 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection via Learning-Based Sequential Controlled Sensing
Paper and Code
Nov 30, 2023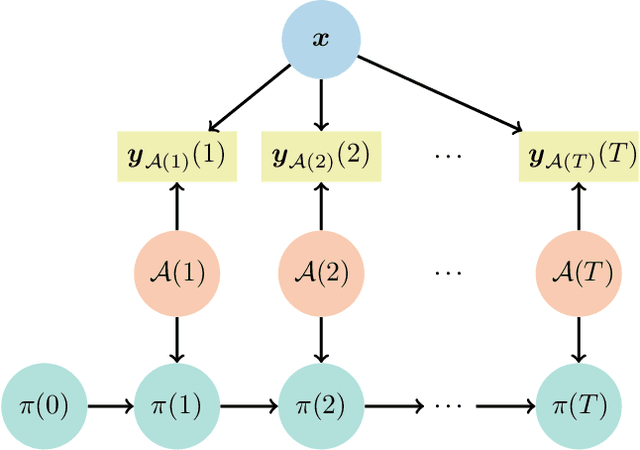
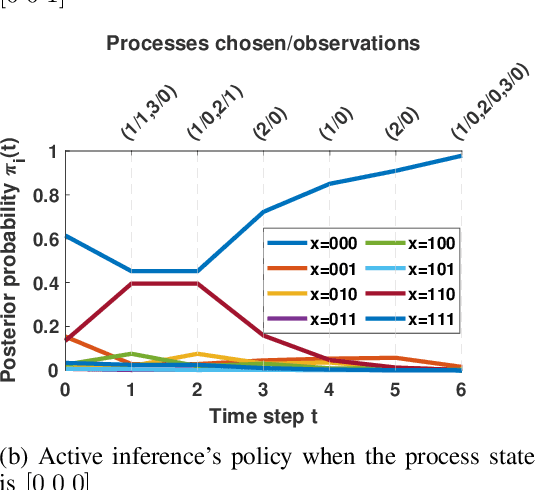

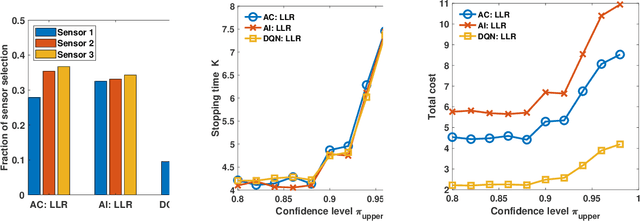
In this paper, we address the problem of detecting anomalies among a given set of binary processes via learning-based controlled sensing. Each process is parameterized by a binary random variable indicating whether the process is anomalous. To identify the anomalies, the decision-making agent is allowed to observe a subset of the processes at each time instant. Also, probing each process has an associated cost. Our objective is to design a sequential selection policy that dynamically determines which processes to observe at each time with the goal to minimize the delay in making the decision and the total sensing cost. We cast this problem as a sequential hypothesis testing problem within the framework of Markov decision processes. This formulation utilizes both a Bayesian log-likelihood ratio-based reward and an entropy-based reward. The problem is then solved using two approaches: 1) a deep reinforcement learning-based approach where we design both deep Q-learning and policy gradient actor-critic algorithms; and 2) a deep active inference-based approach. Using numerical experiments, we demonstrate the efficacy of our algorithms and show that our algorithms adapt to any unknown statistical dependence pattern of the processes.