 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Radar Resource Management: Modified LIME in Deep Reinforcement Learning
Jun 26, 2025Deep reinforcement learning has been extensively studied in decision-making processes and has demonstrated superior performance over conventional approaches in various fields, including radar resource management (RRM). However, a notable limitation of neural networks is their ``black box" nature and recent research work has increasingly focused on explainable AI (XAI) techniques to describe the rationale behind neural network decisions. One promising XAI method is local interpretable model-agnostic explanations (LIME). However, the sampling process in LIME ignores the correlations between features. In this paper, we propose a modified LIME approach that integrates deep learning (DL) into the sampling process, which we refer to as DL-LIME. We employ DL-LIME within deep reinforcement learning for radar resource management. Numerical results show that DL-LIME outperforms conventional LIME in terms of both fidelity and task performance, demonstrating superior performance with both metrics. DL-LIME also provides insights on which factors are more important in decision making for radar resource management.
Learning-Based Resource Management in Integrated Sensing and Communication Systems
Jun 25, 2025



In this paper, we tackle the task of adaptive time allocation in integrated sensing and communication systems equipped with radar and communication units. The dual-functional radar-communication system's task involves allocating dwell times for tracking multiple targets and utilizing the remaining time for data transmission towards estimated target locations. We introduce a novel constrained deep reinforcement learning (CDRL) approach, designed to optimize resource allocation between tracking and communication under time budget constraints, thereby enhancing target communication quality. Our numerical results demonstrate the efficiency of our proposed CDRL framework, confirming its ability to maximize communication quality in highly dynamic environments while adhering to time constraints.
Feature-based Federated Transfer Learning: Communication Efficiency, Robustness and Privacy
May 15, 2024



In this paper, we propose feature-based federated transfer learning as a novel approach to improve communication efficiency by reducing the uplink payload by multiple orders of magnitude compared to that of existing approaches in federated learning and federated transfer learning. Specifically, in the proposed feature-based federated learning, we design the extracted features and outputs to be uploaded instead of parameter updates. For this distributed learning model, we determine the required payload and provide comparisons with the existing schemes. Subsequently, we analyze the robustness of feature-based federated transfer learning against packet loss, data insufficiency, and quantization. Finally, we address privacy considerations by defining and analyzing label privacy leakage and feature privacy leakage, and investigating mitigating approaches. For all aforementioned analyses, we evaluate the performance of the proposed learning scheme via experiments on an image classification task and a natural language processing task to demonstrate its effectiveness.
Learning-Based UAV Path Planning for Data Collection with Integrated Collision Avoidance
Dec 11, 2023



Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectory in multi-UAV non-cooperative scenarios while collecting data from distributed Internet of Things (IoT) nodes is a challenging task. In this paper, we consider a path planning optimization problem to maximize the collected data from multiple IoT nodes under realistic constraints. The considered multi-UAV non-cooperative scenarios involve random number of other UAVs in addition to the typical UAV, and UAVs do not communicate or share information among each other. We translate the problem into a Markov decision process (MDP) with parameterized states, permissible actions, and detailed reward functions. Dueling double deep Q-network (D3QN) is proposed to learn the decision making policy for the typical UAV, without any prior knowledge of the environment (e.g., channel propagation model and locations of the obstacles) and other UAVs (e.g., their missions, movements, and policies). The proposed algorithm can adapt to various missions in various scenarios, e.g., different numbers and positions of IoT nodes, different amount of data to be collected, and different numbers and positions of other UAVs. Numerical results demonstrate that real-time navigation can be efficiently performed with high success rate, high data collection rate, and low collision rate.
* The final version of this paper has been accepted in IEEE Internet of Things Journal
QMGeo: Differentially Private Federated Learning via Stochastic Quantization with Mixed Truncated Geometric Distribution
Dec 10, 2023



Federated learning (FL) is a framework which allows multiple users to jointly train a global machine learning (ML) model by transmitting only model updates under the coordination of a parameter server, while being able to keep their datasets local. One key motivation of such distributed frameworks is to provide privacy guarantees to the users. However, preserving the users' datasets locally is shown to be not sufficient for privacy. Several differential privacy (DP) mechanisms have been proposed to provide provable privacy guarantees by introducing randomness into the framework, and majority of these mechanisms rely on injecting additive noise. FL frameworks also face the challenge of communication efficiency, especially as machine learning models grow in complexity and size. Quantization is a commonly utilized method, reducing the communication cost by transmitting compressed representation of the underlying information. Although there have been several studies on DP and quantization in FL, the potential contribution of the quantization method alone in providing privacy guarantees has not been extensively analyzed yet. We in this paper present a novel stochastic quantization method, utilizing a mixed geometric distribution to introduce the randomness needed to provide DP, without any additive noise. We provide convergence analysis for our framework and empirically study its performance.
Anomaly Detection via Learning-Based Sequential Controlled Sensing
Nov 30, 2023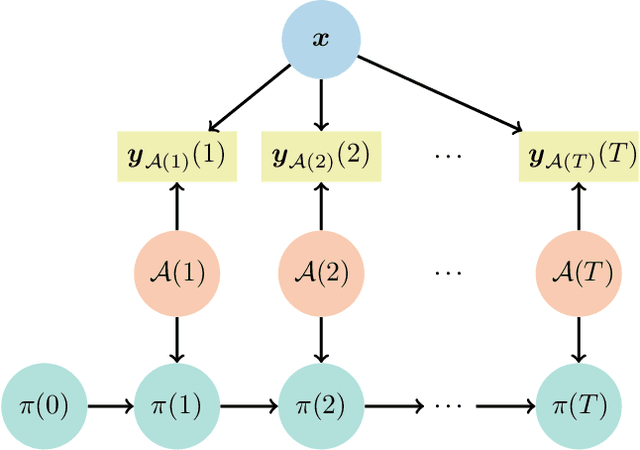
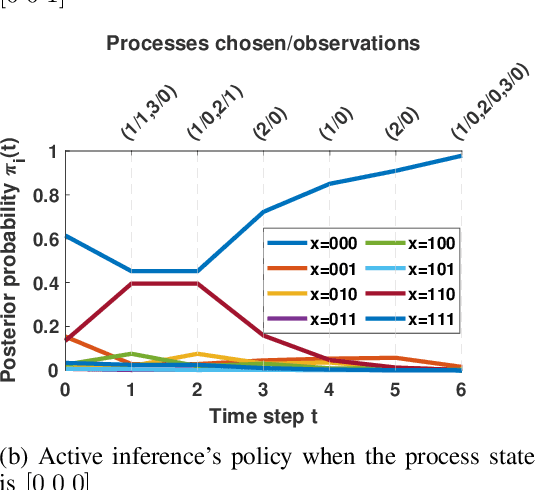

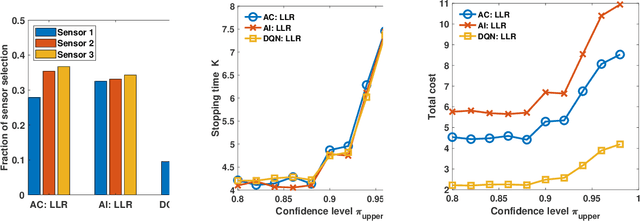
In this paper, we address the problem of detecting anomalies among a given set of binary processes via learning-based controlled sensing. Each process is parameterized by a binary random variable indicating whether the process is anomalous. To identify the anomalies, the decision-making agent is allowed to observe a subset of the processes at each time instant. Also, probing each process has an associated cost. Our objective is to design a sequential selection policy that dynamically determines which processes to observe at each time with the goal to minimize the delay in making the decision and the total sensing cost. We cast this problem as a sequential hypothesis testing problem within the framework of Markov decision processes. This formulation utilizes both a Bayesian log-likelihood ratio-based reward and an entropy-based reward. The problem is then solved using two approaches: 1) a deep reinforcement learning-based approach where we design both deep Q-learning and policy gradient actor-critic algorithms; and 2) a deep active inference-based approach. Using numerical experiments, we demonstrate the efficacy of our algorithms and show that our algorithms adapt to any unknown statistical dependence pattern of the processes.
Robust Network Slicing: Multi-Agent Policies, Adversarial Attacks, and Defensive Strategies
Nov 19, 2023



In this paper, we present a multi-agent deep reinforcement learning (deep RL) framework for network slicing in a dynamic environment with multiple base stations and multiple users. In particular, we propose a novel deep RL framework with multiple actors and centralized critic (MACC) in which actors are implemented as pointer networks to fit the varying dimension of input. We evaluate the performance of the proposed deep RL algorithm via simulations to demonstrate its effectiveness. Subsequently, we develop a deep RL based jammer with limited prior information and limited power budget. The goal of the jammer is to minimize the transmission rates achieved with network slicing and thus degrade the network slicing agents' performance. We design a jammer with both listening and jamming phases and address jamming location optimization as well as jamming channel optimization via deep RL. We evaluate the jammer at the optimized location, generating interference attacks in the optimized set of channels by switching between the jamming phase and listening phase. We show that the proposed jammer can significantly reduce the victims' performance without direct feedback or prior knowledge on the network slicing policies. Finally, we devise a Nash-equilibrium-supervised policy ensemble mixed strategy profile for network slicing (as a defensive measure) and jamming. We evaluate the performance of the proposed policy ensemble algorithm by applying on the network slicing agents and the jammer agent in simulations to show its effectiveness.
Maximum Knowledge Orthogonality Reconstruction with Gradients in Federated Learning
Oct 30, 2023



Federated learning (FL) aims at keeping client data local to preserve privacy. Instead of gathering the data itself, the server only collects aggregated gradient updates from clients. Following the popularity of FL, there has been considerable amount of work, revealing the vulnerability of FL approaches by reconstructing the input data from gradient updates. Yet, most existing works assume an FL setting with unrealistically small batch size, and have poor image quality when the batch size is large. Other works modify the neural network architectures or parameters to the point of being suspicious, and thus, can be detected by clients. Moreover, most of them can only reconstruct one sample input from a large batch. To address these limitations, we propose a novel and completely analytical approach, referred to as the maximum knowledge orthogonality reconstruction (MKOR), to reconstruct clients' input data. Our proposed method reconstructs a mathematically proven high quality image from large batches. MKOR only requires the server to send secretly modified parameters to clients and can efficiently and inconspicuously reconstruct the input images from clients' gradient updates. We evaluate MKOR's performance on the MNIST, CIFAR-100, and ImageNet dataset and compare it with the state-of-the-art works. The results show that MKOR outperforms the existing approaches, and draws attention to a pressing need for further research on the privacy protection of FL so that comprehensive defense approaches can be developed.
Communication-Efficient and Privacy-Preserving Feature-based Federated Transfer Learning
Sep 12, 2022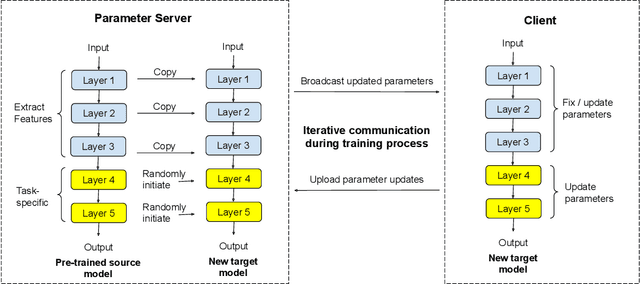
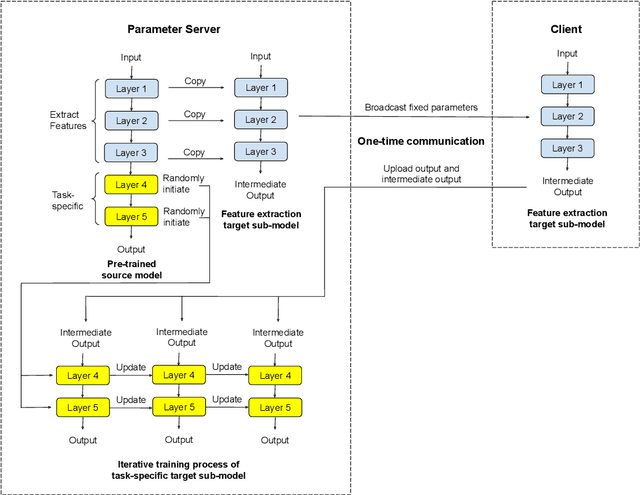


Federated learning has attracted growing interest as it preserves the clients' privacy. As a variant of federated learning, federated transfer learning utilizes the knowledge from similar tasks and thus has also been intensively studied. However, due to the limited radio spectrum, the communication efficiency of federated learning via wireless links is critical since some tasks may require thousands of Terabytes of uplink payload. In order to improve the communication efficiency, we in this paper propose the feature-based federated transfer learning as an innovative approach to reduce the uplink payload by more than five orders of magnitude compared to that of existing approaches. We first introduce the system design in which the extracted features and outputs are uploaded instead of parameter updates, and then determine the required payload with this approach and provide comparisons with the existing approaches. Subsequently, we analyze the random shuffling scheme that preserves the clients' privacy. Finally, we evaluate the performance of the proposed learning scheme via experiments on an image classification task to show its effectiveness.
Monitoring and Anomaly Detection Actor-Critic Based Controlled Sensing
Jan 03, 2022
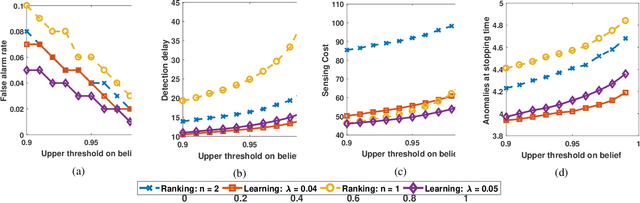
We address the problem of monitoring a set of binary stochastic processes and generating an alert when the number of anomalies among them exceeds a threshold. For this, the decision-maker selects and probes a subset of the processes to obtain noisy estimates of their states (normal or anomalous). Based on the received observations, the decisionmaker first determines whether to declare that the number of anomalies has exceeded the threshold or to continue taking observations. When the decision is to continue, it then decides whether to collect observations at the next time instant or defer it to a later time. If it chooses to collect observations, it further determines the subset of processes to be probed. To devise this three-step sequential decision-making process, we use a Bayesian formulation wherein we learn the posterior probability on the states of the processes. Using the posterior probability, we construct a Markov decision process and solve it using deep actor-critic reinforcement learning. Via numerical experiments, we demonstrate the superior performance of our algorithm compared to the traditional model-based algorithms.