 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective climate policies for major emission reductions of ozone precursors: Global evidence from two decades
May 20, 2025Despite policymakers deploying various tools to mitigate emissions of ozone (O\textsubscript{3}) precursors, such as nitrogen oxides (NO\textsubscript{x}), carbon monoxide (CO), and volatile organic compounds (VOCs), the effectiveness of policy combinations remains uncertain. We employ an integrated framework that couples structural break detection with machine learning to pinpoint effective interventions across the building, electricity, industrial, and transport sectors, identifying treatment effects as abrupt changes without prior assumptions about policy treatment assignment and timing. Applied to two decades of global O\textsubscript{3} precursor emissions data, we detect 78, 77, and 78 structural breaks for NO\textsubscript{x}, CO, and VOCs, corresponding to cumulative emission reductions of 0.96-0.97 Gt, 2.84-2.88 Gt, and 0.47-0.48 Gt, respectively. Sector-level analysis shows that electricity sector structural policies cut NO\textsubscript{x} by up to 32.4\%, while in buildings, developed countries combined adoption subsidies with carbon taxes to achieve 42.7\% CO reductions and developing countries used financing plus fuel taxes to secure 52.3\%. VOCs abatement peaked at 38.5\% when fossil-fuel subsidy reforms were paired with financial incentives. Finally, hybrid strategies merging non-price measures (subsidies, bans, mandates) with pricing instruments delivered up to an additional 10\% co-benefit. These findings guide the sequencing and complementarity of context-specific policy portfolios for O\textsubscript{3} precursor mitigation.
PuLID: Pure and Lightning ID Customization via Contrastive Alignment
Apr 24, 2024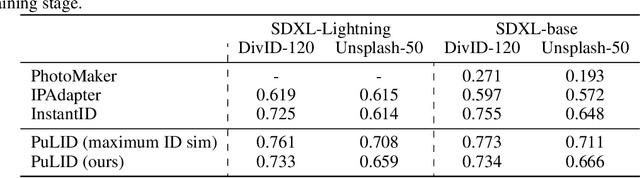
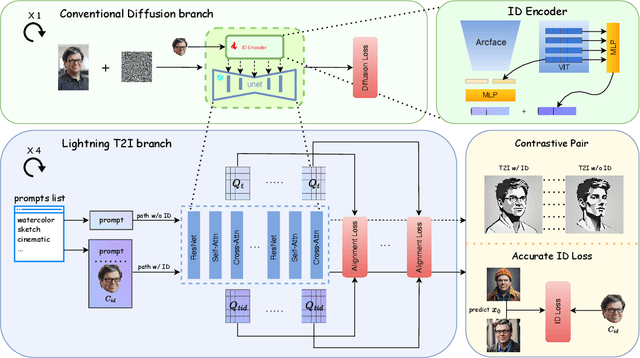
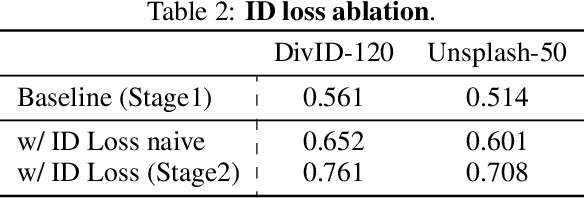

We propose Pure and Lightning ID customization (PuLID), a novel tuning-free ID customization method for text-to-image generation. By incorporating a Lightning T2I branch with a standard diffusion one, PuLID introduces both contrastive alignment loss and accurate ID loss, minimizing disruption to the original model and ensuring high ID fidelity. Experiments show that PuLID achieves superior performance in both ID fidelity and editability. Another attractive property of PuLID is that the image elements (e.g., background, lighting, composition, and style) before and after the ID insertion are kept as consistent as possible. Codes and models will be available at https://github.com/ToTheBeginning/PuLID
DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Mar 12, 2024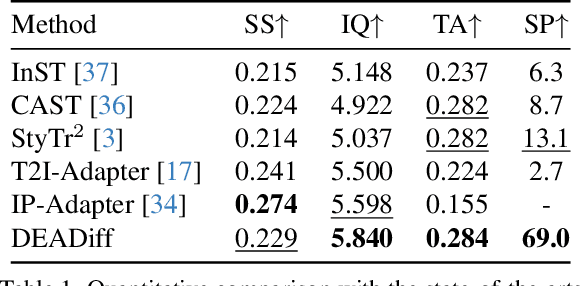
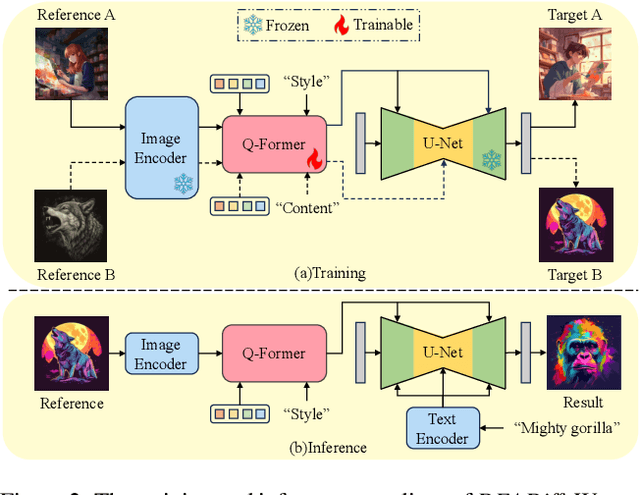
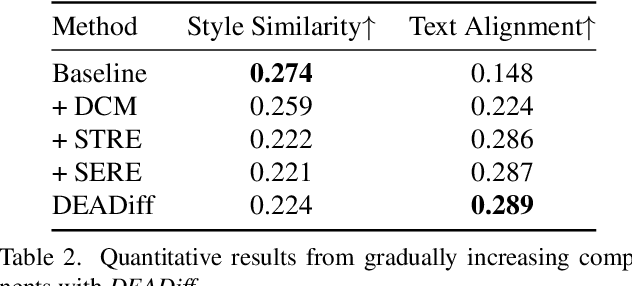
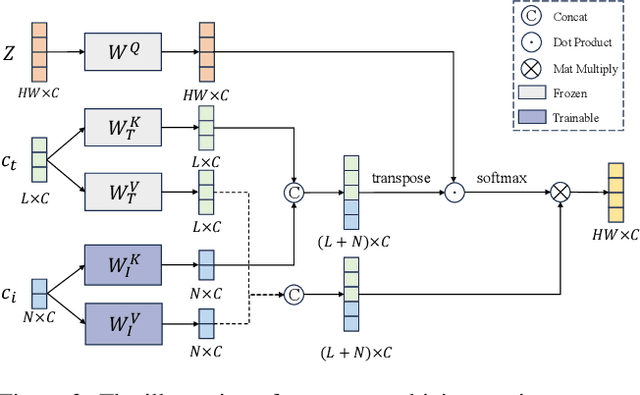
The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively. Our project page is https://tianhao-qi.github.io/DEADiff/.