 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuWa: Deriving Lightweight Task-Specific Vision Transformers for Edge Devices
Apr 04, 2025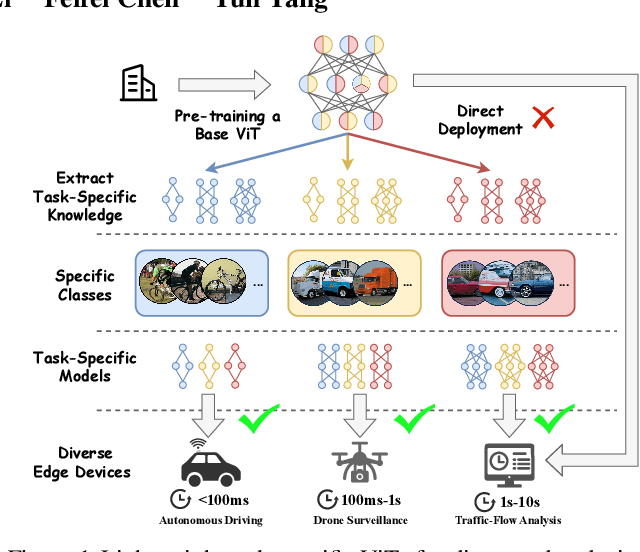



Vision Transformers (ViTs) excel in computer vision tasks but lack flexibility for edge devices' diverse needs. A vital issue is that ViTs pre-trained to cover a broad range of tasks are \textit{over-qualified} for edge devices that usually demand only part of a ViT's knowledge for specific tasks. Their task-specific accuracy on these edge devices is suboptimal. We discovered that small ViTs that focus on device-specific tasks can improve model accuracy and in the meantime, accelerate model inference. This paper presents NuWa, an approach that derives small ViTs from the base ViT for edge devices with specific task requirements. NuWa can transfer task-specific knowledge extracted from the base ViT into small ViTs that fully leverage constrained resources on edge devices to maximize model accuracy with inference latency assurance. Experiments with three base ViTs on three public datasets demonstrate that compared with state-of-the-art solutions, NuWa improves model accuracy by up to $\text{11.83}\%$ and accelerates model inference by 1.29$\times$ - 2.79$\times$. Code for reproduction is available at https://anonymous.4open.science/r/Task_Specific-3A5E.