 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder-Level Attention Similarity Across Language Models: A Latent Commonality
Nov 07, 2025
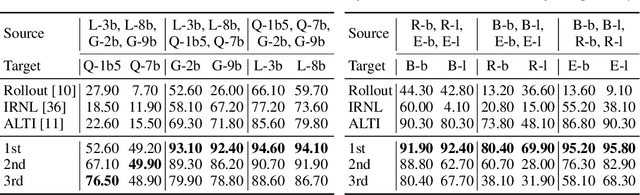


In this paper, we explore an important yet previously neglected question: Do context aggregation patterns across Language Models (LMs) share commonalities? While some works have investigated context aggregation or attention weights in LMs, they typically focus on individual models or attention heads, lacking a systematic analysis across multiple LMs to explore their commonalities. In contrast, we focus on the commonalities among LMs, which can deepen our understanding of LMs and even facilitate cross-model knowledge transfer. In this work, we introduce the Order-Level Attention (OLA) derived from the order-wise decomposition of Attention Rollout and reveal that the OLA at the same order across LMs exhibits significant similarities. Furthermore, we discover an implicit mapping between OLA and syntactic knowledge. Based on these two findings, we propose the Transferable OLA Adapter (TOA), a training-free cross-LM adapter transfer method. Specifically, we treat the OLA as a unified syntactic feature representation and train an adapter that takes OLA as input. Due to the similarities in OLA across LMs, the adapter generalizes to unseen LMs without requiring any parameter updates. Extensive experiments demonstrate that TOA's cross-LM generalization effectively enhances the performance of unseen LMs. Code is available at https://github.com/jinglin-liang/OLAS.
ReplayCAD: Generative Diffusion Replay for Continual Anomaly Detection
May 10, 2025



Continual Anomaly Detection (CAD) enables anomaly detection models in learning new classes while preserving knowledge of historical classes. CAD faces two key challenges: catastrophic forgetting and segmentation of small anomalous regions. Existing CAD methods store image distributions or patch features to mitigate catastrophic forgetting, but they fail to preserve pixel-level detailed features for accurate segmentation. To overcome this limitation, we propose ReplayCAD, a novel diffusion-driven generative replay framework that replay high-quality historical data, thus effectively preserving pixel-level detailed features. Specifically, we compress historical data by searching for a class semantic embedding in the conditional space of the pre-trained diffusion model, which can guide the model to replay data with fine-grained pixel details, thus improving the segmentation performance. However, relying solely on semantic features results in limited spatial diversity. Hence, we further use spatial features to guide data compression, achieving precise control of sample space, thereby generating more diverse data. Our method achieves state-of-the-art performance in both classification and segmentation, with notable improvements in segmentation: 11.5% on VisA and 8.1% on MVTec. Our source code is available at https://github.com/HULEI7/ReplayCAD.
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Sep 04, 2024Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
Complex Handwriting Trajectory Recovery: Evaluation Metrics and Algorithm
Oct 28, 2022Many important tasks such as forensic signature verification, calligraphy synthesis, etc, rely on handwriting trajectory recovery of which, however, even an appropriate evaluation metric is still missing. Indeed, existing metrics only focus on the writing orders but overlook the fidelity of glyphs. Taking both facets into account, we come up with two new metrics, the adaptive intersection on union (AIoU) which eliminates the influence of various stroke widths, and the length-independent dynamic time warping (LDTW) which solves the trajectory-point alignment problem. After that, we then propose a novel handwriting trajectory recovery model named Parsing-and-tracing ENcoder-decoder Network (PEN-Net), in particular for characters with both complex glyph and long trajectory, which was believed very challenging. In the PEN-Net, a carefully designed double-stream parsing encoder parses the glyph structure, and a global tracing decoder overcomes the memory difficulty of long trajectory prediction. Our experiments demonstrate that the two new metrics AIoU and LDTW together can truly assess the quality of handwriting trajectory recovery and the proposed PEN-Net exhibits satisfactory performance in various complex-glyph languages including Chinese, Japanese and Indic.