 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Uncertainty Estimation under Distribution Shift via Difference Reconstruction
Jan 27, 2026Estimating uncertainty in deep learning models is critical for reliable decision-making in high-stakes applications such as medical imaging. Prior research has established that the difference between an input sample and its reconstructed version produced by an auxiliary model can serve as a useful proxy for uncertainty. However, directly comparing reconstructions with the original input is degraded by information loss and sensitivity to superficial details, which limits its effectiveness. In this work, we propose Difference Reconstruction Uncertainty Estimation (DRUE), a method that mitigates this limitation by reconstructing inputs from two intermediate layers and measuring the discrepancy between their outputs as the uncertainty score. To evaluate uncertainty estimation in practice, we follow the widely used out-of-distribution (OOD) detection paradigm, where in-distribution (ID) training data are compared against datasets with increasing domain shift. Using glaucoma detection as the ID task, we demonstrate that DRUE consistently achieves superior AUC and AUPR across multiple OOD datasets, highlighting its robustness and reliability under distribution shift. This work provides a principled and effective framework for enhancing model reliability in uncertain environments.
Provably Robust Bayesian Counterfactual Explanations under Model Changes
Jan 23, 2026Counterfactual explanations (CEs) offer interpretable insights into machine learning predictions by answering ``what if?" questions. However, in real-world settings where models are frequently updated, existing counterfactual explanations can quickly become invalid or unreliable. In this paper, we introduce Probabilistically Safe CEs (PSCE), a method for generating counterfactual explanations that are $δ$-safe, to ensure high predictive confidence, and $ε$-robust to ensure low predictive variance. Based on Bayesian principles, PSCE provides formal probabilistic guarantees for CEs under model changes which are adhered to in what we refer to as the $\langle δ, ε\rangle$-set. Uncertainty-aware constraints are integrated into our optimization framework and we validate our method empirically across diverse datasets. We compare our approach against state-of-the-art Bayesian CE methods, where PSCE produces counterfactual explanations that are not only more plausible and discriminative, but also provably robust under model change.
"My Grade is Wrong!": A Contestable AI Framework for Interactive Feedback in Evaluating Student Essays
Sep 11, 2024



Interactive feedback, where feedback flows in both directions between teacher and student, is more effective than traditional one-way feedback. However, it is often too time-consuming for widespread use in educational practice. While Large Language Models (LLMs) have potential for automating feedback, they struggle with reasoning and interaction in an interactive setting. This paper introduces CAELF, a Contestable AI Empowered LLM Framework for automating interactive feedback. CAELF allows students to query, challenge, and clarify their feedback by integrating a multi-agent system with computational argumentation. Essays are first assessed by multiple Teaching-Assistant Agents (TA Agents), and then a Teacher Agent aggregates the evaluations through formal reasoning to generate feedback and grades. Students can further engage with the feedback to refine their understanding. A case study on 500 critical thinking essays with user studies demonstrates that CAELF significantly improves interactive feedback, enhancing the reasoning and interaction capabilities of LLMs. This approach offers a promising solution to overcoming the time and resource barriers that have limited the adoption of interactive feedback in educational settings.
QUCE: The Minimisation and Quantification of Path-Based Uncertainty for Generative Counterfactual Explanations
Mar 14, 2024Deep Neural Networks (DNNs) stand out as one of the most prominent approaches within the Machine Learning (ML) domain. The efficacy of DNNs has surged alongside recent increases in computational capacity, allowing these approaches to scale to significant complexities for addressing predictive challenges in big data. However, as the complexity of DNN models rises, interpretability diminishes. In response to this challenge, explainable models such as Adversarial Gradient Integration (AGI) leverage path-based gradients provided by DNNs to elucidate their decisions. Yet the performance of path-based explainers can be compromised when gradients exhibit irregularities during out-of-distribution path traversal. In this context, we introduce Quantified Uncertainty Counterfactual Explanations (QUCE), a method designed to mitigate out-of-distribution traversal by minimizing path uncertainty. QUCE not only quantifies uncertainty when presenting explanations but also generates more certain counterfactual examples. We showcase the performance of the QUCE method by comparing it with competing methods for both path-based explanations and generative counterfactual examples. The code repository for the QUCE method is available at: https://github.com/jamie-duell/QUCE.
Stock Price Predictability and the Business Cycle via Machine Learning
Apr 06, 2023We study the impacts of business cycles on machine learning (ML) predictions. Using the S&P 500 index, we find that ML models perform worse during most recessions, and the inclusion of recession history or the risk-free rate does not necessarily improve their performance. Investigating recessions where models perform well, we find that they exhibit lower market volatility than other recessions. This implies that the improved performance is not due to the merit of ML methods but rather factors such as effective monetary policies that stabilized the market. We recommend that ML practitioners evaluate their models during both recessions and expansions.
On Understanding the Influence of Controllable Factors with a Feature Attribution Algorithm: a Medical Case Study
Mar 23, 2022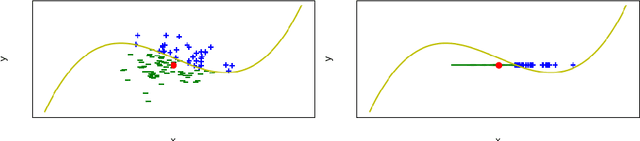
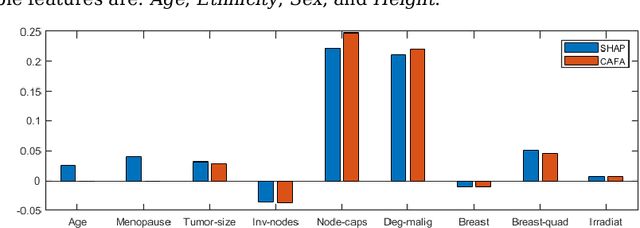
Feature attribution XAI algorithms enable their users to gain insight into the underlying patterns of large datasets through their feature importance calculation. Existing feature attribution algorithms treat all features in a dataset homogeneously, which may lead to misinterpretation of consequences of changing feature values. In this work, we consider partitioning features into controllable and uncontrollable parts and propose the Controllable fActor Feature Attribution (CAFA) approach to compute the relative importance of controllable features. We carried out experiments applying CAFA to two existing datasets and our own COVID-19 non-pharmaceutical control measures dataset. Experimental results show that with CAFA, we are able to exclude influences from uncontrollable features in our explanation while keeping the full dataset for prediction.
Explainable Decision Making with Lean and Argumentative Explanations
Jan 24, 2022



It is widely acknowledged that transparency of automated decision making is crucial for deployability of intelligent systems, and explaining the reasons why some decisions are "good" and some are not is a way to achieving this transparency. We consider two variants of decision making, where "good" decisions amount to alternatives (i) meeting "most" goals, and (ii) meeting "most preferred" goals. We then define, for each variant and notion of "goodness" (corresponding to a number of existing notions in the literature), explanations in two formats, for justifying the selection of an alternative to audiences with differing needs and competences: lean explanations, in terms of goals satisfied and, for some notions of "goodness", alternative decisions, and argumentative explanations, reflecting the decision process leading to the selection, while corresponding to the lean explanations. To define argumentative explanations, we use assumption-based argumentation (ABA), a well-known form of structured argumentation. Specifically, we define ABA frameworks such that "good" decisions are admissible ABA arguments and draw argumentative explanations from dispute trees sanctioning this admissibility. Finally, we instantiate our overall framework for explainable decision-making to accommodate connections between goals and decisions in terms of decision graphs incorporating defeasible and non-defeasible information.
Towards a Shapley Value Graph Framework for Medical peer-influence
Dec 29, 2021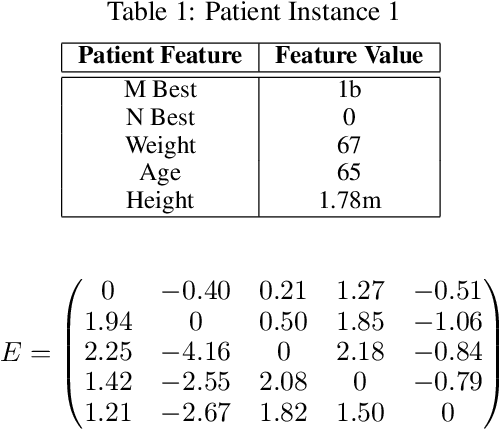



eXplainable Artificial Intelligence (XAI) is a sub-field of Artificial Intelligence (AI) that is at the forefront of AI research. In XAI feature attribution methods produce explanations in the form of feature importance. A limitation of existing feature attribution methods is that there is a lack of explanation towards the consequence of intervention. Although contribution towards a certain prediction is highlighted, the influence between features and the consequence of intervention is not addressed. The aim of this paper is to introduce a new framework to look deeper into explanations using graph representation for feature-to-feature interactions to improve the interpretability of black-box Machine Learning (ML) models and inform intervention.
Evaluating the Correctness of Explainable AI Algorithms for Classification
May 20, 2021

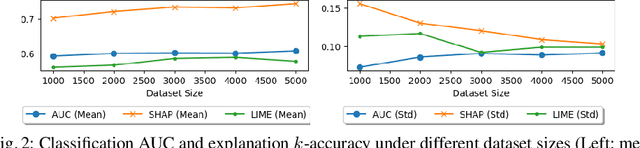
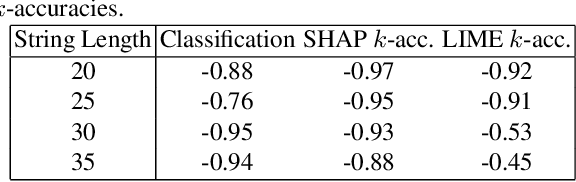
Explainable AI has attracted much research attention in recent years with feature attribution algorithms, which compute "feature importance" in predictions, becoming increasingly popular. However, there is little analysis of the validity of these algorithms as there is no "ground truth" in the existing datasets to validate their correctness. In this work, we develop a method to quantitatively evaluate the correctness of XAI algorithms by creating datasets with known explanation ground truth. To this end, we focus on the binary classification problems. String datasets are constructed using formal language derived from a grammar. A string is positive if and only if a certain property is fulfilled. Symbols serving as explanation ground truth in a positive string are part of an explanation if and only if they contributes to fulfilling the property. Two popular feature attribution explainers, Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP), are used in our experiments.We show that: (1) classification accuracy is positively correlated with explanation accuracy; (2) SHAP provides more accurate explanations than LIME; (3) explanation accuracy is negatively correlated with dataset complexity.
An Investigation of COVID-19 Spreading Factors with Explainable AI Techniques
May 05, 2020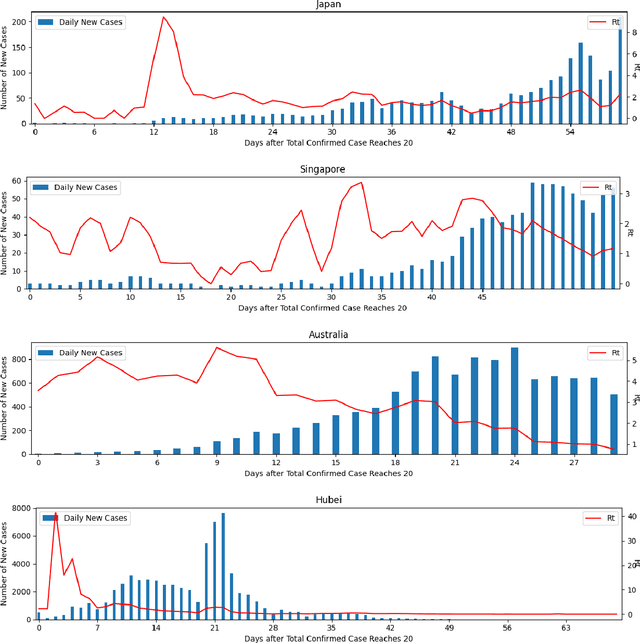
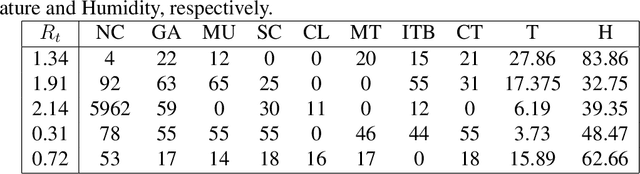
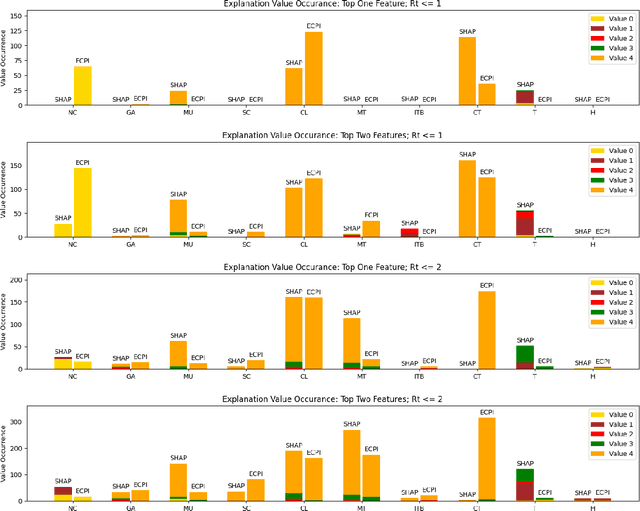
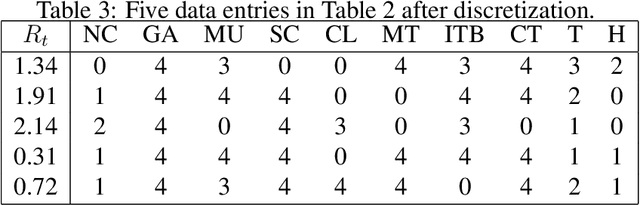
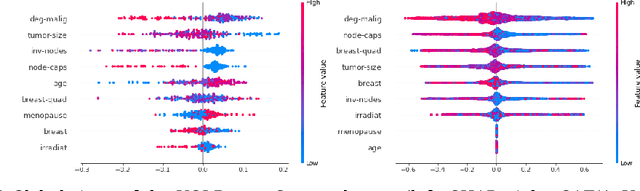
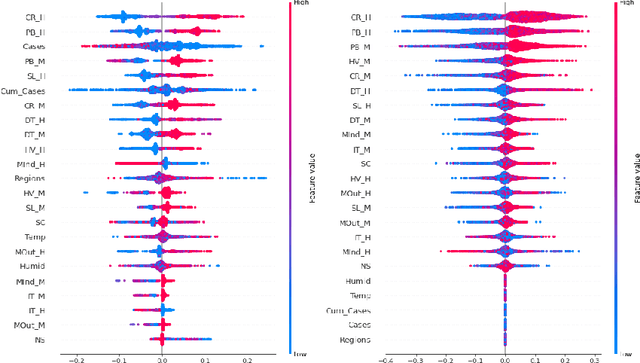
Since COVID-19 was first identified in December 2019, various public health interventions have been implemented across the world. As different measures are implemented at different countries at different times, we conduct an assessment of the relative effectiveness of the measures implemented in 18 countries and regions using data from 22/01/2020 to 02/04/2020. We compute the top one and two measures that are most effective for the countries and regions studied during the period. Two Explainable AI techniques, SHAP and ECPI, are used in our study; such that we construct (machine learning) models for predicting the instantaneous reproduction number ($R_t$) and use the models as surrogates to the real world and inputs that the greatest influence to our models are seen as measures that are most effective. Across-the-board, city lockdown and contact tracing are the two most effective measures. For ensuring $R_t<1$, public wearing face masks is also important. Mass testing alone is not the most effective measure although when paired with other measures, it can be effective. Warm temperature helps for reducing the transmission.