 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination or Creativity: How to Evaluate AI-Generated Scientific Stories?
Feb 02, 2026Generative AI can turn scientific articles into narratives for diverse audiences, but evaluating these stories remains challenging. Storytelling demands abstraction, simplification, and pedagogical creativity-qualities that are not often well-captured by standard summarization metrics. Meanwhile, factual hallucinations are critical in scientific contexts, yet, detectors often misclassify legitimate narrative reformulations or prove unstable when creativity is involved. In this work, we propose StoryScore, a composite metric for evaluating AI-generated scientific stories. StoryScore integrates semantic alignment, lexical grounding, narrative control, structural fidelity, redundancy avoidance, and entity-level hallucination detection into a unified framework. Our analysis also reveals why many hallucination detection methods fail to distinguish pedagogical creativity from factual errors, highlighting a key limitation: while automatic metrics can effectively assess semantic similarity with original content, they struggle to evaluate how it is narrated and controlled.
Multimodal Metadata Assignment for Cultural Heritage Artifacts
Jun 01, 2024We develop a multimodal classifier for the cultural heritage domain using a late fusion approach and introduce a novel dataset. The three modalities are Image, Text, and Tabular data. We based the image classifier on a ResNet convolutional neural network architecture and the text classifier on a multilingual transformer architecture (XML-Roberta). Both are trained as multitask classifiers and use the focal loss to handle class imbalance. Tabular data and late fusion are handled by Gradient Tree Boosting. We also show how we leveraged specific data models and taxonomy in a Knowledge Graph to create the dataset and to store classification results. All individual classifiers accurately predict missing properties in the digitized silk artifacts, with the multimodal approach providing the best results.
Improving (Re-)Usability of Musical Datasets: An Overview of the DOREMUS Project
May 06, 2024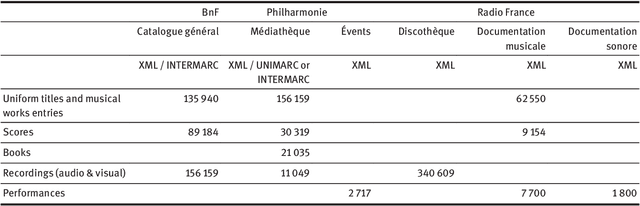
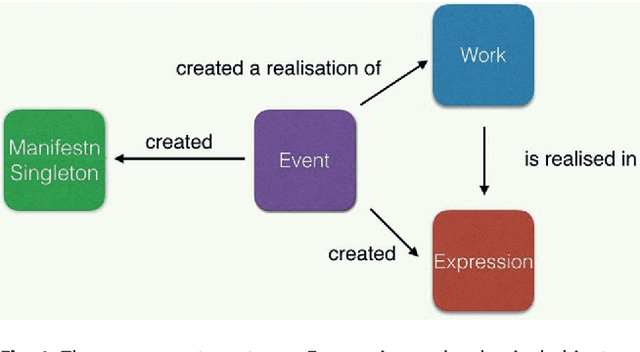
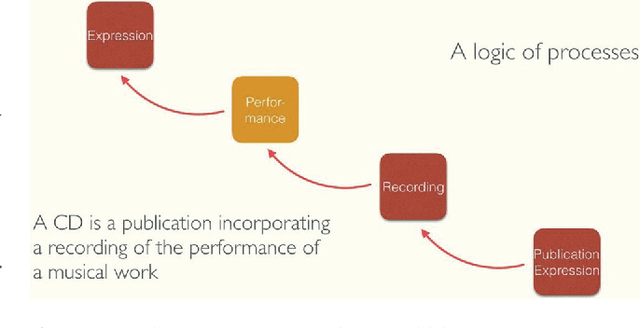
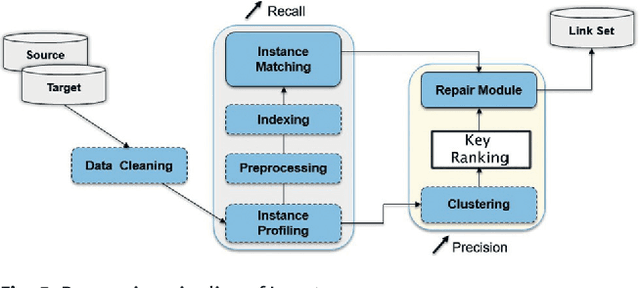
DOREMUS works on a better description of music by building new tools to link and explore the data of three French institutions. This paper gives an overview of the data model based on FRBRoo, explains the conversion and linking processes using linked data technologies and presents the prototypes created to consume the data according to the web users' needs.
Searching News Articles Using an Event Knowledge Graph Leveraged by Wikidata
Apr 11, 2019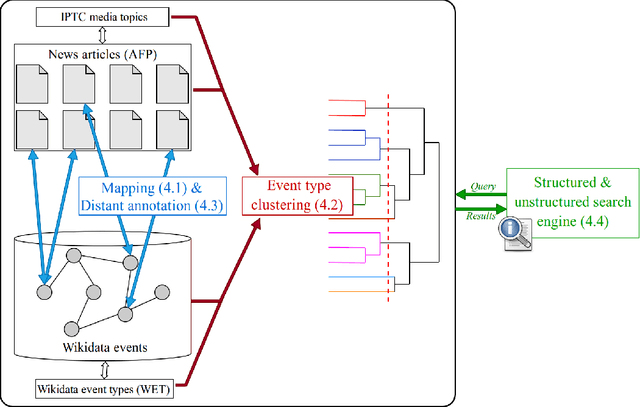
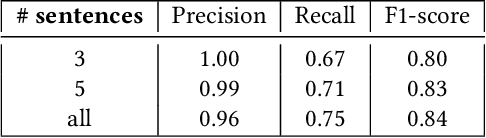
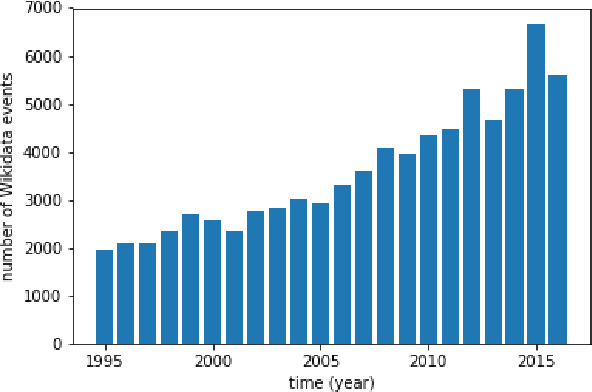

News agencies produce thousands of multimedia stories describing events happening in the world that are either scheduled such as sports competitions, political summits and elections, or breaking events such as military conflicts, terrorist attacks, natural disasters, etc. When writing up those stories, journalists refer to contextual background and to compare with past similar events. However, searching for precise facts described in stories is hard. In this paper, we propose a general method that leverages the Wikidata knowledge base to produce semantic annotations of news articles. Next, we describe a semantic search engine that supports both keyword based search in news articles and structured data search providing filters for properties belonging to specific event schemas that are automatically inferred.
Analysis of Named Entity Recognition and Linking for Tweets
Oct 27, 2014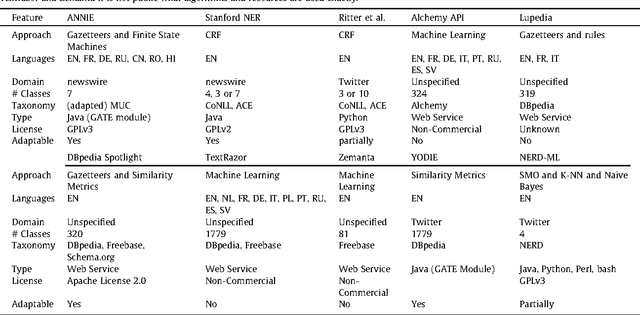
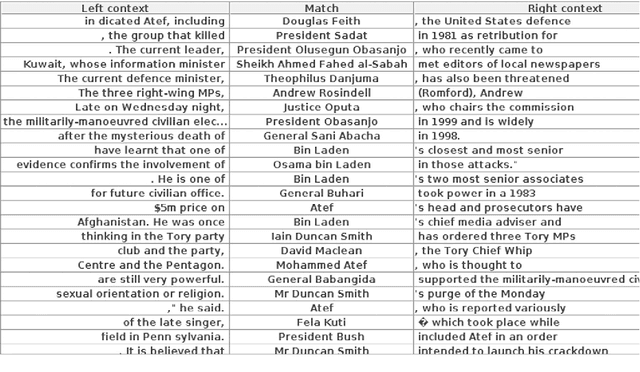

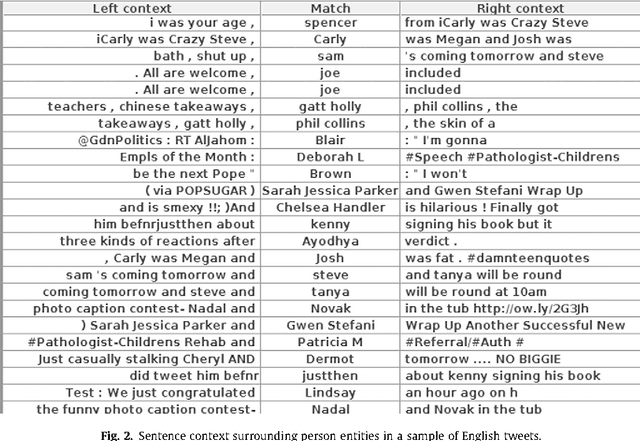
Applying natural language processing for mining and intelligent information access to tweets (a form of microblog) is a challenging, emerging research area. Unlike carefully authored news text and other longer content, tweets pose a number of new challenges, due to their short, noisy, context-dependent, and dynamic nature. Information extraction from tweets is typically performed in a pipeline, comprising consecutive stages of language identification, tokenisation, part-of-speech tagging, named entity recognition and entity disambiguation (e.g. with respect to DBpedia). In this work, we describe a new Twitter entity disambiguation dataset, and conduct an empirical analysis of named entity recognition and disambiguation, investigating how robust a number of state-of-the-art systems are on such noisy texts, what the main sources of error are, and which problems should be further investigated to improve the state of the art.
* 35 pages, accepted to journal Information Processing and Management