 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Reaching Policy Learning from Non-Expert Observations via Effective Subgoal Guidance
Sep 06, 2024


In this work, we address the challenging problem of long-horizon goal-reaching policy learning from non-expert, action-free observation data. Unlike fully labeled expert data, our data is more accessible and avoids the costly process of action labeling. Additionally, compared to online learning, which often involves aimless exploration, our data provides useful guidance for more efficient exploration. To achieve our goal, we propose a novel subgoal guidance learning strategy. The motivation behind this strategy is that long-horizon goals offer limited guidance for efficient exploration and accurate state transition. We develop a diffusion strategy-based high-level policy to generate reasonable subgoals as waypoints, preferring states that more easily lead to the final goal. Additionally, we learn state-goal value functions to encourage efficient subgoal reaching. These two components naturally integrate into the off-policy actor-critic framework, enabling efficient goal attainment through informative exploration. We evaluate our method on complex robotic navigation and manipulation tasks, demonstrating a significant performance advantage over existing methods. Our ablation study further shows that our method is robust to observation data with various corruptions.
Diffusion Models as Optimizers for Efficient Planning in Offline RL
Jul 23, 2024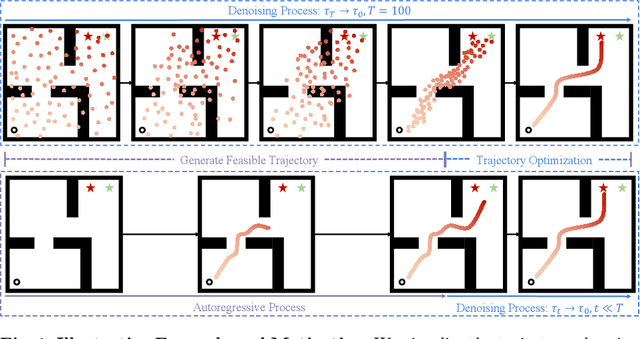
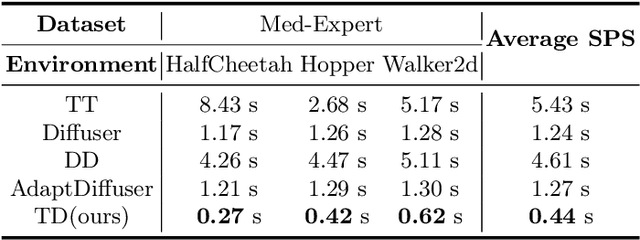
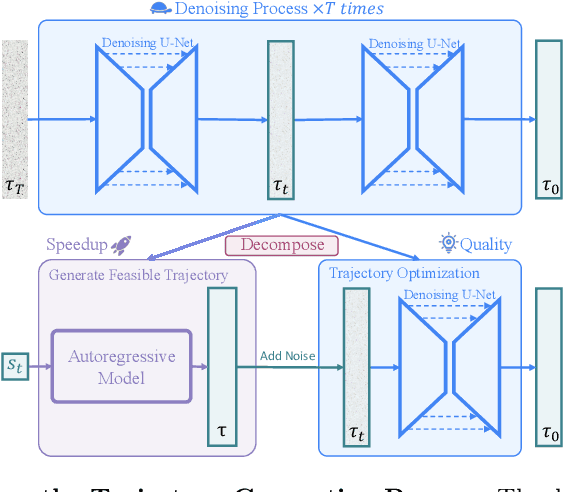
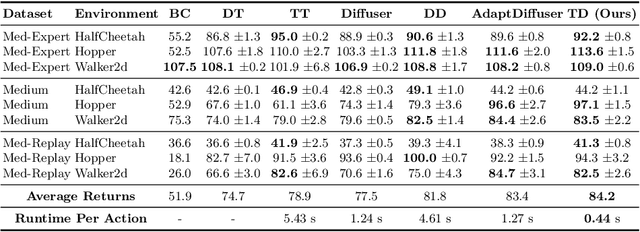
Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $\it 3$-$\it 10 \times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model
ScanERU: Interactive 3D Visual Grounding based on Embodied Reference Understanding
Mar 23, 2023



Aiming to link natural language descriptions to specific regions in a 3D scene represented as 3D point clouds, 3D visual grounding is a very fundamental task for human-robot interaction. The recognition errors can significantly impact the overall accuracy and then degrade the operation of AI systems. Despite their effectiveness, existing methods suffer from the difficulty of low recognition accuracy in cases of multiple adjacent objects with similar appearances.To address this issue, this work intuitively introduces the human-robot interaction as a cue to facilitate the development of 3D visual grounding. Specifically, a new task termed Embodied Reference Understanding (ERU) is first designed for this concern. Then a new dataset called ScanERU is constructed to evaluate the effectiveness of this idea. Different from existing datasets, our ScanERU is the first to cover semi-synthetic scene integration with textual, real-world visual, and synthetic gestural information. Additionally, this paper formulates a heuristic framework based on attention mechanisms and human body movements to enlighten the research of ERU. Experimental results demonstrate the superiority of the proposed method, especially in the recognition of multiple identical objects. Our codes and dataset are ready to be available publicly.