 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganization and Independence or Interdependence? Study of the Neurophysiological Dynamics of Syntactic and Semantic Processing
Apr 16, 2018

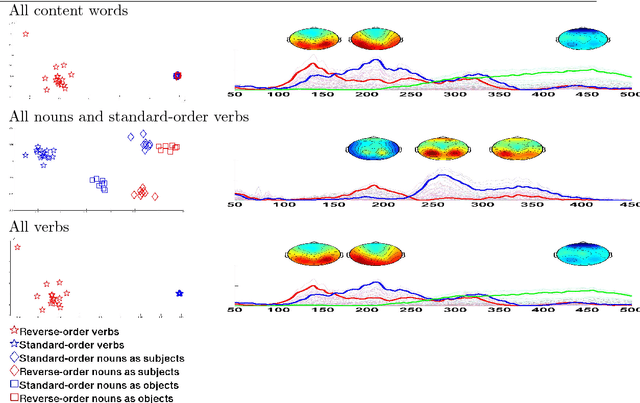

In this article we present a multivariate model for determining the different syntactic, semantic, and form (surface-structure) processes underlying the comprehension of simple phrases. This model is applied to EEG signals recorded during a reading task. The results show a hierarchical precedence of the neurolinguistic processes : form, then syntactic and lastly semantic processes. We also found (a) that verbs are at the heart of phrase syntax processing, (b) an interaction between syntactic movement within the phrase, and semantic processes derived from a person-centered reference frame. Eigenvectors of the multivariate model provide electrode-times profiles that separate the distinctive linguistic processes and/or highlight their interaction. The accordance of these findings with different linguistic theories are discussed.
Random vector generation of a semantic space
Mar 05, 2017We show how random vectors and random projection can be implemented in the usual vector space model to construct a Euclidean semantic space from a French synonym dictionary. We evaluate theoretically the resulting noise and show the experimental distribution of the similarities of terms in a neighborhood according to the choice of parameters. We also show that the Schmidt orthogonalization process is applicable and can be used to separate homonyms with distinct semantic meanings. Neighboring terms are easily arranged into semantically significant clusters which are well suited to the generation of realistic lists of synonyms and to such applications as word selection for automatic text generation. This process, applicable to any language, can easily be extended to collocations, is extremely fast and can be updated in real time, whenever new synonyms are proposed.
A Novel Bilingual Word Embedding Method for Lexical Translation Using Bilingual Sense Clique
Aug 02, 2016

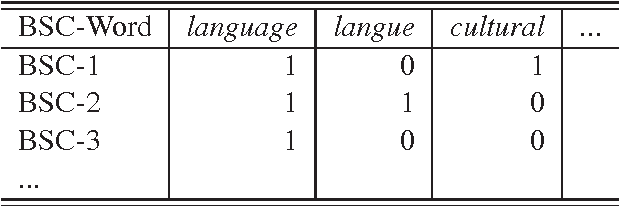

Most of the existing methods for bilingual word embedding only consider shallow context or simple co-occurrence information. In this paper, we propose a latent bilingual sense unit (Bilingual Sense Clique, BSC), which is derived from a maximum complete sub-graph of pointwise mutual information based graph over bilingual corpus. In this way, we treat source and target words equally and a separated bilingual projection processing that have to be used in most existing works is not necessary any more. Several dimension reduction methods are evaluated to summarize the BSC-word relationship. The proposed method is evaluated on bilingual lexicon translation tasks and empirical results show that bilingual sense embedding methods outperform existing bilingual word embedding methods.
Corpus sp{é}cialis{é} et ressource de sp{é}cialit{é}
Jun 19, 2015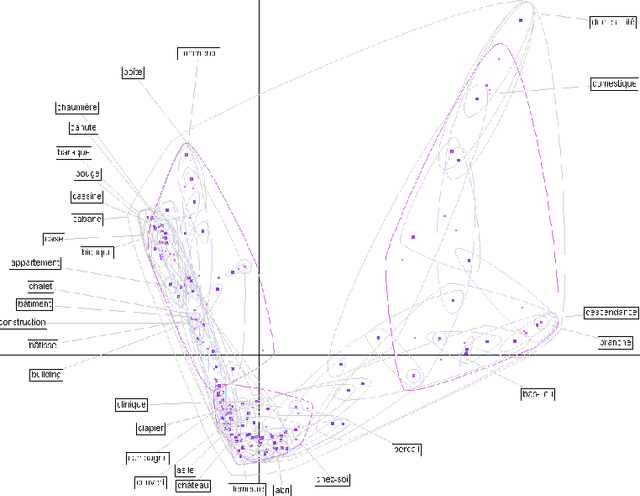
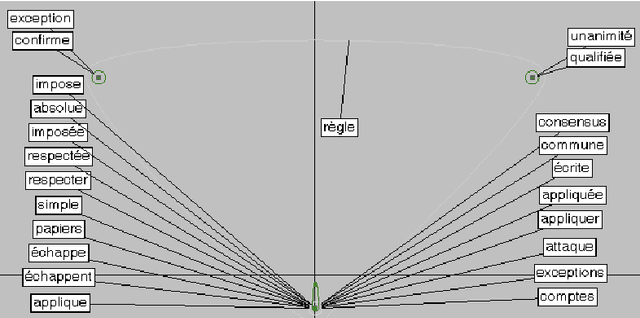
"Semantic Atlas" is a mathematic and statistic model to visualise word senses according to relations between words. The model, that has been applied to proximity relations from a corpus, has shown its ability to distinguish word senses as the corpus' contributors comprehend them. We propose to use the model and a specialised corpus in order to create automatically a specialised dictionary relative to the corpus' domain. A morpho-syntactic analysis performed on the corpus makes it possible to create the dictionary from syntactic relations between lexical units. The semantic resource can be used to navigate semantically - and not only lexically - through the corpus, to create classical dictionaries or for diachronic studies of the language.
* 16 pages, in French
Du corpus au dictionnaire
Jan 26, 2009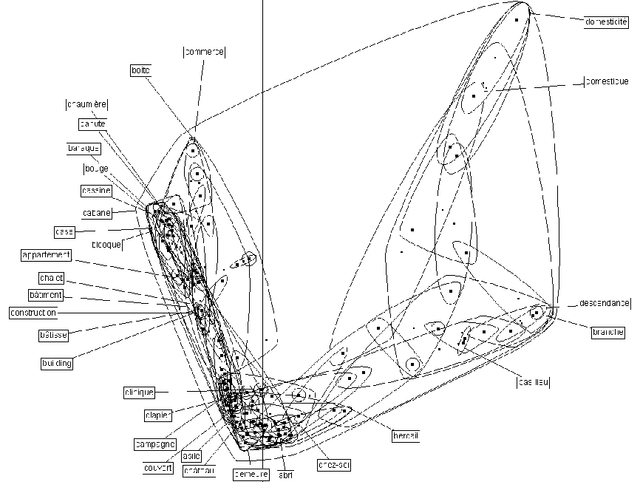
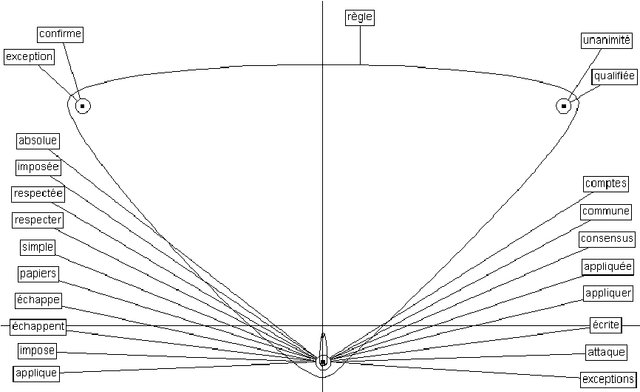
In this article, we propose an automatic process to build multi-lingual lexico-semantic resources. The goal of these resources is to browse semantically textual information contained in texts of different languages. This method uses a mathematical model called Atlas s\'emantiques in order to represent the different senses of each word. It uses the linguistic relations between words to create graphs that are projected into a semantic space. These projections constitute semantic maps that denote the sense trends of each given word. This model is fed with syntactic relations between words extracted from a corpus. Therefore, the lexico-semantic resource produced describes all the words and all their meanings observed in the corpus. The sense trends are expressed by syntactic contexts, typical for a given meaning. The link between each sense trend and the utterances used to build the sense trend are also stored in an index. Thus all the instances of a word in a particular sense are linked and can be browsed easily. And by using several corpora of different languages, several resources are built that correspond with each other through languages. It makes it possible to browse information through languages thanks to syntactic contexts translations (even if some of them are partial).