 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-SPIN: Multi-Access Speculative Inference for Cooperative Token Generation at the Edge
Jun 03, 2026Speculative inference (SPIN) was originally developed as an efficient architecture to accelerate Large Language Models (LLMs). In this work, we propose its distributed deployment to enable cooperative token generation in a multiuser edge system; its advantage is to effectively balance computational loads between resource-constrained devices and servers. The resulting architecture, termed Multi-access SPIN (Multi-SPIN), utilizes on-device small language models to generate and upload candidate token drafts, while an edge server operates the LLM to verify them in parallel batches. Given the severe heterogeneity in users' computation and communication capabilities, the draft length emerges as a critical control variable that influences node-level computation loads and multi-access latency, thereby governing the sum token goodput. Consequently, considering frequency-division multiple access, we investigate the problem of multi-access draft control, a joint optimization of draft-length control and bandwidth allocation to maximize sum token goodput. We examine two cases: (1) homogeneous draft lengths across users to facilitate server-side batching, and (2) heterogeneous draft lengths to introduce a new dimension for goodput enhancement. By developing decomposition methods, we reduce these complex optimizations into tractable sub-problems, which allow efficient draft control algorithms to be derived in closed form. Our analysis shows that the optimal bandwidth allocation compensates users with weaker computation-and-communication capabilities in the homogeneous case due to the batching synchronization requirements, whereas its heterogeneous-case counterpart rewards users with higher acceptance rates by relaxing such requirements. Experiments using Llama-2 and Qwen3.5 model pairs across diverse tasks demonstrate that Multi-SPIN improves goodput by up to 88% over heterogeneity-agnostic baselines.
Score-Based Turbo Message Passing for Plug-and-Play Compressive Image Recovery
Mar 28, 2025



Message passing algorithms have been tailored for compressive imaging applications by plugging in different types of off-the-shelf image denoisers. These off-the-shelf denoisers mostly rely on some generic or hand-crafted priors for denoising. Due to their insufficient accuracy in capturing the true image prior, these methods often fail to produce satisfactory results, especially in largely underdetermined scenarios. On the other hand, score-based generative modeling offers a promising way to accurately characterize the sophisticated image distribution. In this paper, by exploiting the close relation between score-based modeling and empirical Bayes-optimal denoising, we devise a message passing framework that integrates a score-based minimum mean squared error (MMSE) denoiser for compressive image recovery. This framework is firmly rooted in Bayesian formalism, in which state evolution (SE) equations accurately predict its asymptotic performance. Experiments on the FFHQ dataset demonstrate that our method strikes a significantly better performance-complexity tradeoff than conventional message passing, regularized linear regression, and score-based posterior sampling baselines. Remarkably, our method typically requires less than 20 neural function evaluations (NFEs) to converge.
RoboReflect: Robotic Reflective Reasoning for Grasping Ambiguous-Condition Objects
Jan 16, 2025



As robotic technology rapidly develops, robots are being employed in an increasing number of fields. However, due to the complexity of deployment environments or the prevalence of ambiguous-condition objects, the practical application of robotics still faces many challenges, leading to frequent errors. Traditional methods and some LLM-based approaches, although improved, still require substantial human intervention and struggle with autonomous error correction in complex scenarios.In this work, we propose RoboReflect, a novel framework leveraging large vision-language models (LVLMs) to enable self-reflection and autonomous error correction in robotic grasping tasks. RoboReflect allows robots to automatically adjust their strategies based on unsuccessful attempts until successful execution is achieved.The corrected strategies are saved in a memory for future task reference.We evaluate RoboReflect through extensive testing on eight common objects prone to ambiguous conditions of three categories.Our results demonstrate that RoboReflect not only outperforms existing grasp pose estimation methods like AnyGrasp and high-level action planning techniques using GPT-4V but also significantly enhances the robot's ability to adapt and correct errors independently. These findings underscore the critical importance of autonomous selfreflection in robotic systems while effectively addressing the challenges posed by ambiguous environments.
"My Grade is Wrong!": A Contestable AI Framework for Interactive Feedback in Evaluating Student Essays
Sep 11, 2024



Interactive feedback, where feedback flows in both directions between teacher and student, is more effective than traditional one-way feedback. However, it is often too time-consuming for widespread use in educational practice. While Large Language Models (LLMs) have potential for automating feedback, they struggle with reasoning and interaction in an interactive setting. This paper introduces CAELF, a Contestable AI Empowered LLM Framework for automating interactive feedback. CAELF allows students to query, challenge, and clarify their feedback by integrating a multi-agent system with computational argumentation. Essays are first assessed by multiple Teaching-Assistant Agents (TA Agents), and then a Teacher Agent aggregates the evaluations through formal reasoning to generate feedback and grades. Students can further engage with the feedback to refine their understanding. A case study on 500 critical thinking essays with user studies demonstrates that CAELF significantly improves interactive feedback, enhancing the reasoning and interaction capabilities of LLMs. This approach offers a promising solution to overcoming the time and resource barriers that have limited the adoption of interactive feedback in educational settings.
End-to-End Learning for Task-Oriented Semantic Communications Over MIMO Channels: An Information-Theoretic Framework
Aug 30, 2024



This paper addresses the problem of end-to-end (E2E) design of learning and communication in a task-oriented semantic communication system. In particular, we consider a multi-device cooperative edge inference system over a wireless multiple-input multiple-output (MIMO) multiple access channel, where multiple devices transmit extracted features to a server to perform a classification task. We formulate the E2E design of feature encoding, MIMO precoding, and classification as a conditional mutual information maximization problem. However, it is notoriously difficult to design and train an E2E network that can be adaptive to both the task dataset and different channel realizations. Regarding network training, we propose a decoupled pretraining framework that separately trains the feature encoder and the MIMO precoder, with a maximum a posteriori (MAP) classifier employed at the server to generate the inference result. The feature encoder is pretrained exclusively using the task dataset, while the MIMO precoder is pretrained solely based on the channel and noise distributions. Nevertheless, we manage to align the pretraining objectives of each individual component with the E2E learning objective, so as to approach the performance bound of E2E learning. By leveraging the decoupled pretraining results for initialization, the E2E learning can be conducted with minimal training overhead. Regarding network architecture design, we develop two deep unfolded precoding networks that effectively incorporate the domain knowledge of the solution to the decoupled precoding problem. Simulation results on both the CIFAR-10 and ModelNet10 datasets verify that the proposed method achieves significantly higher classification accuracy compared to various baselines.
All Robots in One: A New Standard and Unified Dataset for Versatile, General-Purpose Embodied Agents
Aug 20, 2024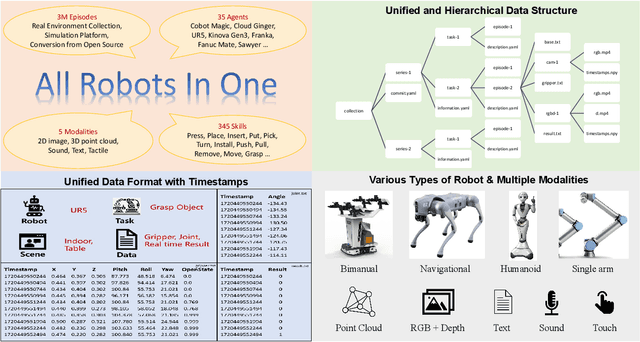

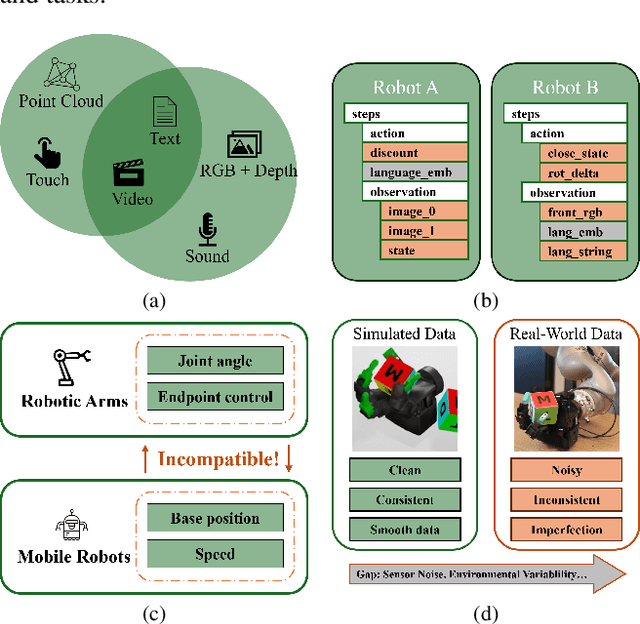
Embodied AI is transforming how AI systems interact with the physical world, yet existing datasets are inadequate for developing versatile, general-purpose agents. These limitations include a lack of standardized formats, insufficient data diversity, and inadequate data volume. To address these issues, we introduce ARIO (All Robots In One), a new data standard that enhances existing datasets by offering a unified data format, comprehensive sensory modalities, and a combination of real-world and simulated data. ARIO aims to improve the training of embodied AI agents, increasing their robustness and adaptability across various tasks and environments. Building upon the proposed new standard, we present a large-scale unified ARIO dataset, comprising approximately 3 million episodes collected from 258 series and 321,064 tasks. The ARIO standard and dataset represent a significant step towards bridging the gaps of existing data resources. By providing a cohesive framework for data collection and representation, ARIO paves the way for the development of more powerful and versatile embodied AI agents, capable of navigating and interacting with the physical world in increasingly complex and diverse ways. The project is available on https://imaei.github.io/project_pages/ario/
Multi-Device Task-Oriented Communication via Maximal Coding Rate Reduction
Sep 06, 2023



Task-oriented communication offers ample opportunities to alleviate the communication burden in next-generation wireless networks. Most existing work designed the physical-layer communication modules and learning-based codecs with distinct objectives: learning is targeted at accurate execution of specific tasks, while communication aims at optimizing conventional communication metrics, such as throughput maximization, delay minimization, or bit error rate minimization. The inconsistency between the design objectives may hinder the exploitation of the full benefits of task-oriented communications. In this paper, we consider a specific task-oriented communication system for multi-device edge inference over a multiple-input multiple-output (MIMO) multiple-access channel, where the learning (i.e., feature encoding and classification) and communication (i.e., precoding) modules are designed with the same goal of inference accuracy maximization. Instead of end-to-end learning which involves both the task dataset and wireless channel during training, we advocate a separate design of learning and communication to achieve the consistent goal. Specifically, we leverage the maximal coding rate reduction (MCR2) objective as a surrogate to represent the inference accuracy, which allows us to explicitly formulate the precoding optimization problem. We cast valuable insights into this formulation and develop a block coordinate descent (BCD) solution algorithm. Moreover, the MCR2 objective also serves the loss function of the feature encoding network, based on which we characterize the received features as a Gaussian mixture (GM) model, facilitating a maximum a posteriori (MAP) classifier to infer the result. Simulation results on both the synthetic and real-world datasets demonstrate the superior performance of the proposed method compared to various baselines.
RIS Partitioning Based Scalable Beamforming Design for Large-Scale MIMO: Asymptotic Analysis and Optimization
Mar 16, 2022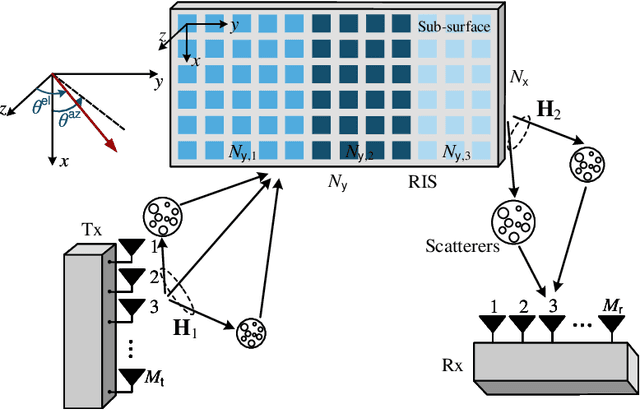
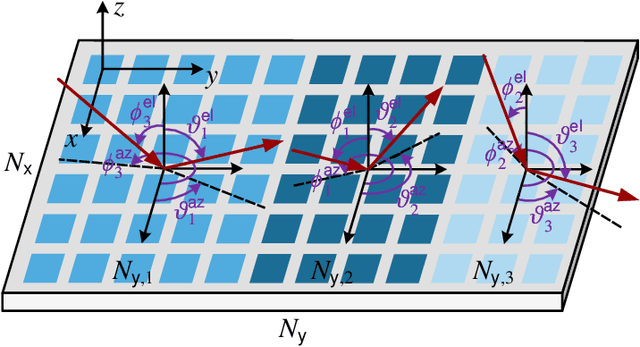
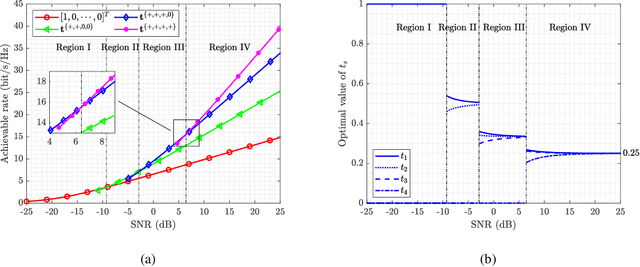
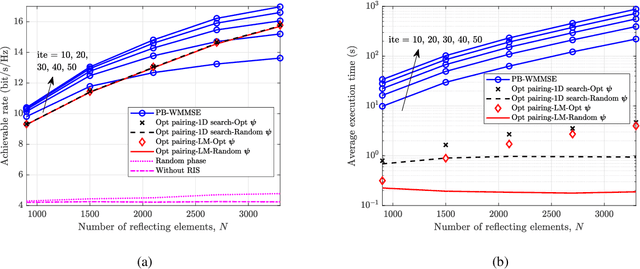
In next-generation wireless networks, reconfigurable intelligent surface (RIS)-assisted multiple-input multiple-output (MIMO) systems are foreseeable to support a large number of antennas at the transceiver as well as a large number of reflecting elements at the RIS. To fully unleash the potential of RIS, the phase shifts of RIS elements should be carefully designed, resulting in a high-dimensional non-convex optimization problem that is hard to solve with affordable computational complexity. In this paper, we address this scalability issue by partitioning RIS into sub-surfaces, so as to optimize the phase shifts in sub-surface levels to reduce complexity. Specifically, each sub-surface employs a linear phase variation structure to anomalously reflect the incident signal to a desired direction, and the sizes of sub-surfaces can be adaptively adjusted according to channel conditions. We formulate the achievable rate maximization problem by jointly optimizing the transmit covariance matrix and the RIS phase shifts. Then, we characterize the asymptotic behavior of the system with an infinitely large number of transceiver antennas and RIS elements. The asymptotic analysis provides useful insights on the understanding of the fundamental performance-complexity tradeoff in RIS partitioning design. We show that the achievable rate maximization problem has a rather simple form in the asymptotic regime, and we develop an efficient algorithm to find the optimal solution via one-dimensional (1D) search. Moreover, we discuss the insights and impacts of the asymptotically optimal solution on finite-size system design. By applying the asymptotic result to a finite-size system with necessary modifications, we show by numerical results that the proposed design achieves a favorable tradeoff between system performance and computational complexity.
Efficient Hierarchical Bayesian Inference for Spatio-temporal Regression Models in Neuroimaging
Nov 23, 2021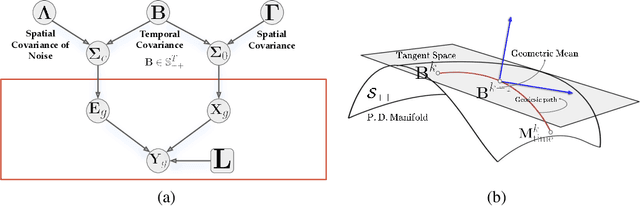
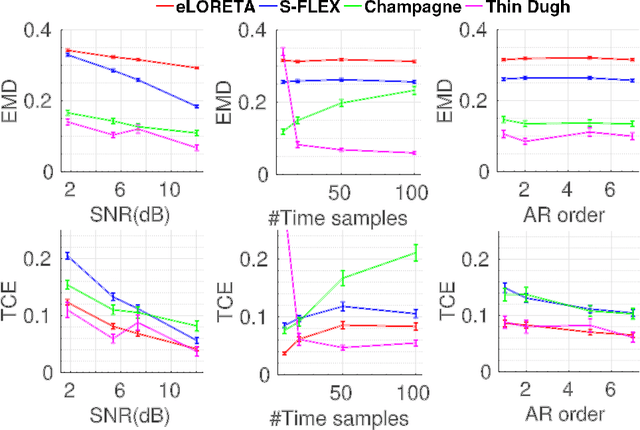
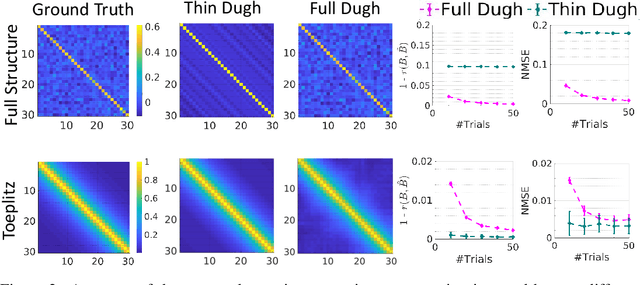
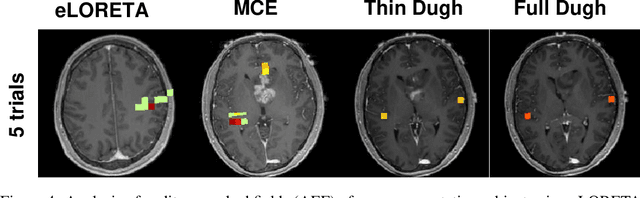
Several problems in neuroimaging and beyond require inference on the parameters of multi-task sparse hierarchical regression models. Examples include M/EEG inverse problems, neural encoding models for task-based fMRI analyses, and climate science. In these domains, both the model parameters to be inferred and the measurement noise may exhibit a complex spatio-temporal structure. Existing work either neglects the temporal structure or leads to computationally demanding inference schemes. Overcoming these limitations, we devise a novel flexible hierarchical Bayesian framework within which the spatio-temporal dynamics of model parameters and noise are modeled to have Kronecker product covariance structure. Inference in our framework is based on majorization-minimization optimization and has guaranteed convergence properties. Our highly efficient algorithms exploit the intrinsic Riemannian geometry of temporal autocovariance matrices. For stationary dynamics described by Toeplitz matrices, the theory of circulant embeddings is employed. We prove convex bounding properties and derive update rules of the resulting algorithms. On both synthetic and real neural data from M/EEG, we demonstrate that our methods lead to improved performance.
Graph Neural Networks for UnsupervisedDomain Adaptation of Histopathological ImageAnalytics
Aug 21, 2020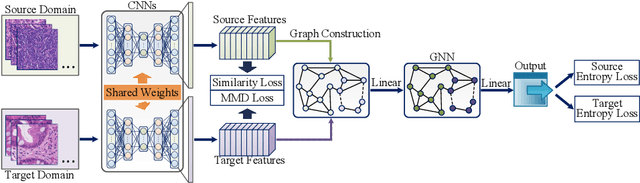

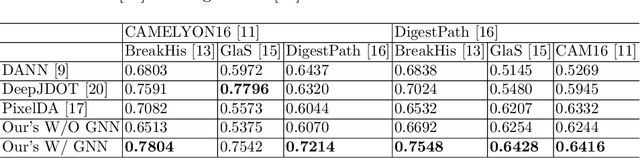
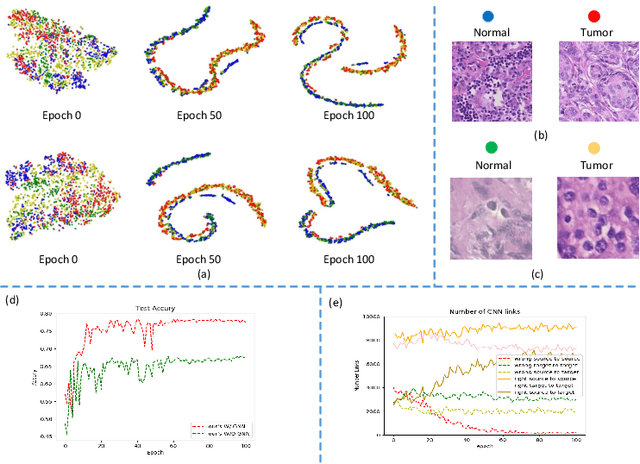
Annotating histopathological images is a time-consuming andlabor-intensive process, which requires broad-certificated pathologistscarefully examining large-scale whole-slide images from cells to tissues.Recent frontiers of transfer learning techniques have been widely investi-gated for image understanding tasks with limited annotations. However,when applied for the analytics of histology images, few of them can effec-tively avoid the performance degradation caused by the domain discrep-ancy between the source training dataset and the target dataset, suchas different tissues, staining appearances, and imaging devices. To thisend, we present a novel method for the unsupervised domain adaptationin histopathological image analysis, based on a backbone for embeddinginput images into a feature space, and a graph neural layer for propa-gating the supervision signals of images with labels. The graph model isset up by connecting every image with its close neighbors in the embed-ded feature space. Then graph neural network is employed to synthesizenew feature representation from every image. During the training stage,target samples with confident inferences are dynamically allocated withpseudo labels. The cross-entropy loss function is used to constrain thepredictions of source samples with manually marked labels and targetsamples with pseudo labels. Furthermore, the maximum mean diversityis adopted to facilitate the extraction of domain-invariant feature repre-sentations, and contrastive learning is exploited to enhance the categorydiscrimination of learned features. In experiments of the unsupervised do-main adaptation for histopathological image classification, our methodachieves state-of-the-art performance on four public datasets