 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Machine Learning via Contrastive Training
Nov 17, 2025Quantum machine learning (QML) has attracted growing interest with the rapid parallel advances in large-scale classical machine learning and quantum technologies. Similar to classical machine learning, QML models also face challenges arising from the scarcity of labeled data, particularly as their scale and complexity increase. Here, we introduce self-supervised pretraining of quantum representations that reduces reliance on labeled data by learning invariances from unlabeled examples. We implement this paradigm on a programmable trapped-ion quantum computer, encoding images as quantum states. In situ contrastive pretraining on hardware yields a representation that, when fine-tuned, classifies image families with higher mean test accuracy and lower run-to-run variability than models trained from random initialization. Performance improvement is especially significant in regimes with limited labeled training data. We show that the learned invariances generalize beyond the pretraining image samples. Unlike prior work, our pipeline derives similarity from measured quantum overlaps and executes all training and classification stages on hardware. These results establish a label-efficient route to quantum representation learning, with direct relevance to quantum-native datasets and a clear path to larger classical inputs.
SEG-SAM: Semantic-Guided SAM for Unified Medical Image Segmentation
Dec 17, 2024



Recently, developing unified medical image segmentation models gains increasing attention, especially with the advent of the Segment Anything Model (SAM). SAM has shown promising binary segmentation performance in natural domains, however, transferring it to the medical domain remains challenging, as medical images often possess substantial inter-category overlaps. To address this, we propose the SEmantic-Guided SAM (SEG-SAM), a unified medical segmentation model that incorporates semantic medical knowledge to enhance medical segmentation performance. First, to avoid the potential conflict between binary and semantic predictions, we introduce a semantic-aware decoder independent of SAM's original decoder, specialized for both semantic segmentation on the prompted object and classification on unprompted objects in images. To further enhance the model's semantic understanding, we solicit key characteristics of medical categories from large language models and incorporate them into SEG-SAM through a text-to-vision semantic module, adaptively transferring the language information into the visual segmentation task. In the end, we introduce the cross-mask spatial alignment strategy to encourage greater overlap between the predicted masks from SEG-SAM's two decoders, thereby benefiting both predictions. Extensive experiments demonstrate that SEG-SAM outperforms state-of-the-art SAM-based methods in unified binary medical segmentation and task-specific methods in semantic medical segmentation, showcasing promising results and potential for broader medical applications.
SDCL: Students Discrepancy-Informed Correction Learning for Semi-supervised Medical Image Segmentation
Sep 25, 2024Semi-supervised medical image segmentation (SSMIS) has been demonstrated the potential to mitigate the issue of limited medical labeled data. However, confirmation and cognitive biases may affect the prevalent teacher-student based SSMIS methods due to erroneous pseudo-labels. To tackle this challenge, we improve the mean teacher approach and propose the Students Discrepancy-Informed Correction Learning (SDCL) framework that includes two students and one non-trainable teacher, which utilizes the segmentation difference between the two students to guide the self-correcting learning. The essence of SDCL is to identify the areas of segmentation discrepancy as the potential bias areas, and then encourage the model to review the correct cognition and rectify their own biases in these areas. To facilitate the bias correction learning with continuous review and rectification, two correction loss functions are employed to minimize the correct segmentation voxel distance and maximize the erroneous segmentation voxel entropy. We conducted experiments on three public medical image datasets: two 3D datasets (CT and MRI) and one 2D dataset (MRI). The results show that our SDCL surpasses the current State-of-the-Art (SOTA) methods by 2.57\%, 3.04\%, and 2.34\% in the Dice score on the Pancreas, LA, and ACDC datasets, respectively. In addition, the accuracy of our method is very close to the fully supervised method on the ACDC dataset, and even exceeds the fully supervised method on the Pancreas and LA dataset. (Code available at \url{https://github.com/pascalcpp/SDCL}).
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023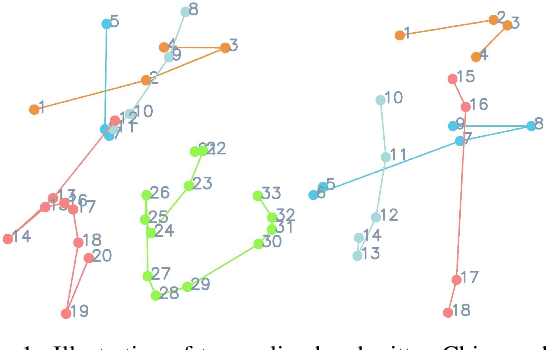



Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.