 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Escalator-related Injury Identification and Prevention Based on Multi-module Integrated System for Public Health
Mar 17, 2021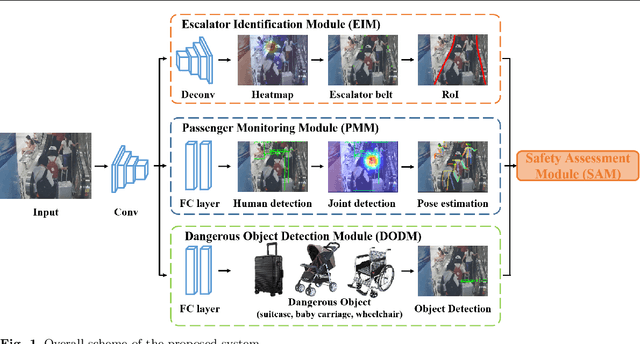


Escalator-related injuries threaten public health with the widespread use of escalators. The existing studies tend to focus on after-the-fact statistics, reflecting on the original design and use of defects to reduce the impact of escalator-related injuries, but few attention has been paid to ongoing and impending injuries. In this study, a multi-module escalator safety monitoring system based on computer vision is designed and proposed to simultaneously monitor and deal with three major injury triggers, including losing balance, not holding on to handrails and carrying large items. The escalator identification module is utilized to determine the escalator region, namely the region of interest. The passenger monitoring module is leveraged to estimate the passengers' pose to recognize unsafe behaviors on the escalator. The dangerous object detection module detects large items that may enter the escalator and raises alarms. The processing results of the above three modules are summarized in the safety assessment module as the basis for the intelligent decision of the system. The experimental results demonstrate that the proposed system has good performance and great application potential.
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation
Feb 05, 2020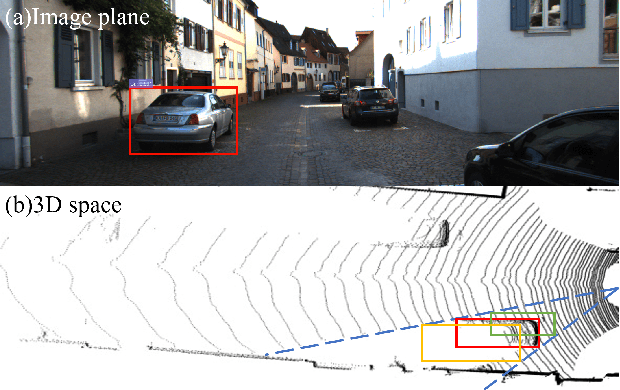
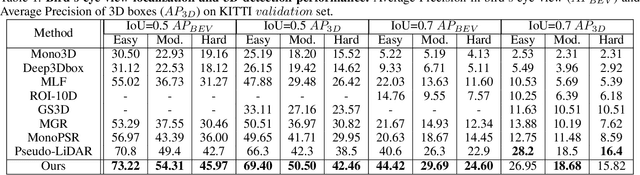
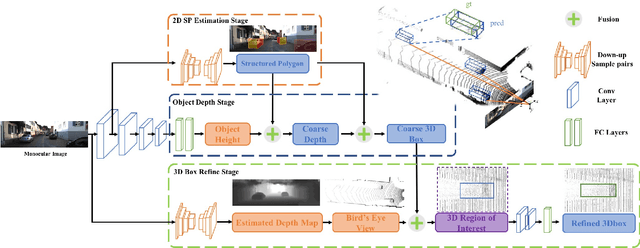
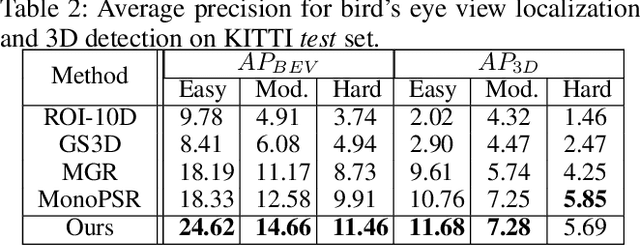
Monocular 3D object detection task aims to predict the 3D bounding boxes of objects based on monocular RGB images. Since the location recovery in 3D space is quite difficult on account of absence of depth information, this paper proposes a novel unified framework which decomposes the detection problem into a structured polygon prediction task and a depth recovery task. Different from the widely studied 2D bounding boxes, the proposed novel structured polygon in the 2D image consists of several projected surfaces of the target object. Compared to the widely-used 3D bounding box proposals, it is shown to be a better representation for 3D detection. In order to inversely project the predicted 2D structured polygon to a cuboid in the 3D physical world, the following depth recovery task uses the object height prior to complete the inverse projection transformation with the given camera projection matrix. Moreover, a fine-grained 3D box refinement scheme is proposed to further rectify the 3D detection results. Experiments are conducted on the challenging KITTI benchmark, in which our method achieves state-of-the-art detection accuracy.