Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDIOMS: A Multilingual Linked Idioms Data Set
Paper and Code
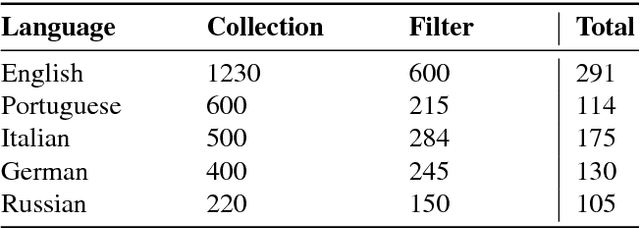



In this paper, we describe the LIDIOMS data set, a multilingual RDF representation of idioms currently containing five languages: English, German, Italian, Portuguese, and Russian. The data set is intended to support natural language processing applications by providing links between idioms across languages. The underlying data was crawled and integrated from various sources. To ensure the quality of the crawled data, all idioms were evaluated by at least two native speakers. Herein, we present the model devised for structuring the data. We also provide the details of linking LIDIOMS to well-known multilingual data sets such as BabelNet. The resulting data set complies with best practices according to Linguistic Linked Open Data Community.
* Accepted for publication in Language Resources and Evaluation
Conference (LREC) 2018
View paper on