 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised detection of diachronic word sense evolution
May 30, 2018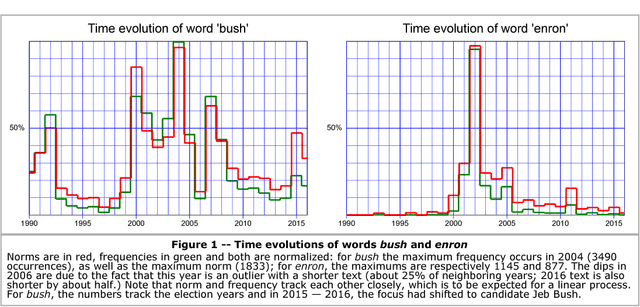
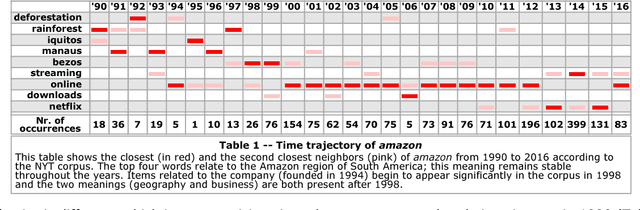
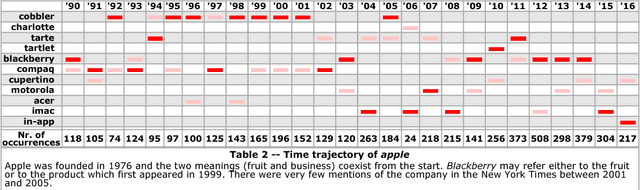

Most words have several senses and connotations which evolve in time due to semantic shift, so that closely related words may gain different or even opposite meanings over the years. This evolution is very relevant to the study of language and of cultural changes, but the tools currently available for diachronic semantic analysis have significant, inherent limitations and are not suitable for real-time analysis. In this article, we demonstrate how the linearity of random vectors techniques enables building time series of congruent word embeddings (or semantic spaces) which can then be compared and combined linearly without loss of precision over any time period to detect diachronic semantic shifts. We show how this approach yields time trajectories of polysemous words such as amazon or apple, enables following semantic drifts and gender bias across time, reveals the shifting instantiations of stable concepts such as hurricane or president. This very fast, linear approach can easily be distributed over many processors to follow in real time streams of social media such as Twitter or Facebook; the resulting, time-dependent semantic spaces can then be combined at will by simple additions or subtractions.
Unsupervised word sense disambiguation in dynamic semantic spaces
Feb 16, 2018
In this paper, we are mainly concerned with the ability to quickly and automatically distinguish word senses in dynamic semantic spaces in which new terms and new senses appear frequently. Such spaces are built '"on the fly" from constantly evolving data sets such as Wikipedia, repositories of patent grants and applications, or large sets of legal documents for Technology Assisted Review and e-discovery. This immediacy rules out supervision as well as the use of a priori training sets. We show that the various senses of a term can be automatically made apparent with a simple clustering algorithm, each sense being a vector in the semantic space. While we only consider here semantic spaces built by using random vectors, this algorithm should work with any kind of embedding, provided meaningful similarities between terms can be computed and do fulfill at least the two basic conditions that terms which close meanings have high similarities and terms with unrelated meanings have near-zero similarities.
Semantic Technology-Assisted Review (STAR) Document analysis and monitoring using random vectors
Nov 29, 2017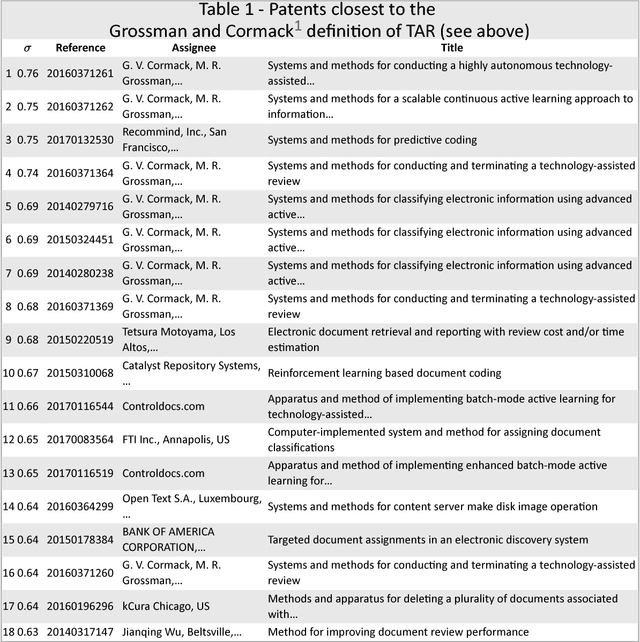
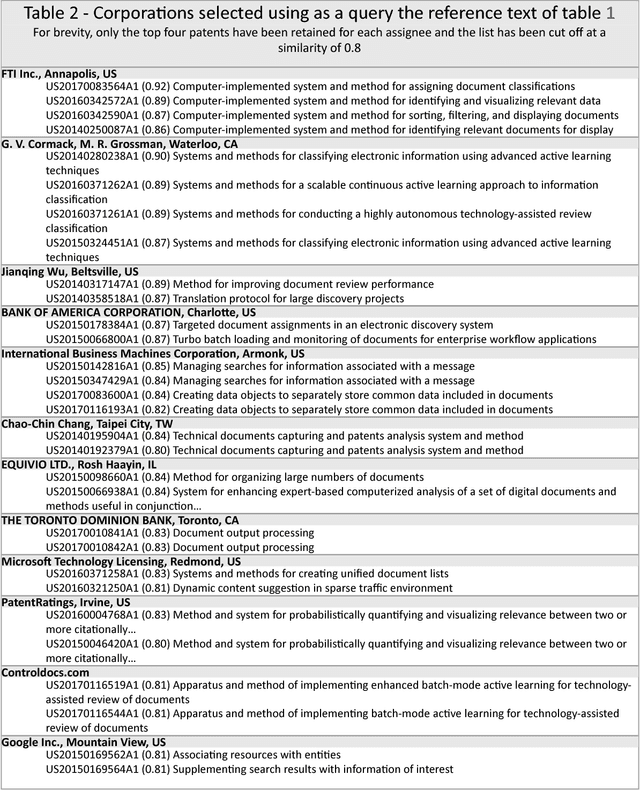
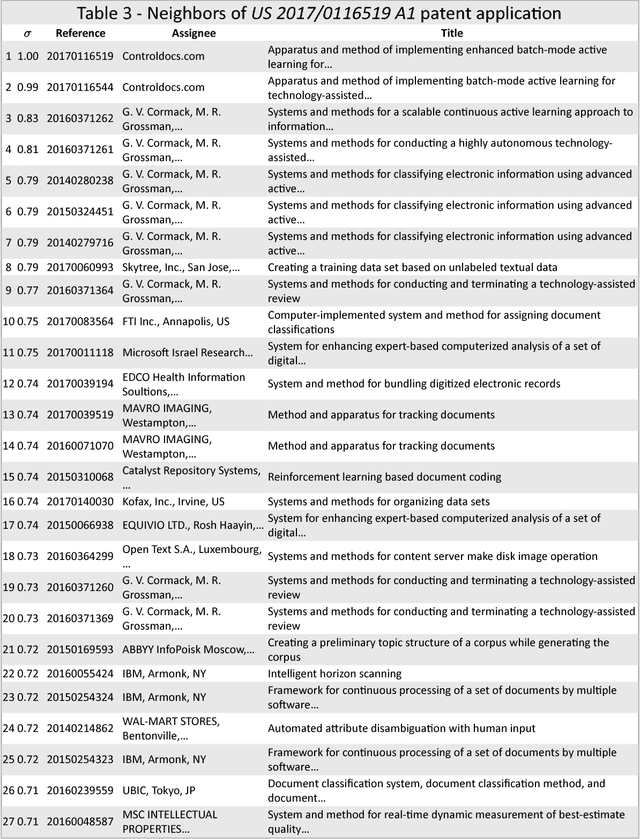
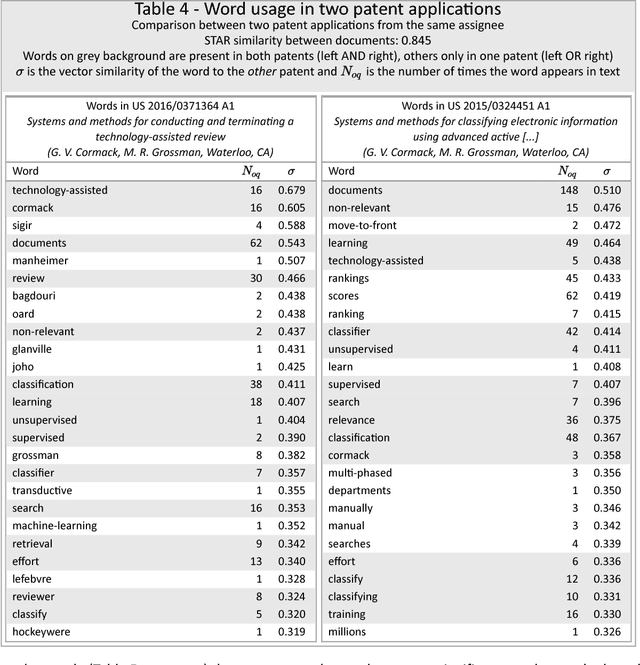
The review and analysis of large collections of documents and the periodic monitoring of new additions thereto has greatly benefited from new developments in computer software. This paper demonstrates how using random vectors to construct a low-dimensional Euclidean space embedding words and documents enables fast and accurate computation of semantic similarities between them. With this technique of Semantic Technology-Assisted Review (STAR), documents can be selected, compared, classified, summarized and evaluated very quickly with minimal expert involvement and high-quality results.
Random vector generation of a semantic space
Mar 05, 2017We show how random vectors and random projection can be implemented in the usual vector space model to construct a Euclidean semantic space from a French synonym dictionary. We evaluate theoretically the resulting noise and show the experimental distribution of the similarities of terms in a neighborhood according to the choice of parameters. We also show that the Schmidt orthogonalization process is applicable and can be used to separate homonyms with distinct semantic meanings. Neighboring terms are easily arranged into semantically significant clusters which are well suited to the generation of realistic lists of synonyms and to such applications as word selection for automatic text generation. This process, applicable to any language, can easily be extended to collocations, is extremely fast and can be updated in real time, whenever new synonyms are proposed.