 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Correctness of Explainable AI Algorithms for Classification
Paper and Code
May 20, 2021

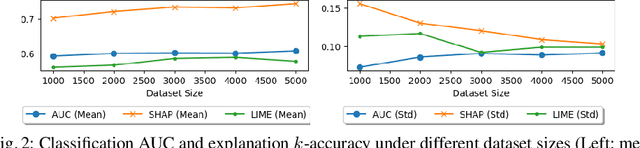
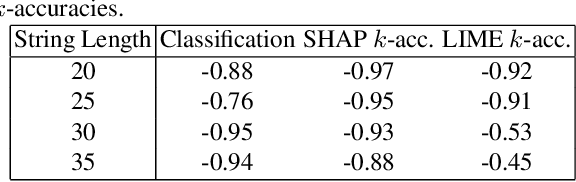
Explainable AI has attracted much research attention in recent years with feature attribution algorithms, which compute "feature importance" in predictions, becoming increasingly popular. However, there is little analysis of the validity of these algorithms as there is no "ground truth" in the existing datasets to validate their correctness. In this work, we develop a method to quantitatively evaluate the correctness of XAI algorithms by creating datasets with known explanation ground truth. To this end, we focus on the binary classification problems. String datasets are constructed using formal language derived from a grammar. A string is positive if and only if a certain property is fulfilled. Symbols serving as explanation ground truth in a positive string are part of an explanation if and only if they contributes to fulfilling the property. Two popular feature attribution explainers, Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP), are used in our experiments.We show that: (1) classification accuracy is positively correlated with explanation accuracy; (2) SHAP provides more accurate explanations than LIME; (3) explanation accuracy is negatively correlated with dataset complexity.