 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Show Programmes to Data: Designing a Workflow to Make Performing Arts Ephemera Accessible Through Language Models
Dec 08, 2025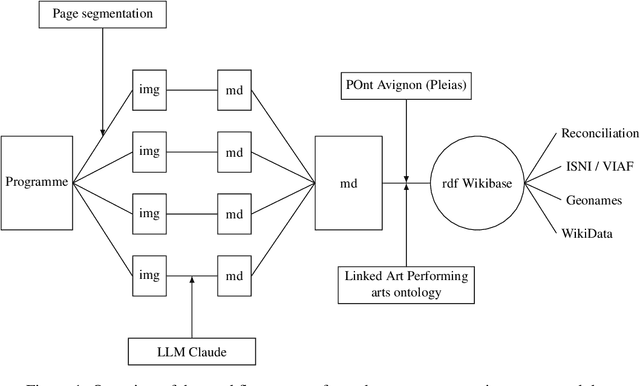


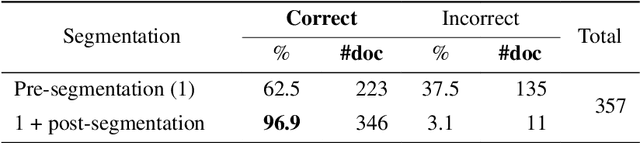
Many heritage institutions hold extensive collections of theatre programmes, which remain largely underused due to their complex layouts and lack of structured metadata. In this paper, we present a workflow for transforming such documents into structured data using a combination of multimodal large language models (LLMs), an ontology-based reasoning model, and a custom extension of the Linked Art framework. We show how vision-language models can accurately parse and transcribe born-digital and digitised programmes, achieving over 98% of correct extraction. To overcome the challenges of semantic annotation, we train a reasoning model (POntAvignon) using reinforcement learning with both formal and semantic rewards. This approach enables automated RDF triple generation and supports alignment with existing knowledge graphs. Through a case study based on the Festival d'Avignon corpus, we demonstrate the potential for large-scale, ontology-driven analysis of performing arts data. Our results open new possibilities for interoperable, explainable, and sustainable computational theatre historiography.
Improving (Re-)Usability of Musical Datasets: An Overview of the DOREMUS Project
May 06, 2024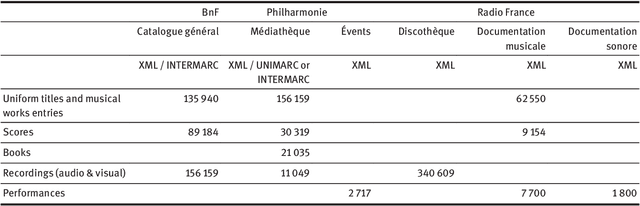
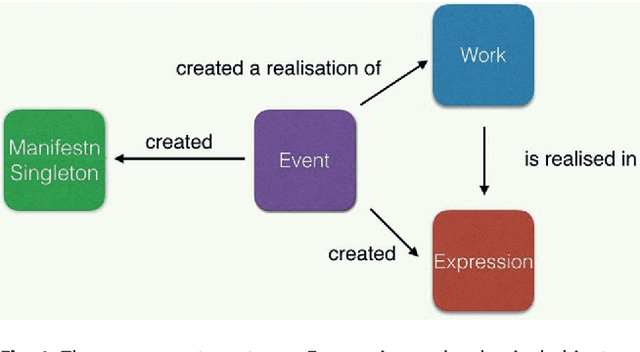
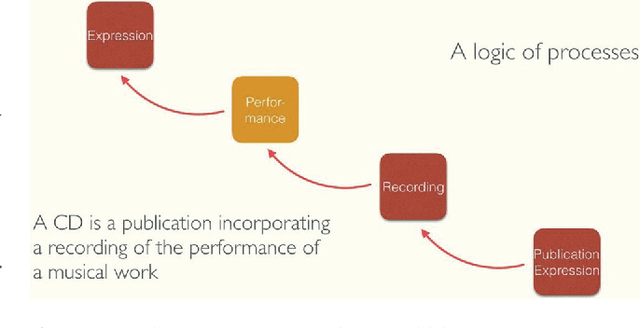
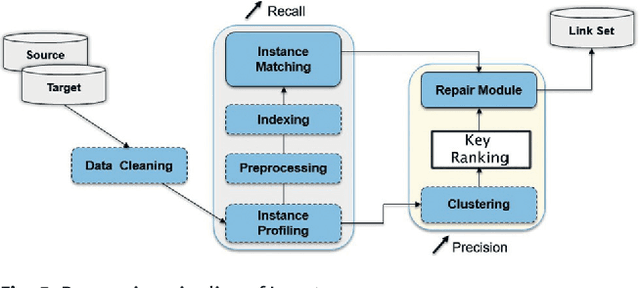
DOREMUS works on a better description of music by building new tools to link and explore the data of three French institutions. This paper gives an overview of the data model based on FRBRoo, explains the conversion and linking processes using linked data technologies and presents the prototypes created to consume the data according to the web users' needs.
Receiving an algorithmic recommendation based on documentary filmmaking techniques
Sep 08, 2023This article analyzes the reception of a novel algorithmic recommendation of documentary films by a panel of moviegoers of the T{\"e}nk platform. In order to propose an alternative to recommendations based on a thematic classification, the director or the production period, a set of metadata has been elaborated within the framework of this experimentation in order to characterize the great variety of ``documentary filmmaking dispositifs'' . The goal is to investigate the different ways in which the platform's film lovers appropriate a personalized recommendation of 4 documentaries with similar or similar filmmaking dispositifs. To conclude, the contributions and limits of this proof of concept are discussed in order to sketch out avenues of reflection for improving the instrumented mediation of documentary films.
* in French language
Corpus sp{é}cialis{é} et ressource de sp{é}cialit{é}
Jun 19, 2015
"Semantic Atlas" is a mathematic and statistic model to visualise word senses according to relations between words. The model, that has been applied to proximity relations from a corpus, has shown its ability to distinguish word senses as the corpus' contributors comprehend them. We propose to use the model and a specialised corpus in order to create automatically a specialised dictionary relative to the corpus' domain. A morpho-syntactic analysis performed on the corpus makes it possible to create the dictionary from syntactic relations between lexical units. The semantic resource can be used to navigate semantically - and not only lexically - through the corpus, to create classical dictionaries or for diachronic studies of the language.
* 16 pages, in French
Du corpus au dictionnaire
Jan 26, 2009
In this article, we propose an automatic process to build multi-lingual lexico-semantic resources. The goal of these resources is to browse semantically textual information contained in texts of different languages. This method uses a mathematical model called Atlas s\'emantiques in order to represent the different senses of each word. It uses the linguistic relations between words to create graphs that are projected into a semantic space. These projections constitute semantic maps that denote the sense trends of each given word. This model is fed with syntactic relations between words extracted from a corpus. Therefore, the lexico-semantic resource produced describes all the words and all their meanings observed in the corpus. The sense trends are expressed by syntactic contexts, typical for a given meaning. The link between each sense trend and the utterances used to build the sense trend are also stored in an index. Thus all the instances of a word in a particular sense are linked and can be browsed easily. And by using several corpora of different languages, several resources are built that correspond with each other through languages. It makes it possible to browse information through languages thanks to syntactic contexts translations (even if some of them are partial).
Interroger un corpus par le sens
May 31, 2008In textual knowledge management, statistical methods prevail. Nonetheless, some difficulties cannot be overcome by these methodologies. I propose a symbolic approach using a complete textual analysis to identify which analysis level can improve the the answers provided by a system. The approach identifies word senses and relation between words and generates as many rephrasings as possible. Using synonyms and derivative, the system provides new utterances without changing the original meaning of the sentences. Such a way, an information can be retrieved whatever the question or answer's wording may be.
* 13 pp
Managing conflicts between users in Wikipedia
May 30, 2008
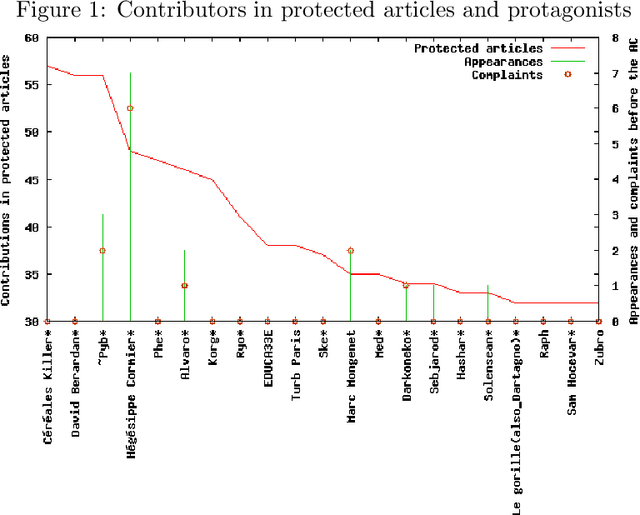

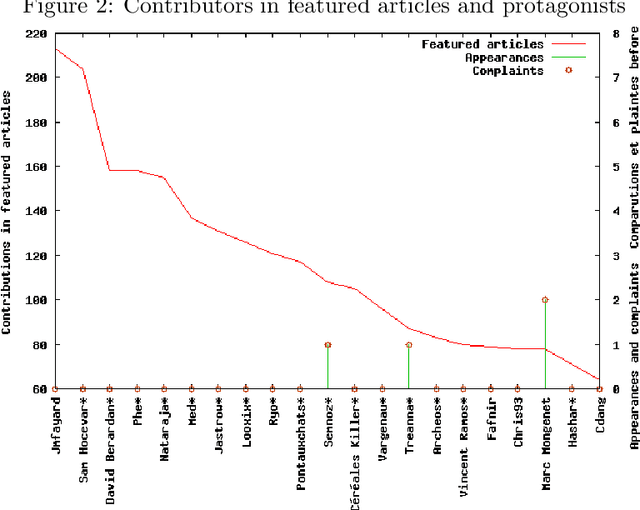
Wikipedia is nowadays a widely used encyclopedia, and one of the most visible sites on the Internet. Its strong principle of collaborative work and free editing sometimes generates disputes due to disagreements between users. In this article we study how the wikipedian community resolves the conflicts and which roles do wikipedian choose in this process. We observed the users behavior both in the article talk pages, and in the Arbitration Committee pages specifically dedicated to serious disputes. We first set up a users typology according to their involvement in conflicts and their publishing and management activity in the encyclopedia. We then used those user types to describe users behavior in contributing to articles that are tagged by the wikipedian community as being in conflict with the official guidelines of Wikipedia, or conversely as being well featured.
* 12 pp
La fiabilité des informations sur le web
May 30, 2008Online IR tools have to take into account new phenomena linked to the appearance of blogs, wiki and other collaborative publications. Among these collaborative sites, Wikipedia represents a crucial source of information. However, the quality of this information has been recently questionned. A better knowledge of the contributors' behaviors should help users navigate through information whose quality may vary from one source to another. In order to explore this idea, we present an analysis of the role of different types of contributors in the control of the publication of conflictual articles.
* 8 pp