 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Radar Resource Management: Modified LIME in Deep Reinforcement Learning
Jun 26, 2025Deep reinforcement learning has been extensively studied in decision-making processes and has demonstrated superior performance over conventional approaches in various fields, including radar resource management (RRM). However, a notable limitation of neural networks is their ``black box" nature and recent research work has increasingly focused on explainable AI (XAI) techniques to describe the rationale behind neural network decisions. One promising XAI method is local interpretable model-agnostic explanations (LIME). However, the sampling process in LIME ignores the correlations between features. In this paper, we propose a modified LIME approach that integrates deep learning (DL) into the sampling process, which we refer to as DL-LIME. We employ DL-LIME within deep reinforcement learning for radar resource management. Numerical results show that DL-LIME outperforms conventional LIME in terms of both fidelity and task performance, demonstrating superior performance with both metrics. DL-LIME also provides insights on which factors are more important in decision making for radar resource management.
Learning-Based Resource Management in Integrated Sensing and Communication Systems
Jun 25, 2025



In this paper, we tackle the task of adaptive time allocation in integrated sensing and communication systems equipped with radar and communication units. The dual-functional radar-communication system's task involves allocating dwell times for tracking multiple targets and utilizing the remaining time for data transmission towards estimated target locations. We introduce a novel constrained deep reinforcement learning (CDRL) approach, designed to optimize resource allocation between tracking and communication under time budget constraints, thereby enhancing target communication quality. Our numerical results demonstrate the efficiency of our proposed CDRL framework, confirming its ability to maximize communication quality in highly dynamic environments while adhering to time constraints.
ScanERU: Interactive 3D Visual Grounding based on Embodied Reference Understanding
Mar 23, 2023



Aiming to link natural language descriptions to specific regions in a 3D scene represented as 3D point clouds, 3D visual grounding is a very fundamental task for human-robot interaction. The recognition errors can significantly impact the overall accuracy and then degrade the operation of AI systems. Despite their effectiveness, existing methods suffer from the difficulty of low recognition accuracy in cases of multiple adjacent objects with similar appearances.To address this issue, this work intuitively introduces the human-robot interaction as a cue to facilitate the development of 3D visual grounding. Specifically, a new task termed Embodied Reference Understanding (ERU) is first designed for this concern. Then a new dataset called ScanERU is constructed to evaluate the effectiveness of this idea. Different from existing datasets, our ScanERU is the first to cover semi-synthetic scene integration with textual, real-world visual, and synthetic gestural information. Additionally, this paper formulates a heuristic framework based on attention mechanisms and human body movements to enlighten the research of ERU. Experimental results demonstrate the superiority of the proposed method, especially in the recognition of multiple identical objects. Our codes and dataset are ready to be available publicly.
Dynamic Channel Access via Meta-Reinforcement Learning
Dec 24, 2021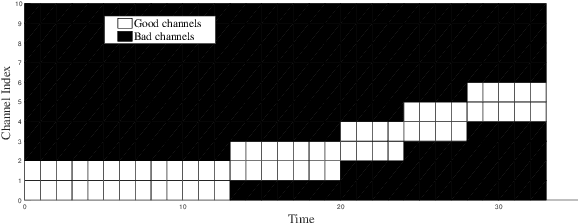
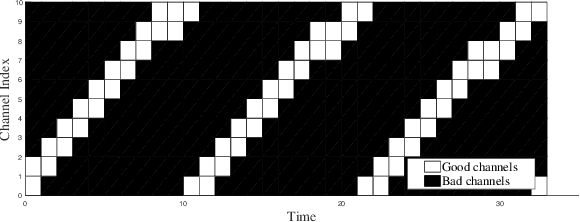
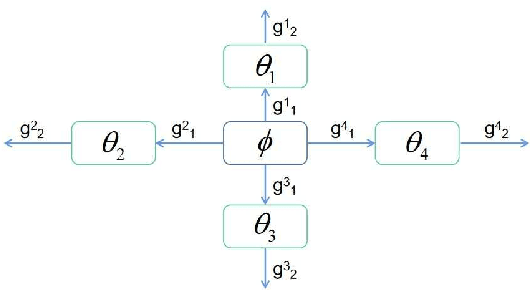
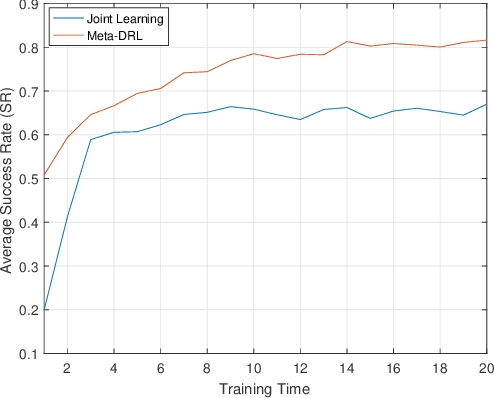
In this paper, we address the channel access problem in a dynamic wireless environment via meta-reinforcement learning. Spectrum is a scarce resource in wireless communications, especially with the dramatic increase in the number of devices in networks. Recently, inspired by the success of deep reinforcement learning (DRL), extensive studies have been conducted in addressing wireless resource allocation problems via DRL. However, training DRL algorithms usually requires a massive amount of data collected from the environment for each specific task and the well-trained model may fail if there is a small variation in the environment. In this work, in order to address these challenges, we propose a meta-DRL framework that incorporates the method of Model-Agnostic Meta-Learning (MAML). In the proposed framework, we train a common initialization for similar channel selection tasks. From the initialization, we show that only a few gradient descents are required for adapting to different tasks drawn from the same distribution. We demonstrate the performance improvements via simulation results.
A Deep Actor-Critic Reinforcement Learning Framework for Dynamic Multichannel Access
Aug 20, 2019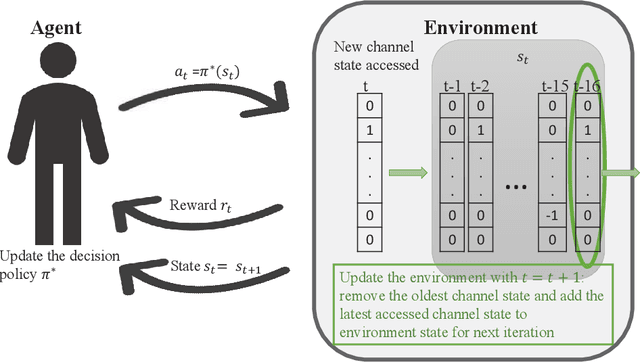
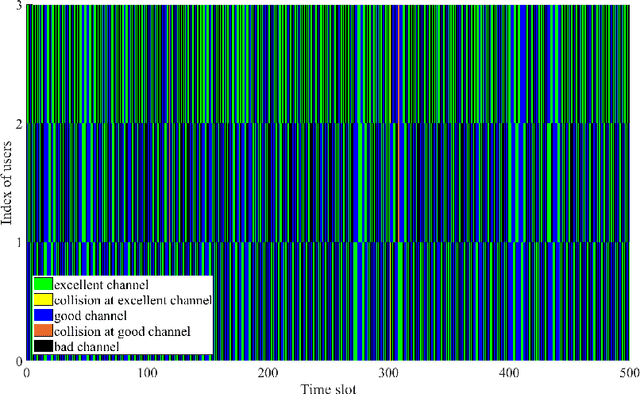
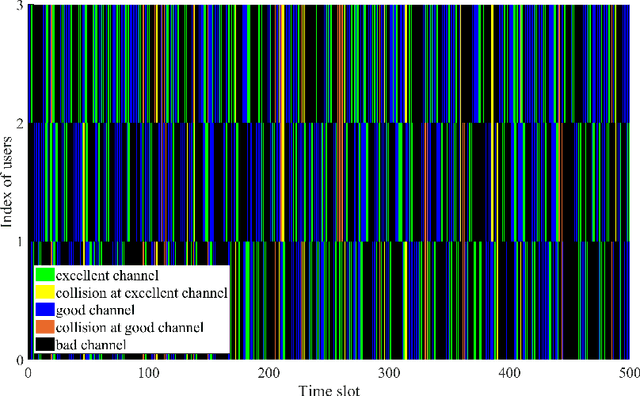
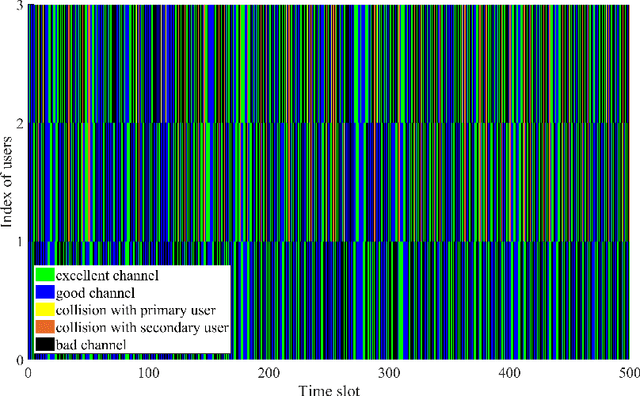
To make efficient use of limited spectral resources, we in this work propose a deep actor-critic reinforcement learning based framework for dynamic multichannel access. We consider both a single-user case and a scenario in which multiple users attempt to access channels simultaneously. We employ the proposed framework as a single agent in the single-user case, and extend it to a decentralized multi-agent framework in the multi-user scenario. In both cases, we develop algorithms for the actor-critic deep reinforcement learning and evaluate the proposed learning policies via experiments and numerical results. In the single-user model, in order to evaluate the performance of the proposed channel access policy and the framework's tolerance against uncertainty, we explore different channel switching patterns and different switching probabilities. In the case of multiple users, we analyze the probabilities of each user accessing channels with favorable channel conditions and the probability of collision. We also address a time-varying environment to identify the adaptive ability of the proposed framework. Additionally, we provide comparisons (in terms of both the average reward and time efficiency) between the proposed actor-critic deep reinforcement learning framework, Deep-Q network (DQN) based approach, random access, and the optimal policy when the channel dynamics are known.
Actor-Critic Deep Reinforcement Learning for Dynamic Multichannel Access
Oct 08, 2018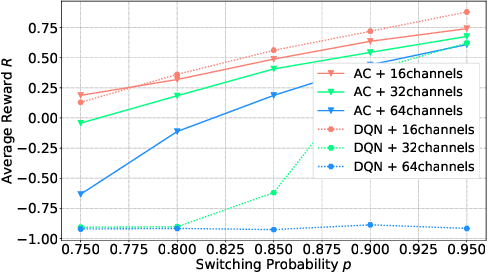
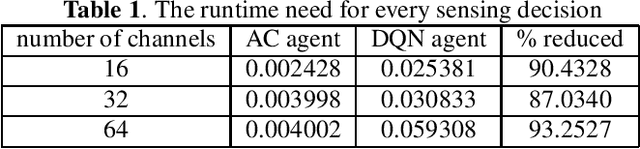
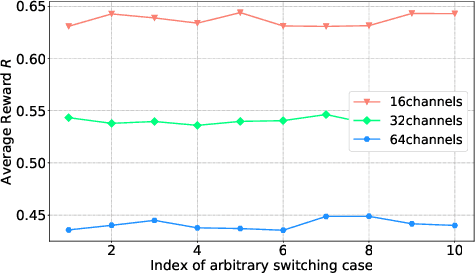
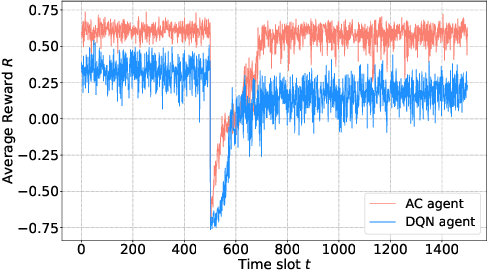
We consider the dynamic multichannel access problem, which can be formulated as a partially observable Markov decision process (POMDP). We first propose a model-free actor-critic deep reinforcement learning based framework to explore the sensing policy. To evaluate the performance of the proposed sensing policy and the framework's tolerance against uncertainty, we test the framework in scenarios with different channel switching patterns and consider different switching probabilities. Then, we consider a time-varying environment to identify the adaptive ability of the proposed framework. Additionally, we provide comparisons with the Deep-Q network (DQN) based framework proposed in [1], in terms of both average reward and the time efficiency.