 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Feb 17, 2026While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.
ViTaS: Visual Tactile Soft Fusion Contrastive Learning for Visuomotor Learning
Feb 12, 2026Tactile information plays a crucial role in human manipulation tasks and has recently garnered increasing attention in robotic manipulation. However, existing approaches mostly focus on the alignment of visual and tactile features and the integration mechanism tends to be direct concatenation. Consequently, they struggle to effectively cope with occluded scenarios due to neglecting the inherent complementary nature of both modalities and the alignment may not be exploited enough, limiting the potential of their real-world deployment. In this paper, we present ViTaS, a simple yet effective framework that incorporates both visual and tactile information to guide the behavior of an agent. We introduce Soft Fusion Contrastive Learning, an advanced version of conventional contrastive learning method and a CVAE module to utilize the alignment and complementarity within visuo-tactile representations. We demonstrate the effectiveness of our method in 12 simulated and 3 real-world environments, and our experiments show that ViTaS significantly outperforms existing baselines. Project page: https://skyrainwind.github.io/ViTaS/index.html.
RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Feb 03, 2026Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
May 30, 2025Can your humanoid walk up and hand you a full cup of beer, without spilling a drop? While humanoids are increasingly featured in flashy demos like dancing, delivering packages, traversing rough terrain, fine-grained control during locomotion remains a significant challenge. In particular, stabilizing a filled end-effector (EE) while walking is far from solved, due to a fundamental mismatch in task dynamics: locomotion demands slow-timescale, robust control, whereas EE stabilization requires rapid, high-precision corrections. To address this, we propose SoFTA, a Slow-Fast TwoAgent framework that decouples upper-body and lower-body control into separate agents operating at different frequencies and with distinct rewards. This temporal and objective separation mitigates policy interference and enables coordinated whole-body behavior. SoFTA executes upper-body actions at 100 Hz for precise EE control and lower-body actions at 50 Hz for robust gait. It reduces EE acceleration by 2-5x relative to baselines and performs much closer to human-level stability, enabling delicate tasks such as carrying nearly full cups, capturing steady video during locomotion, and disturbance rejection with EE stability.
Effective climate policies for major emission reductions of ozone precursors: Global evidence from two decades
May 20, 2025Despite policymakers deploying various tools to mitigate emissions of ozone (O\textsubscript{3}) precursors, such as nitrogen oxides (NO\textsubscript{x}), carbon monoxide (CO), and volatile organic compounds (VOCs), the effectiveness of policy combinations remains uncertain. We employ an integrated framework that couples structural break detection with machine learning to pinpoint effective interventions across the building, electricity, industrial, and transport sectors, identifying treatment effects as abrupt changes without prior assumptions about policy treatment assignment and timing. Applied to two decades of global O\textsubscript{3} precursor emissions data, we detect 78, 77, and 78 structural breaks for NO\textsubscript{x}, CO, and VOCs, corresponding to cumulative emission reductions of 0.96-0.97 Gt, 2.84-2.88 Gt, and 0.47-0.48 Gt, respectively. Sector-level analysis shows that electricity sector structural policies cut NO\textsubscript{x} by up to 32.4\%, while in buildings, developed countries combined adoption subsidies with carbon taxes to achieve 42.7\% CO reductions and developing countries used financing plus fuel taxes to secure 52.3\%. VOCs abatement peaked at 38.5\% when fossil-fuel subsidy reforms were paired with financial incentives. Finally, hybrid strategies merging non-price measures (subsidies, bans, mandates) with pricing instruments delivered up to an additional 10\% co-benefit. These findings guide the sequencing and complementarity of context-specific policy portfolios for O\textsubscript{3} precursor mitigation.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
May 10, 2025Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
Flying Hand: End-Effector-Centric Framework for Versatile Aerial Manipulation Teleoperation and Policy Learning
Apr 14, 2025Aerial manipulation has recently attracted increasing interest from both industry and academia. Previous approaches have demonstrated success in various specific tasks. However, their hardware design and control frameworks are often tightly coupled with task specifications, limiting the development of cross-task and cross-platform algorithms. Inspired by the success of robot learning in tabletop manipulation, we propose a unified aerial manipulation framework with an end-effector-centric interface that decouples high-level platform-agnostic decision-making from task-agnostic low-level control. Our framework consists of a fully-actuated hexarotor with a 4-DoF robotic arm, an end-effector-centric whole-body model predictive controller, and a high-level policy. The high-precision end-effector controller enables efficient and intuitive aerial teleoperation for versatile tasks and facilitates the development of imitation learning policies. Real-world experiments show that the proposed framework significantly improves end-effector tracking accuracy, and can handle multiple aerial teleoperation and imitation learning tasks, including writing, peg-in-hole, pick and place, changing light bulbs, etc. We believe the proposed framework provides one way to standardize and unify aerial manipulation into the general manipulation community and to advance the field. Project website: https://lecar-lab.github.io/flying_hand/.
ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
Feb 03, 2025Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
Catch It! Learning to Catch in Flight with Mobile Dexterous Hands
Sep 16, 2024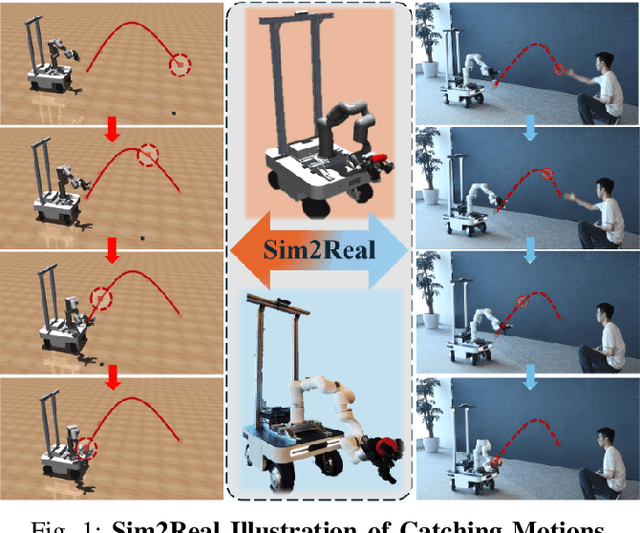

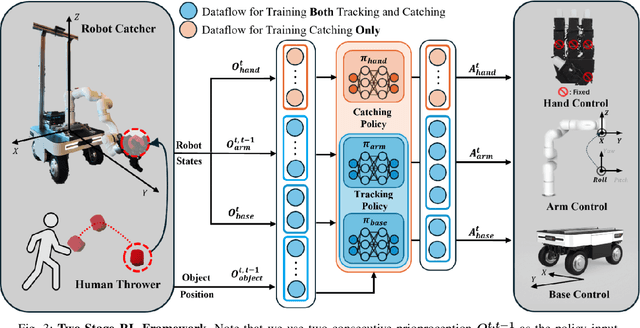
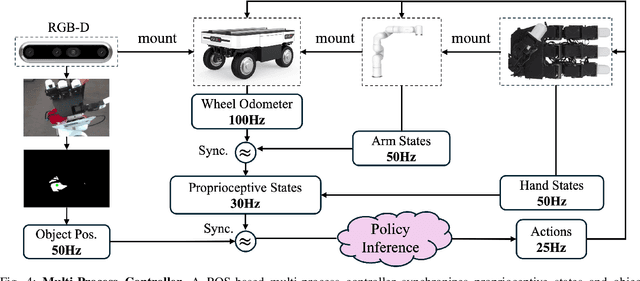
Catching objects in flight (i.e., thrown objects) is a common daily skill for humans, yet it presents a significant challenge for robots. This task requires a robot with agile and accurate motion, a large spatial workspace, and the ability to interact with diverse objects. In this paper, we build a mobile manipulator composed of a mobile base, a 6-DoF arm, and a 12-DoF dexterous hand to tackle such a challenging task. We propose a two-stage reinforcement learning framework to efficiently train a whole-body-control catching policy for this high-DoF system in simulation. The objects' throwing configurations, shapes, and sizes are randomized during training to enhance policy adaptivity to various trajectories and object characteristics in flight. The results show that our trained policy catches diverse objects with randomly thrown trajectories, at a high success rate of about 80\% in simulation, with a significant improvement over the baselines. The policy trained in simulation can be directly deployed in the real world with onboard sensing and computation, which achieves catching sandbags in various shapes, randomly thrown by humans. Our project page is available at https://mobile-dex-catch.github.io/.