 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFiVFS: High Fidelity Video Face Swapping
Paper and Code
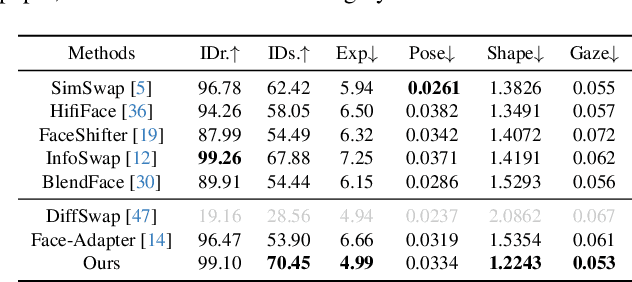
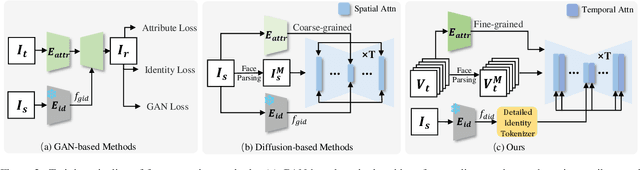

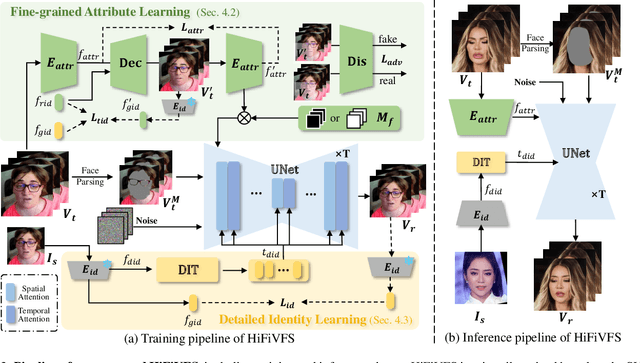
Face swapping aims to generate results that combine the identity from the source with attributes from the target. Existing methods primarily focus on image-based face swapping. When processing videos, each frame is handled independently, making it difficult to ensure temporal stability. From a model perspective, face swapping is gradually shifting from generative adversarial networks (GANs) to diffusion models (DMs), as DMs have been shown to possess stronger generative capabilities. Current diffusion-based approaches often employ inpainting techniques, which struggle to preserve fine-grained attributes like lighting and makeup. To address these challenges, we propose a high fidelity video face swapping (HiFiVFS) framework, which leverages the strong generative capability and temporal prior of Stable Video Diffusion (SVD). We build a fine-grained attribute module to extract identity-disentangled and fine-grained attribute features through identity desensitization and adversarial learning. Additionally, We introduce detailed identity injection to further enhance identity similarity. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) in video face swapping, both qualitatively and quantitatively.