 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Robust Bayesian Counterfactual Explanations under Model Changes
Jan 23, 2026Counterfactual explanations (CEs) offer interpretable insights into machine learning predictions by answering ``what if?" questions. However, in real-world settings where models are frequently updated, existing counterfactual explanations can quickly become invalid or unreliable. In this paper, we introduce Probabilistically Safe CEs (PSCE), a method for generating counterfactual explanations that are $δ$-safe, to ensure high predictive confidence, and $ε$-robust to ensure low predictive variance. Based on Bayesian principles, PSCE provides formal probabilistic guarantees for CEs under model changes which are adhered to in what we refer to as the $\langle δ, ε\rangle$-set. Uncertainty-aware constraints are integrated into our optimization framework and we validate our method empirically across diverse datasets. We compare our approach against state-of-the-art Bayesian CE methods, where PSCE produces counterfactual explanations that are not only more plausible and discriminative, but also provably robust under model change.
QUCE: The Minimisation and Quantification of Path-Based Uncertainty for Generative Counterfactual Explanations
Mar 14, 2024Deep Neural Networks (DNNs) stand out as one of the most prominent approaches within the Machine Learning (ML) domain. The efficacy of DNNs has surged alongside recent increases in computational capacity, allowing these approaches to scale to significant complexities for addressing predictive challenges in big data. However, as the complexity of DNN models rises, interpretability diminishes. In response to this challenge, explainable models such as Adversarial Gradient Integration (AGI) leverage path-based gradients provided by DNNs to elucidate their decisions. Yet the performance of path-based explainers can be compromised when gradients exhibit irregularities during out-of-distribution path traversal. In this context, we introduce Quantified Uncertainty Counterfactual Explanations (QUCE), a method designed to mitigate out-of-distribution traversal by minimizing path uncertainty. QUCE not only quantifies uncertainty when presenting explanations but also generates more certain counterfactual examples. We showcase the performance of the QUCE method by comparing it with competing methods for both path-based explanations and generative counterfactual examples. The code repository for the QUCE method is available at: https://github.com/jamie-duell/QUCE.
Towards a Shapley Value Graph Framework for Medical peer-influence
Dec 29, 2021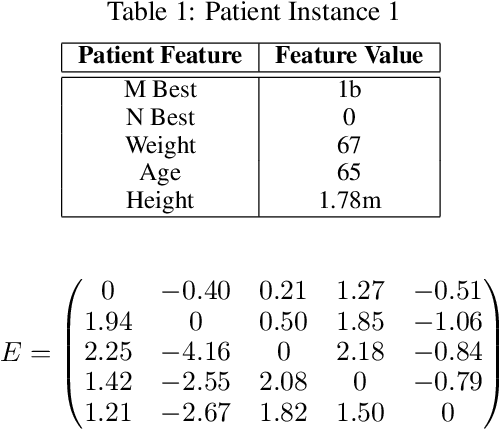



eXplainable Artificial Intelligence (XAI) is a sub-field of Artificial Intelligence (AI) that is at the forefront of AI research. In XAI feature attribution methods produce explanations in the form of feature importance. A limitation of existing feature attribution methods is that there is a lack of explanation towards the consequence of intervention. Although contribution towards a certain prediction is highlighted, the influence between features and the consequence of intervention is not addressed. The aim of this paper is to introduce a new framework to look deeper into explanations using graph representation for feature-to-feature interactions to improve the interpretability of black-box Machine Learning (ML) models and inform intervention.