 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLFMF: Data Sets for Machine Learning for Mathematical Formalization
Oct 24, 2023We introduce MLFMF, a collection of data sets for benchmarking recommendation systems used to support formalization of mathematics with proof assistants. These systems help humans identify which previous entries (theorems, constructions, datatypes, and postulates) are relevant in proving a new theorem or carrying out a new construction. Each data set is derived from a library of formalized mathematics written in proof assistants Agda or Lean. The collection includes the largest Lean~4 library Mathlib, and some of the largest Agda libraries: the standard library, the library of univalent mathematics Agda-unimath, and the TypeTopology library. Each data set represents the corresponding library in two ways: as a heterogeneous network, and as a list of s-expressions representing the syntax trees of all the entries in the library. The network contains the (modular) structure of the library and the references between entries, while the s-expressions give complete and easily parsed information about every entry. We report baseline results using standard graph and word embeddings, tree ensembles, and instance-based learning algorithms. The MLFMF data sets provide solid benchmarking support for further investigation of the numerous machine learning approaches to formalized mathematics. The methodology used to extract the networks and the s-expressions readily applies to other libraries, and is applicable to other proof assistants. With more than $250\,000$ entries in total, this is currently the largest collection of formalized mathematical knowledge in machine learnable format.
P(Expression
Dec 02, 2022


Probabilistic context-free grammars have a long-term record of use as generative models in machine learning and symbolic regression. When used for symbolic regression, they generate algebraic expressions. We define the latter as equivalence classes of strings derived by grammar and address the problem of calculating the probability of deriving a given expression with a given grammar. We show that the problem is undecidable in general. We then present specific grammars for generating linear, polynomial, and rational expressions, where algorithms for calculating the probability of a given expression exist. For those grammars, we design algorithms for calculating the exact probability and efficient approximation with arbitrary precision.
Unsupervised Feature Ranking via Attribute Networks
Nov 25, 2021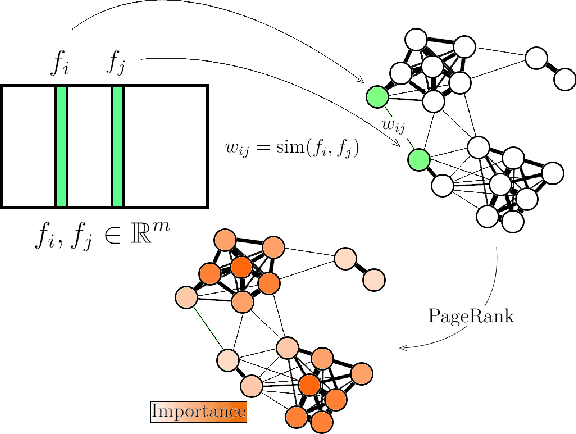
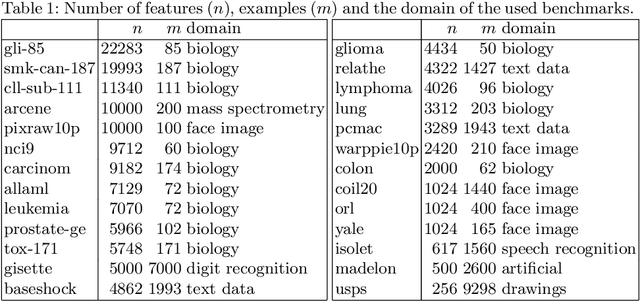
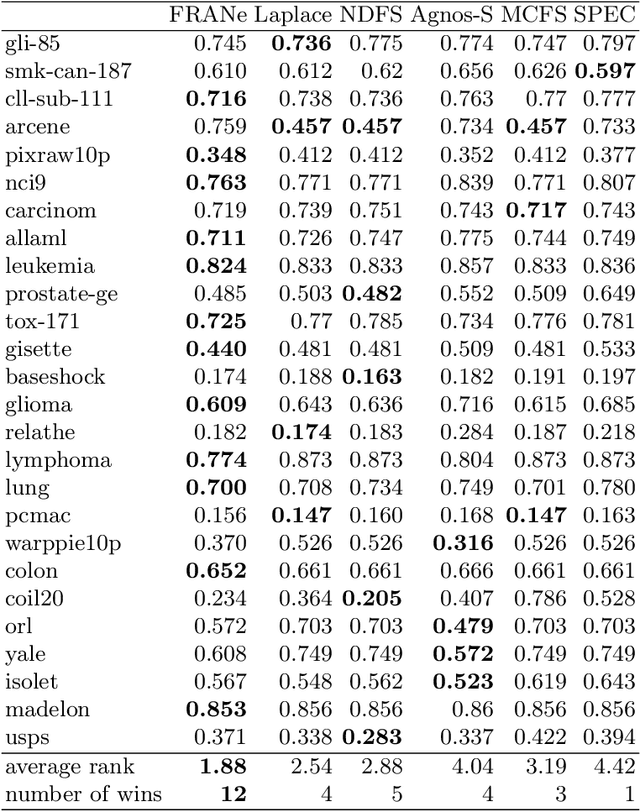
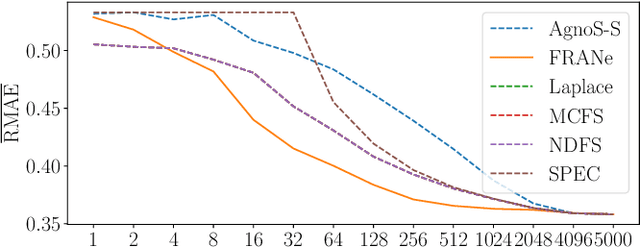
The need for learning from unlabeled data is increasing in contemporary machine learning. Methods for unsupervised feature ranking, which identify the most important features in such data are thus gaining attention, and so are their applications in studying high throughput biological experiments or user bases for recommender systems. We propose FRANe (Feature Ranking via Attribute Networks), an unsupervised algorithm capable of finding key features in given unlabeled data set. FRANe is based on ideas from network reconstruction and network analysis. FRANe performs better than state-of-the-art competitors, as we empirically demonstrate on a large collection of benchmarks. Moreover, we provide the time complexity analysis of FRANe further demonstrating its scalability. Finally, FRANe offers as the result the interpretable relational structures used to derive the feature importances.
* for online material and python package see https://github.com/FRANe-team/FRANe
GalaxAI: Machine learning toolbox for interpretable analysis of spacecraft telemetry data
Aug 09, 2021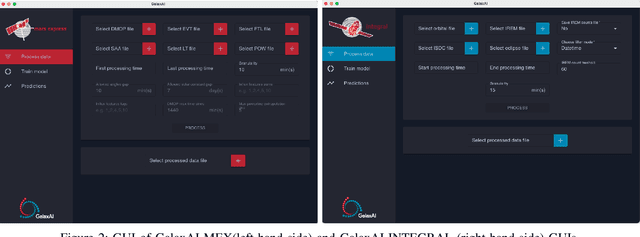
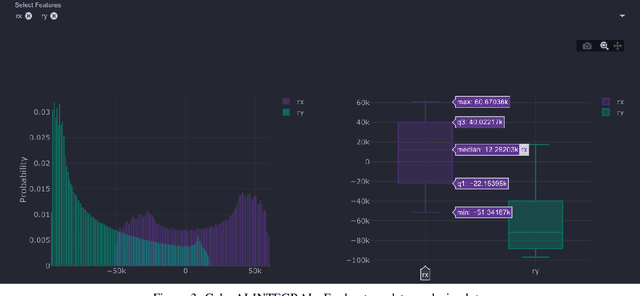
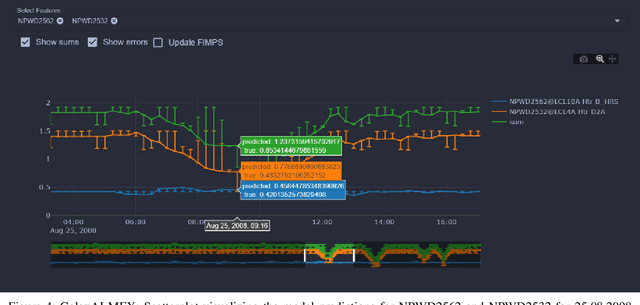
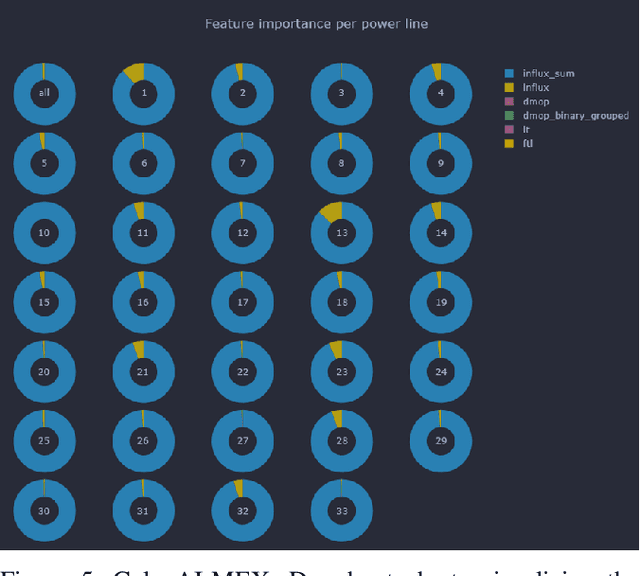
We present GalaxAI - a versatile machine learning toolbox for efficient and interpretable end-to-end analysis of spacecraft telemetry data. GalaxAI employs various machine learning algorithms for multivariate time series analyses, classification, regression and structured output prediction, capable of handling high-throughput heterogeneous data. These methods allow for the construction of robust and accurate predictive models, that are in turn applied to different tasks of spacecraft monitoring and operations planning. More importantly, besides the accurate building of models, GalaxAI implements a visualisation layer, providing mission specialists and operators with a full, detailed and interpretable view of the data analysis process. We show the utility and versatility of GalaxAI on two use-cases concerning two different spacecraft: i) analysis and planning of Mars Express thermal power consumption and ii) predicting of INTEGRAL's crossings through Van Allen belts.
Discovering outliers in the Mars Express thermal power consumption patterns
Aug 04, 2021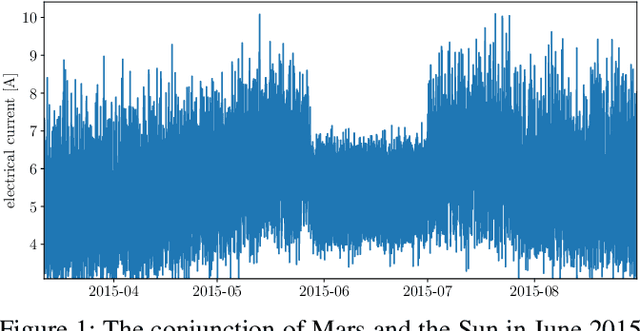
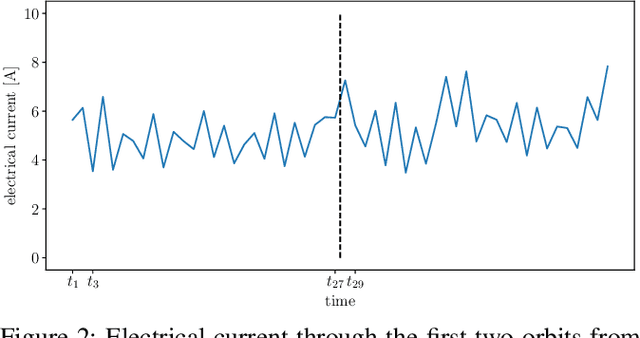
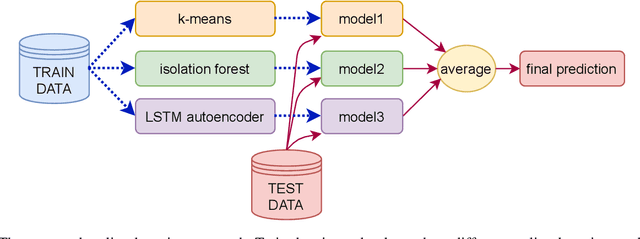
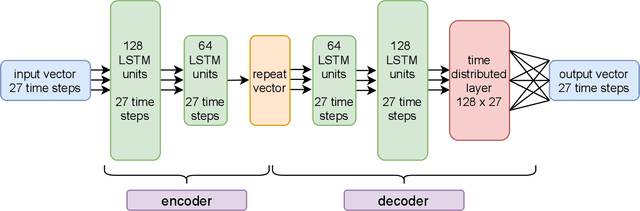
The Mars Express (MEX) spacecraft has been orbiting Mars since 2004. The operators need to constantly monitor its behavior and handle sporadic deviations (outliers) from the expected patterns of measurements of quantities that the satellite is sending to Earth. In this paper, we analyze the patterns of the electrical power consumption of MEX's thermal subsystem, that maintains the spacecraft's temperature at the desired level. The consumption is not constant, but should be roughly periodic in the short term, with the period that corresponds to one orbit around Mars. By using long short-term memory neural networks, we show that the consumption pattern is more irregular than expected, and successfully detect such irregularities, opening possibility for automatic outlier detection on MEX in the future.
ReliefE: Feature Ranking in High-dimensional Spaces via Manifold Embeddings
Jan 23, 2021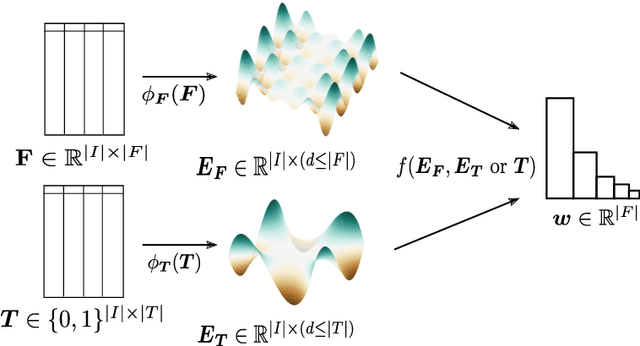
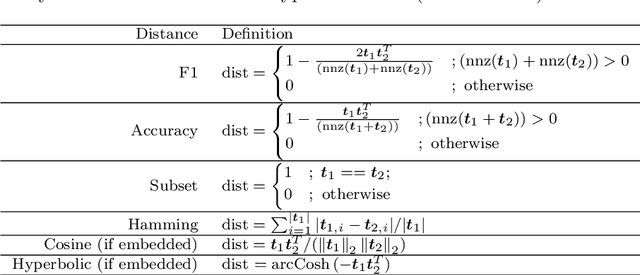

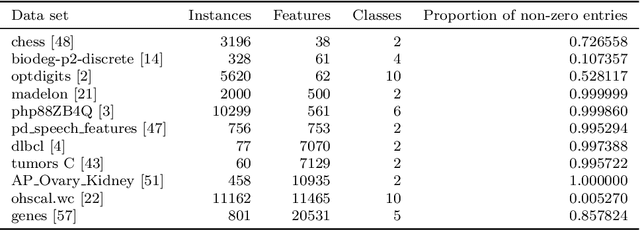
Feature ranking has been widely adopted in machine learning applications such as high-throughput biology and social sciences. The approaches of the popular Relief family of algorithms assign importances to features by iteratively accounting for nearest relevant and irrelevant instances. Despite their high utility, these algorithms can be computationally expensive and not-well suited for high-dimensional sparse input spaces. In contrast, recent embedding-based methods learn compact, low-dimensional representations, potentially facilitating down-stream learning capabilities of conventional learners. This paper explores how the Relief branch of algorithms can be adapted to benefit from (Riemannian) manifold-based embeddings of instance and target spaces, where a given embedding's dimensionality is intrinsic to the dimensionality of the considered data set. The developed ReliefE algorithm is faster and can result in better feature rankings, as shown by our evaluation on 20 real-life data sets for multi-class and multi-label classification tasks. The utility of ReliefE for high-dimensional data sets is ensured by its implementation that utilizes sparse matrix algebraic operations. Finally, the relation of ReliefE to other ranking algorithms is studied via the Fuzzy Jaccard Index.
Ensemble- and Distance-Based Feature Ranking for Unsupervised Learning
Nov 23, 2020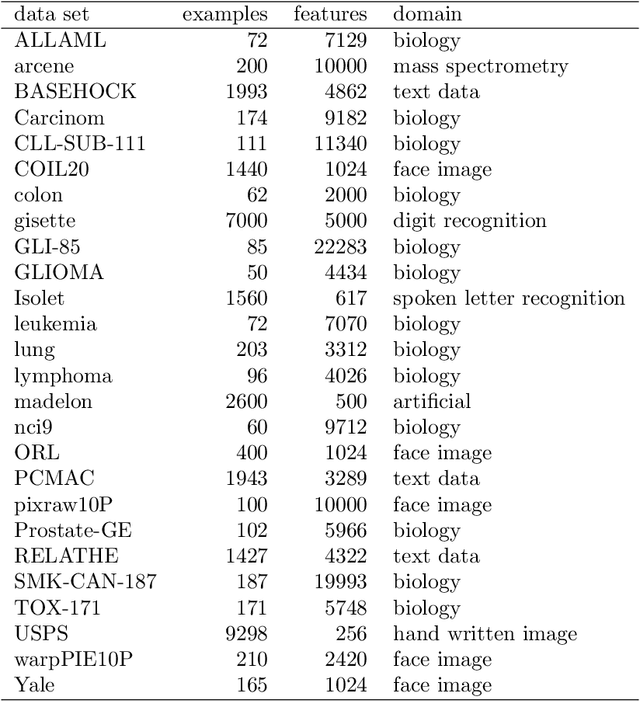
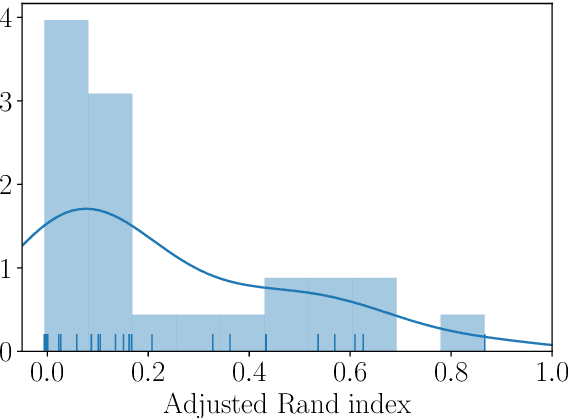
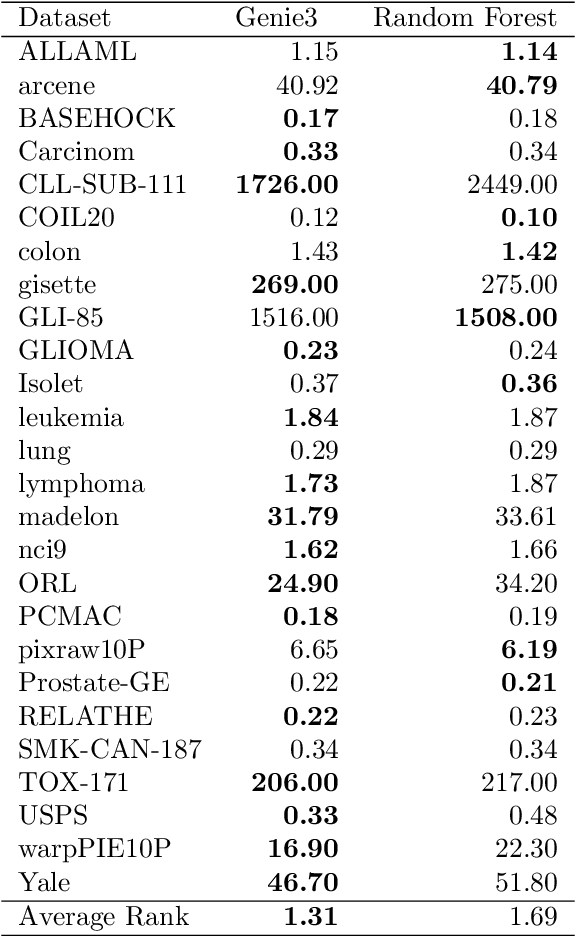
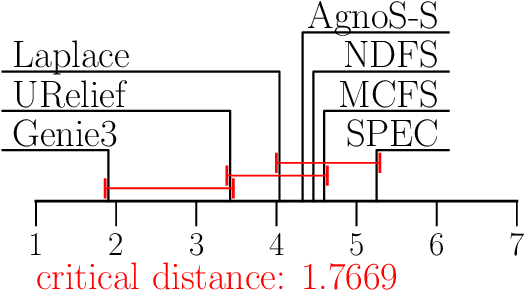
In this work, we propose two novel (groups of) methods for unsupervised feature ranking and selection. The first group includes feature ranking scores (Genie3 score, RandomForest score) that are computed from ensembles of predictive clustering trees. The second method is URelief, the unsupervised extension of the Relief family of feature ranking algorithms. Using 26 benchmark data sets and 5 baselines, we show that both the Genie3 score (computed from the ensemble of extra trees) and the URelief method outperform the existing methods and that Genie3 performs best overall, in terms of predictive power of the top-ranked features. Additionally, we analyze the influence of the hyper-parameters of the proposed methods on their performance, and show that for the Genie3 score the highest quality is achieved by the most efficient parameter configuration. Finally, we propose a way of discovering the location of the features in the ranking, which are the most relevant in reality.
Feature Ranking for Semi-supervised Learning
Aug 10, 2020
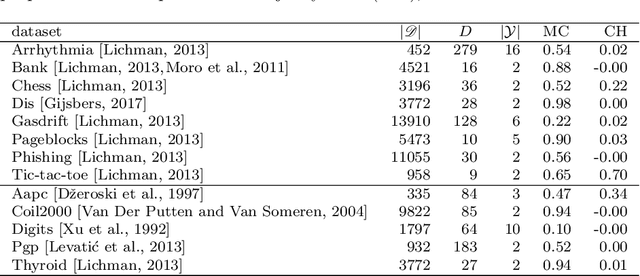
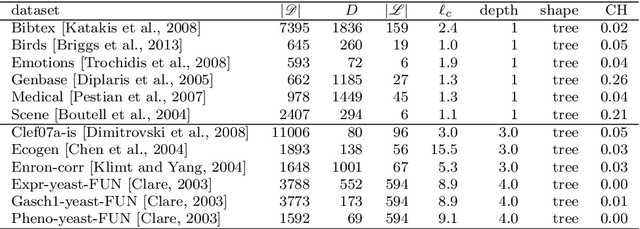
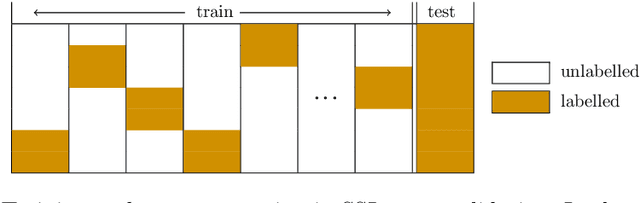
The data made available for analysis are becoming more and more complex along several directions: high dimensionality, number of examples and the amount of labels per example. This poses a variety of challenges for the existing machine learning methods: coping with dataset with a large number of examples that are described in a high-dimensional space and not all examples have labels provided. For example, when investigating the toxicity of chemical compounds there are a lot of compounds available, that can be described with information rich high-dimensional representations, but not all of the compounds have information on their toxicity. To address these challenges, we propose semi-supervised learning of feature ranking. The feature rankings are learned in the context of classification and regression as well as in the context of structured output prediction (multi-label classification, hierarchical multi-label classification and multi-target regression). To the best of our knowledge, this is the first work that treats the task of feature ranking within the semi-supervised structured output prediction context. More specifically, we propose two approaches that are based on tree ensembles and the Relief family of algorithms. The extensive evaluation across 38 benchmark datasets reveals the following: Random Forests perform the best for the classification-like tasks, while for the regression-like tasks Extra-PCTs perform the best, Random Forests are the most efficient method considering induction times across all tasks, and semi-supervised feature rankings outperform their supervised counterpart across a majority of the datasets from the different tasks.
Fuzzy Jaccard Index: A robust comparison of ordered lists
Aug 05, 2020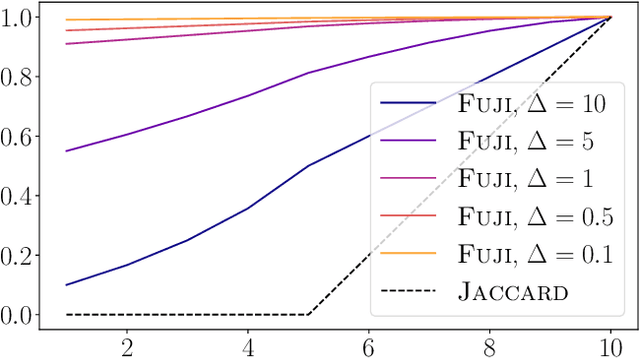
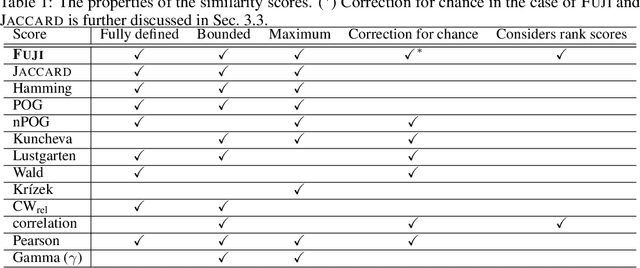
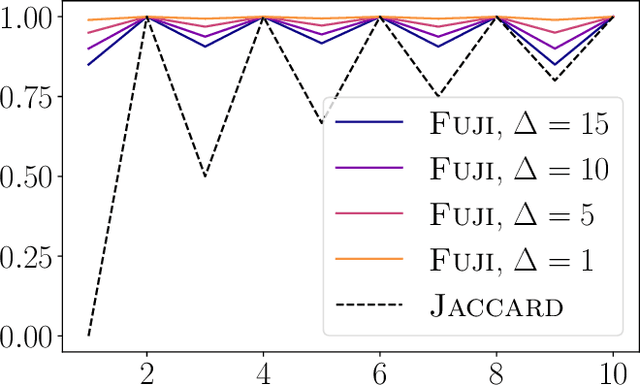
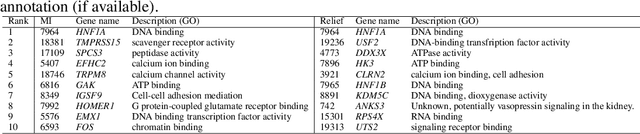
We propose Fuzzy Jaccard Index (FUJI) -- a scale-invariant score for assessment of the similarity between two ranked/ordered lists. FUJI improves upon the Jaccard index by incorporating a membership function which takes into account the particular ranks, thus producing both more stable and more accurate similarity estimates. We provide theoretical insights into the properties of the FUJI score as well as propose an efficient algorithm for computing it. We also present empirical evidence of its performance on different synthetic scenarios. Finally, we demonstrate its utility in a typical machine learning setting -- comparing feature ranking lists relevant to a given machine learning task. In real-life, and in particular high-dimensional domains, where only a small percentage of the whole feature space might be relevant, a robust and confident feature ranking leads to interpretable findings as well as efficient computation and good predictive performance. In such cases, FUJI correctly distinguishes between existing feature ranking approaches, while being more robust and efficient than the benchmark similarity scores.
Machine learning for predicting thermal power consumption of the Mars Express Spacecraft
Sep 03, 2018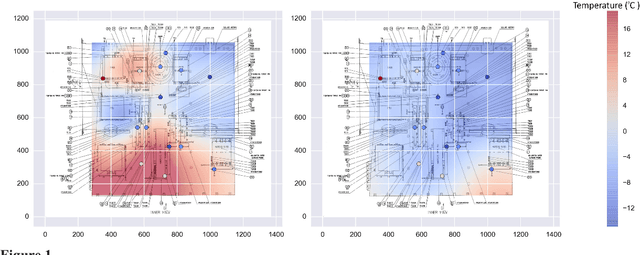
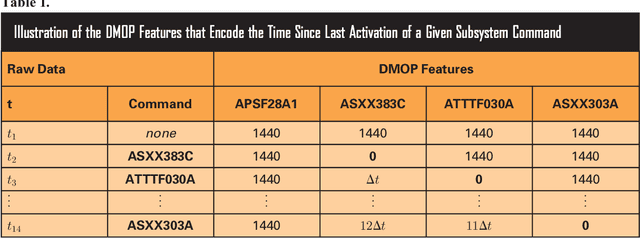
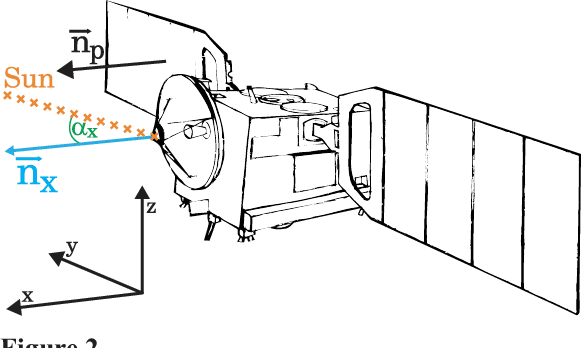
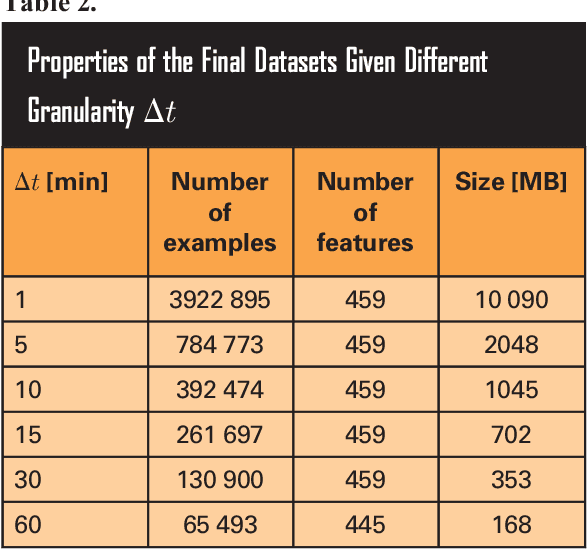
The thermal subsystem of the Mars Express (MEX) spacecraft keeps the on-board equipment within its pre-defined operating temperatures range. To plan and optimize the scientific operations of MEX, its operators need to estimate in advance, as accurately as possible, the power consumption of the thermal subsystem. The remaining power can then be allocated for scientific purposes. We present a machine learning pipeline for efficiently constructing accurate predictive models for predicting the power of the thermal subsystem on board MEX. In particular, we employ state-of-the-art feature engineering approaches for transforming raw telemetry data, in turn used for constructing accurate models with different state-of-the-art machine learning methods. We show that the proposed pipeline considerably improve our previous (competition-winning) work in terms of time efficiency and predictive performance. Moreover, while achieving superior predictive performance, the constructed models also provide important insight into the spacecraft's behavior, allowing for further analyses and optimal planning of MEX's operation.