 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoDistill: Learning Spatial Features for Monocular 3D Object Detection
Jan 26, 2022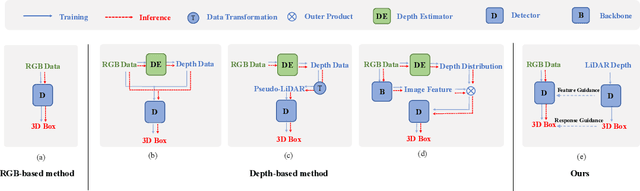
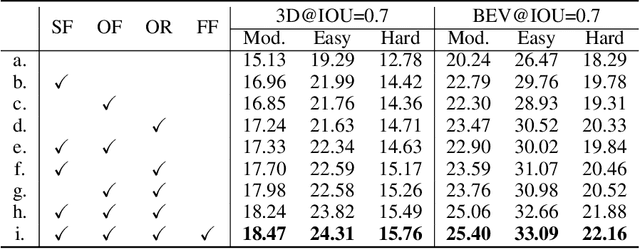

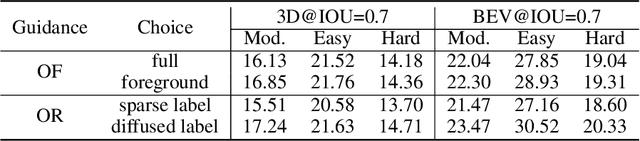
3D object detection is a fundamental and challenging task for 3D scene understanding, and the monocular-based methods can serve as an economical alternative to the stereo-based or LiDAR-based methods. However, accurately detecting objects in the 3D space from a single image is extremely difficult due to the lack of spatial cues. To mitigate this issue, we propose a simple and effective scheme to introduce the spatial information from LiDAR signals to the monocular 3D detectors, without introducing any extra cost in the inference phase. In particular, we first project the LiDAR signals into the image plane and align them with the RGB images. After that, we use the resulting data to train a 3D detector (LiDAR Net) with the same architecture as the baseline model. Finally, this LiDAR Net can serve as the teacher to transfer the learned knowledge to the baseline model. Experimental results show that the proposed method can significantly boost the performance of the baseline model and ranks the $1^{st}$ place among all monocular-based methods on the KITTI benchmark. Besides, extensive ablation studies are conducted, which further prove the effectiveness of each part of our designs and illustrate what the baseline model has learned from the LiDAR Net. Our code will be released at \url{https://github.com/monster-ghost/MonoDistill}.
Grid R-CNN Plus: Faster and Better
Jun 13, 2019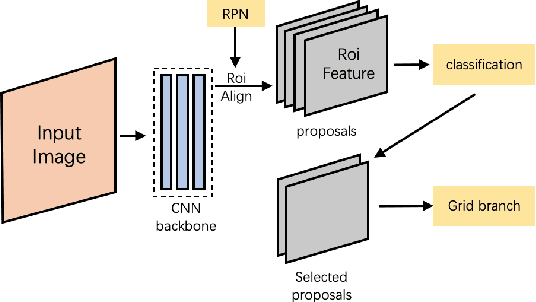
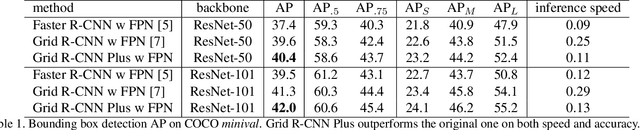
Grid R-CNN is a well-performed objection detection framework. It transforms the traditional box offset regression problem into a grid point estimation problem. With the guidance of the grid points, it can obtain high-quality localization results. However, the speed of Grid R-CNN is not so satisfactory. In this technical report we present Grid R-CNN Plus, a better and faster version of Grid R-CNN. We have made several updates that significantly speed up the framework and simultaneously improve the accuracy. On COCO dataset, the Res50-FPN based Grid R-CNN Plus detector achieves an mAP of 40.4%, outperforming the baseline on the same model by 3.0 points with similar inference time. Code is available at https://github.com/STVIR/Grid-R-CNN .
Grid R-CNN
Nov 29, 2018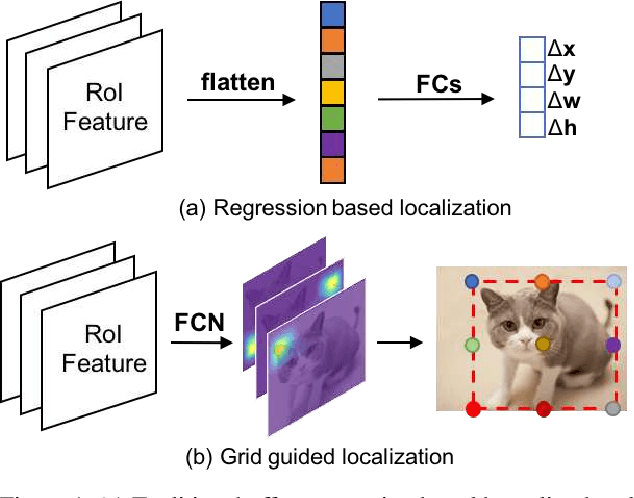
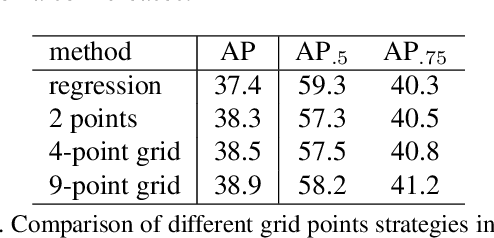
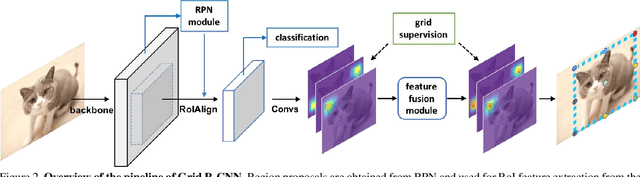
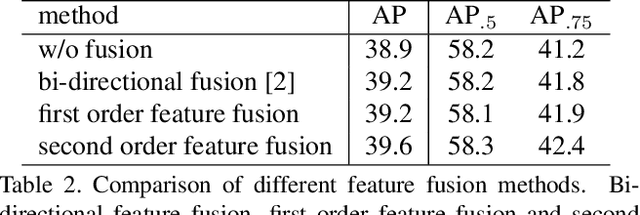
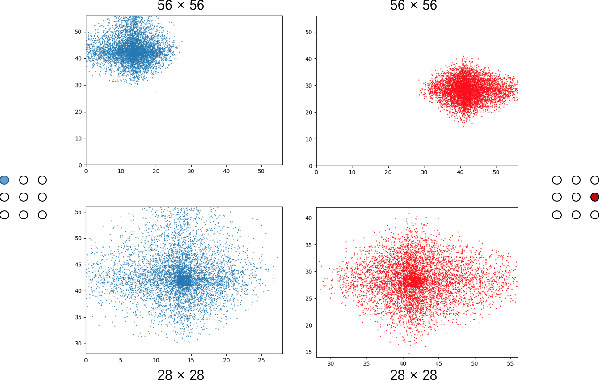
This paper proposes a novel object detection framework named Grid R-CNN, which adopts a grid guided localization mechanism for accurate object detection. Different from the traditional regression based methods, the Grid R-CNN captures the spatial information explicitly and enjoys the position sensitive property of fully convolutional architecture. Instead of using only two independent points, we design a multi-point supervision formulation to encode more clues in order to reduce the impact of inaccurate prediction of specific points. To take the full advantage of the correlation of points in a grid, we propose a two-stage information fusion strategy to fuse feature maps of neighbor grid points. The grid guided localization approach is easy to be extended to different state-of-the-art detection frameworks. Grid R-CNN leads to high quality object localization, and experiments demonstrate that it achieves a 4.1% AP gain at IoU=0.8 and a 10.0% AP gain at IoU=0.9 on COCO benchmark compared to Faster R-CNN with Res50 backbone and FPN architecture.