 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Fusion for Semantic Segmentation of Remote Sensing Earth Observation Data
Oct 01, 2024
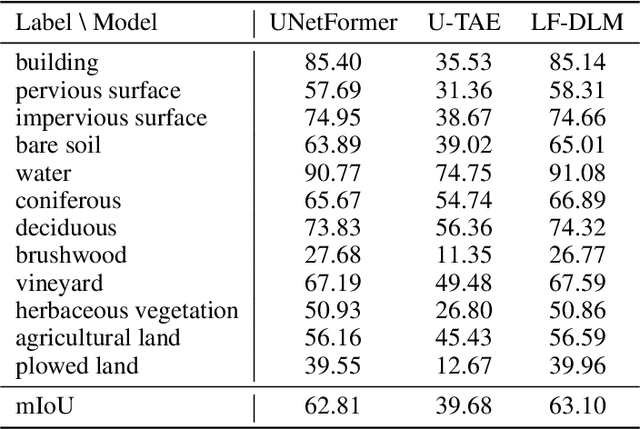
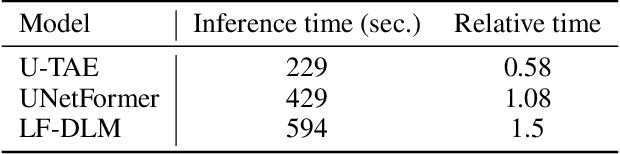
Accurate semantic segmentation of remote sensing imagery is critical for various Earth observation applications, such as land cover mapping, urban planning, and environmental monitoring. However, individual data sources often present limitations for this task. Very High Resolution (VHR) aerial imagery provides rich spatial details but cannot capture temporal information about land cover changes. Conversely, Satellite Image Time Series (SITS) capture temporal dynamics, such as seasonal variations in vegetation, but with limited spatial resolution, making it difficult to distinguish fine-scale objects. This paper proposes a late fusion deep learning model (LF-DLM) for semantic segmentation that leverages the complementary strengths of both VHR aerial imagery and SITS. The proposed model consists of two independent deep learning branches. One branch integrates detailed textures from aerial imagery captured by UNetFormer with a Multi-Axis Vision Transformer (MaxViT) backbone. The other branch captures complex spatio-temporal dynamics from the Sentinel-2 satellite image time series using a U-Net with Temporal Attention Encoder (U-TAE). This approach leads to state-of-the-art results on the FLAIR dataset, a large-scale benchmark for land cover segmentation using multi-source optical imagery. The findings highlight the importance of multi-modality fusion in improving the accuracy and robustness of semantic segmentation in remote sensing applications.
Semantic Segmentation of Unmanned Aerial Vehicle Remote Sensing Images using SegFormer
Oct 01, 2024The escalating use of Unmanned Aerial Vehicles (UAVs) as remote sensing platforms has garnered considerable attention, proving invaluable for ground object recognition. While satellite remote sensing images face limitations in resolution and weather susceptibility, UAV remote sensing, employing low-speed unmanned aircraft, offers enhanced object resolution and agility. The advent of advanced machine learning techniques has propelled significant strides in image analysis, particularly in semantic segmentation for UAV remote sensing images. This paper evaluates the effectiveness and efficiency of SegFormer, a semantic segmentation framework, for the semantic segmentation of UAV images. SegFormer variants, ranging from real-time (B0) to high-performance (B5) models, are assessed using the UAVid dataset tailored for semantic segmentation tasks. The research details the architecture and training procedures specific to SegFormer in the context of UAV semantic segmentation. Experimental results showcase the model's performance on benchmark dataset, highlighting its ability to accurately delineate objects and land cover features in diverse UAV scenarios, leading to both high efficiency and performance.