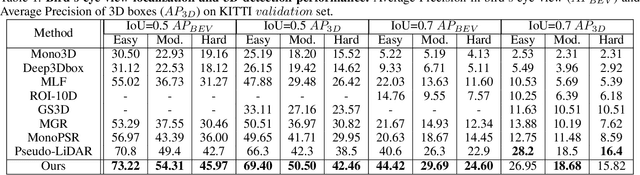
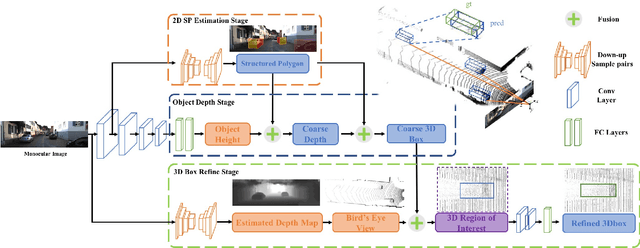
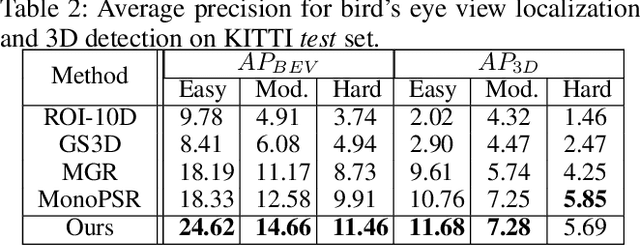
Monocular 3D object detection task aims to predict the 3D bounding boxes of objects based on monocular RGB images. Since the location recovery in 3D space is quite difficult on account of absence of depth information, this paper proposes a novel unified framework which decomposes the detection problem into a structured polygon prediction task and a depth recovery task. Different from the widely studied 2D bounding boxes, the proposed novel structured polygon in the 2D image consists of several projected surfaces of the target object. Compared to the widely-used 3D bounding box proposals, it is shown to be a better representation for 3D detection. In order to inversely project the predicted 2D structured polygon to a cuboid in the 3D physical world, the following depth recovery task uses the object height prior to complete the inverse projection transformation with the given camera projection matrix. Moreover, a fine-grained 3D box refinement scheme is proposed to further rectify the 3D detection results. Experiments are conducted on the challenging KITTI benchmark, in which our method achieves state-of-the-art detection accuracy.
MMDetection: Open MMLab Detection Toolbox and Benchmark
Jun 17, 2019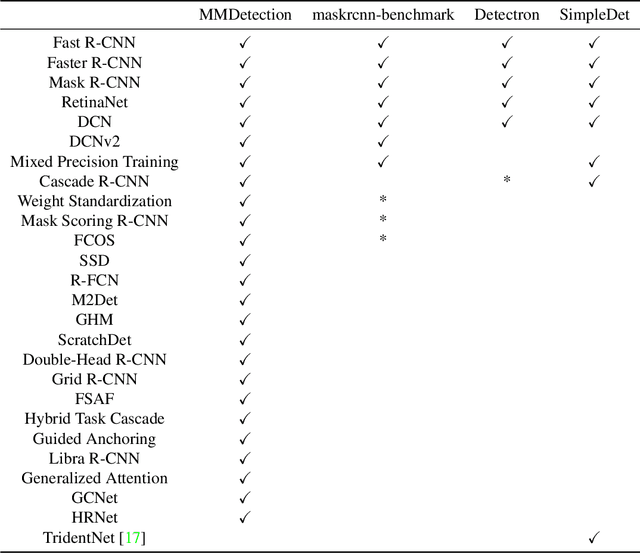
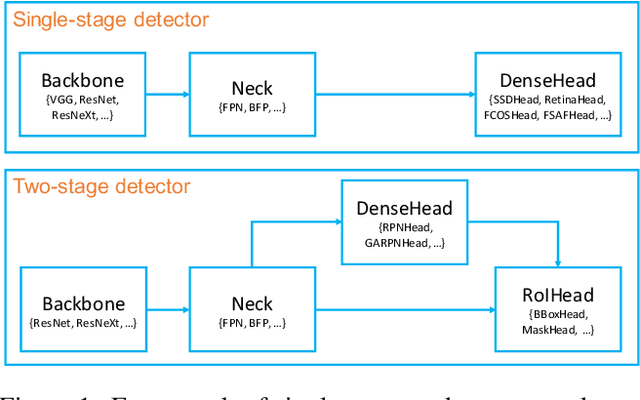
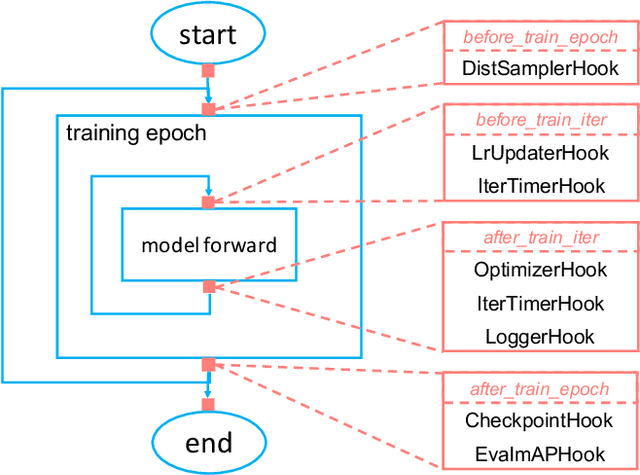
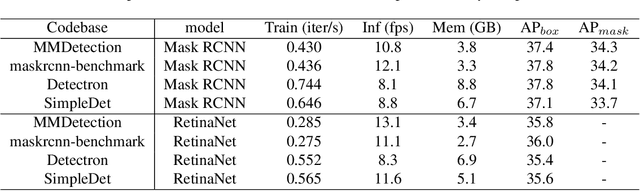
We present MMDetection, an object detection toolbox that contains a rich set of object detection and instance segmentation methods as well as related components and modules. The toolbox started from a codebase of MMDet team who won the detection track of COCO Challenge 2018. It gradually evolves into a unified platform that covers many popular detection methods and contemporary modules. It not only includes training and inference codes, but also provides weights for more than 200 network models. We believe this toolbox is by far the most complete detection toolbox. In this paper, we introduce the various features of this toolbox. In addition, we also conduct a benchmarking study on different methods, components, and their hyper-parameters. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new detectors. Code and models are available at https://github.com/open-mmlab/mmdetection. The project is under active development and we will keep this document updated.
Grid R-CNN Plus: Faster and Better
Jun 13, 2019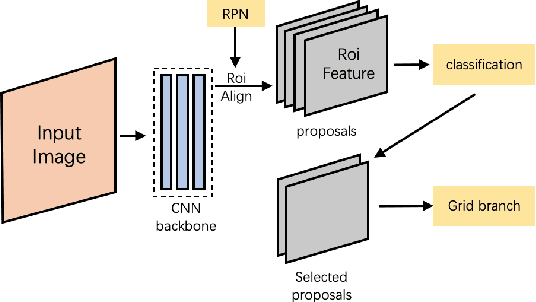
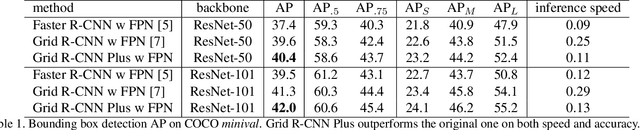
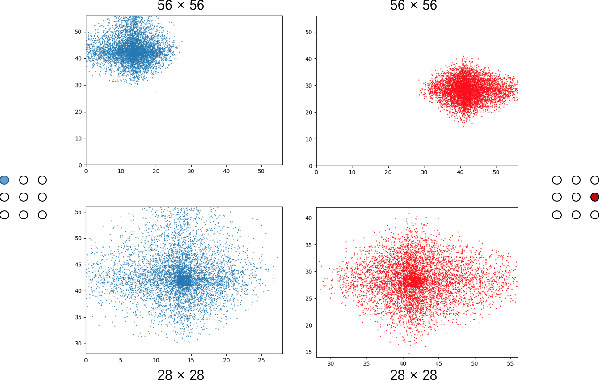
Grid R-CNN is a well-performed objection detection framework. It transforms the traditional box offset regression problem into a grid point estimation problem. With the guidance of the grid points, it can obtain high-quality localization results. However, the speed of Grid R-CNN is not so satisfactory. In this technical report we present Grid R-CNN Plus, a better and faster version of Grid R-CNN. We have made several updates that significantly speed up the framework and simultaneously improve the accuracy. On COCO dataset, the Res50-FPN based Grid R-CNN Plus detector achieves an mAP of 40.4%, outperforming the baseline on the same model by 3.0 points with similar inference time. Code is available at https://github.com/STVIR/Grid-R-CNN .
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
Mar 27, 2019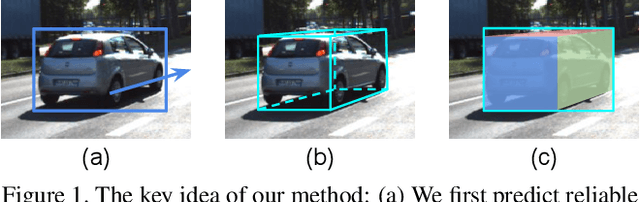
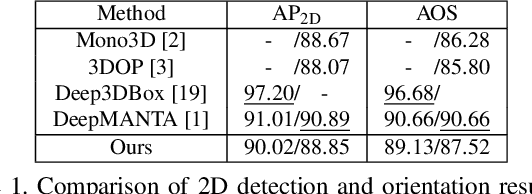

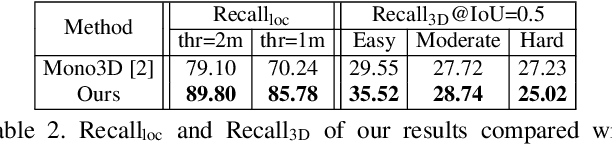
We present an efficient 3D object detection framework based on a single RGB image in the scenario of autonomous driving. Our efforts are put on extracting the underlying 3D information in a 2D image and determining the accurate 3D bounding box of the object without point cloud or stereo data. Leveraging the off-the-shelf 2D object detector, we propose an artful approach to efficiently obtain a coarse cuboid for each predicted 2D box. The coarse cuboid has enough accuracy to guide us to determine the 3D box of the object by refinement. In contrast to previous state-of-the-art methods that only use the features extracted from the 2D bounding box for box refinement, we explore the 3D structure information of the object by employing the visual features of visible surfaces. The new features from surfaces are utilized to eliminate the problem of representation ambiguity brought by only using a 2D bounding box. Moreover, we investigate different methods of 3D box refinement and discover that a classification formulation with quality aware loss has much better performance than regression. Evaluated on the KITTI benchmark, our approach outperforms current state-of-the-art methods for single RGB image based 3D object detection.
Grid R-CNN
Nov 29, 2018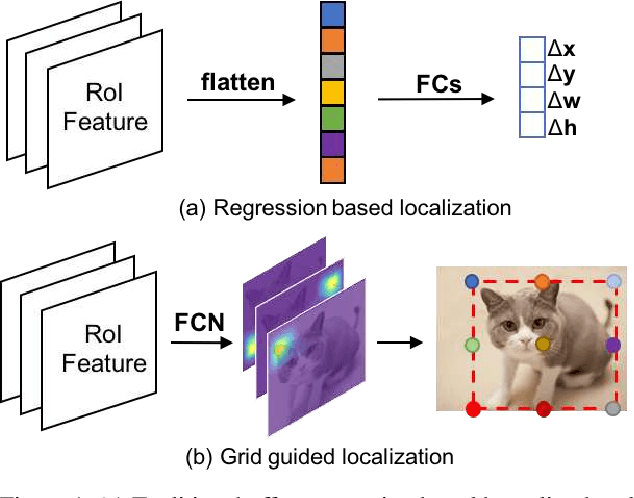
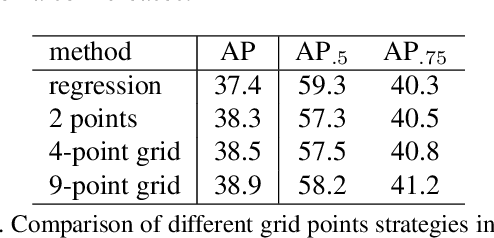
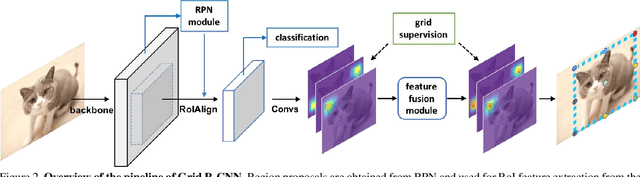
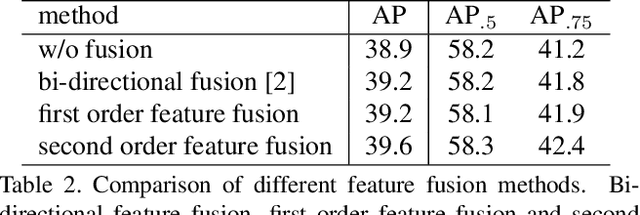
This paper proposes a novel object detection framework named Grid R-CNN, which adopts a grid guided localization mechanism for accurate object detection. Different from the traditional regression based methods, the Grid R-CNN captures the spatial information explicitly and enjoys the position sensitive property of fully convolutional architecture. Instead of using only two independent points, we design a multi-point supervision formulation to encode more clues in order to reduce the impact of inaccurate prediction of specific points. To take the full advantage of the correlation of points in a grid, we propose a two-stage information fusion strategy to fuse feature maps of neighbor grid points. The grid guided localization approach is easy to be extended to different state-of-the-art detection frameworks. Grid R-CNN leads to high quality object localization, and experiments demonstrate that it achieves a 4.1% AP gain at IoU=0.8 and a 10.0% AP gain at IoU=0.9 on COCO benchmark compared to Faster R-CNN with Res50 backbone and FPN architecture.
Gradient Harmonized Single-stage Detector
Nov 13, 2018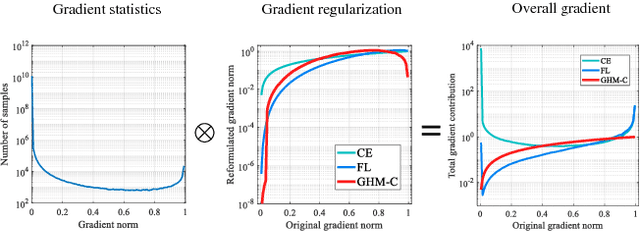
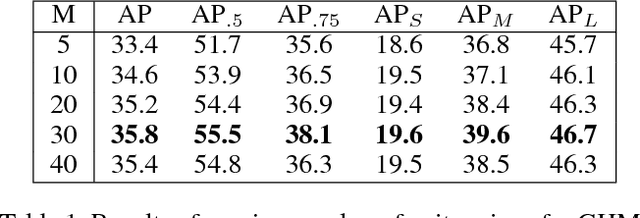
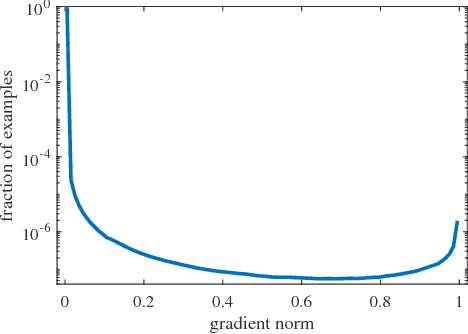
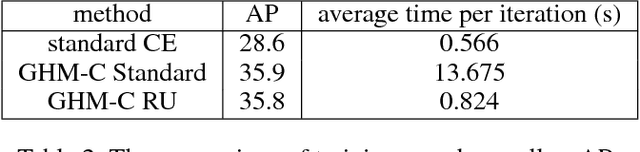
Despite the great success of two-stage detectors, single-stage detector is still a more elegant and efficient way, yet suffers from the two well-known disharmonies during training, i.e. the huge difference in quantity between positive and negative examples as well as between easy and hard examples. In this work, we first point out that the essential effect of the two disharmonies can be summarized in term of the gradient. Further, we propose a novel gradient harmonizing mechanism (GHM) to be a hedging for the disharmonies. The philosophy behind GHM can be easily embedded into both classification loss function like cross-entropy (CE) and regression loss function like smooth-$L_1$ ($SL_1$) loss. To this end, two novel loss functions called GHM-C and GHM-R are designed to balancing the gradient flow for anchor classification and bounding box refinement, respectively. Ablation study on MS COCO demonstrates that without laborious hyper-parameter tuning, both GHM-C and GHM-R can bring substantial improvement for single-stage detector. Without any whistles and bells, our model achieves 41.6 mAP on COCO test-dev set which surpasses the state-of-the-art method, Focal Loss (FL) + $SL_1$, by 0.8.