 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Expert Intuition into Quantifiable Features: Encode Investigator Domain Knowledge via LLM for Enhanced Predictive Analytics
May 11, 2024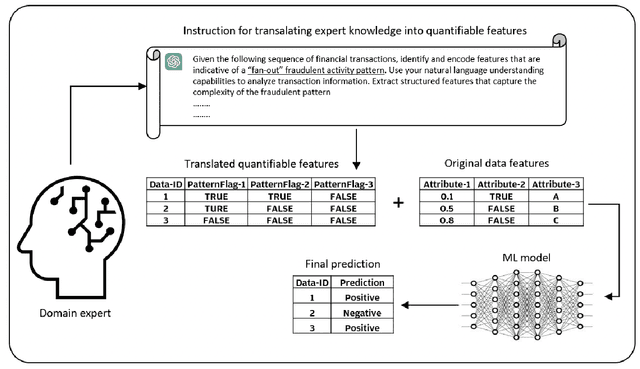
In the realm of predictive analytics, the nuanced domain knowledge of investigators often remains underutilized, confined largely to subjective interpretations and ad hoc decision-making. This paper explores the potential of Large Language Models (LLMs) to bridge this gap by systematically converting investigator-derived insights into quantifiable, actionable features that enhance model performance. We present a framework that leverages LLMs' natural language understanding capabilities to encode these red flags into a structured feature set that can be readily integrated into existing predictive models. Through a series of case studies, we demonstrate how this approach not only preserves the critical human expertise within the investigative process but also scales the impact of this knowledge across various prediction tasks. The results indicate significant improvements in risk assessment and decision-making accuracy, highlighting the value of blending human experiential knowledge with advanced machine learning techniques. This study paves the way for more sophisticated, knowledge-driven analytics in fields where expert insight is paramount.
A Customer Level Fraudulent Activity Detection Benchmark for Enhancing Machine Learning Model Research and Evaluation
Apr 23, 2024In the field of fraud detection, the availability of comprehensive and privacy-compliant datasets is crucial for advancing machine learning research and developing effective anti-fraud systems. Traditional datasets often focus on transaction-level information, which, while useful, overlooks the broader context of customer behavior patterns that are essential for detecting sophisticated fraud schemes. The scarcity of such data, primarily due to privacy concerns, significantly hampers the development and testing of predictive models that can operate effectively at the customer level. Addressing this gap, our study introduces a benchmark that contains structured datasets specifically designed for customer-level fraud detection. The benchmark not only adheres to strict privacy guidelines to ensure user confidentiality but also provides a rich source of information by encapsulating customer-centric features. We have developed the benchmark that allows for the comprehensive evaluation of various machine learning models, facilitating a deeper understanding of their strengths and weaknesses in predicting fraudulent activities. Through this work, we seek to bridge the existing gap in data availability, offering researchers and practitioners a valuable resource that empowers the development of next-generation fraud detection techniques.
Efficient Hierarchical Bayesian Inference for Spatio-temporal Regression Models in Neuroimaging
Nov 23, 2021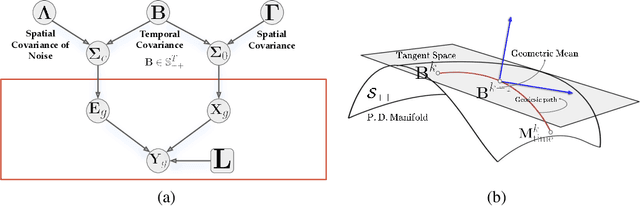
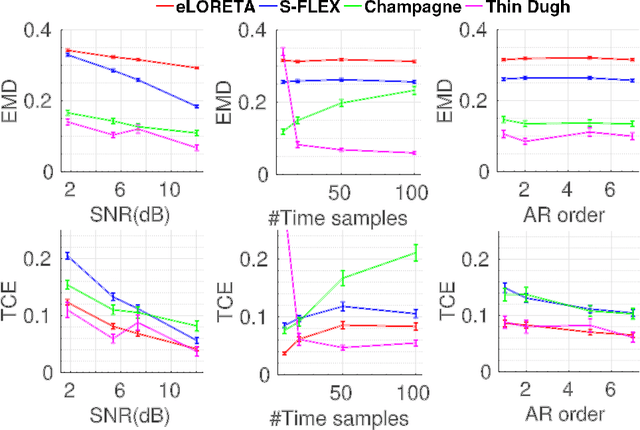
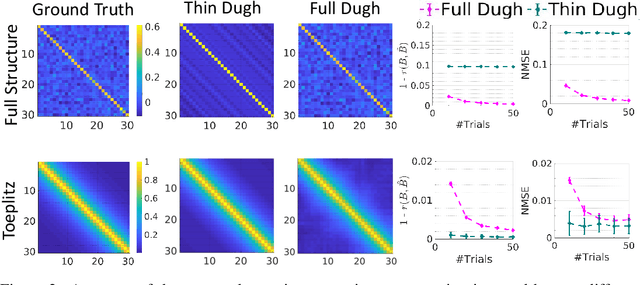
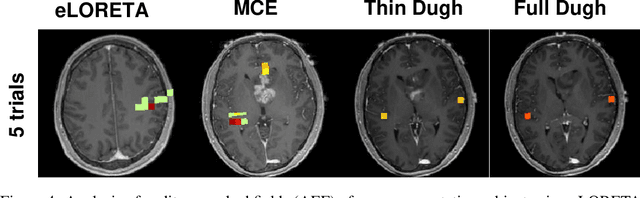
Several problems in neuroimaging and beyond require inference on the parameters of multi-task sparse hierarchical regression models. Examples include M/EEG inverse problems, neural encoding models for task-based fMRI analyses, and climate science. In these domains, both the model parameters to be inferred and the measurement noise may exhibit a complex spatio-temporal structure. Existing work either neglects the temporal structure or leads to computationally demanding inference schemes. Overcoming these limitations, we devise a novel flexible hierarchical Bayesian framework within which the spatio-temporal dynamics of model parameters and noise are modeled to have Kronecker product covariance structure. Inference in our framework is based on majorization-minimization optimization and has guaranteed convergence properties. Our highly efficient algorithms exploit the intrinsic Riemannian geometry of temporal autocovariance matrices. For stationary dynamics described by Toeplitz matrices, the theory of circulant embeddings is employed. We prove convex bounding properties and derive update rules of the resulting algorithms. On both synthetic and real neural data from M/EEG, we demonstrate that our methods lead to improved performance.