Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Technology-Assisted Review (STAR) Document analysis and monitoring using random vectors
Paper and Code
Nov 29, 2017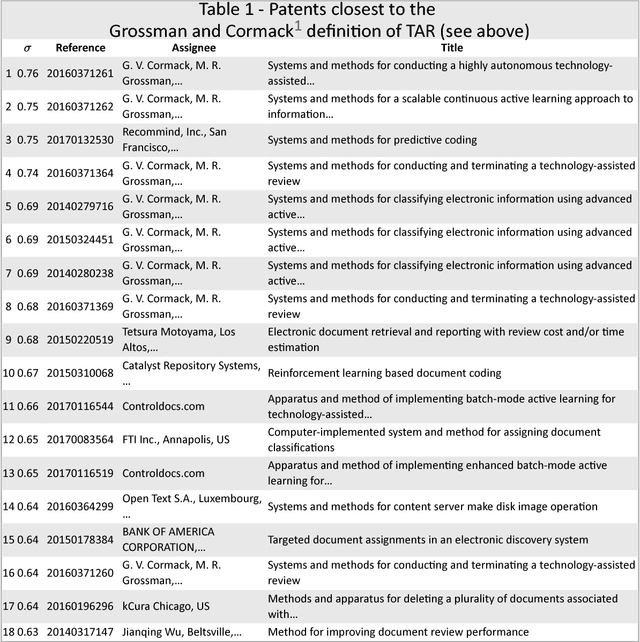
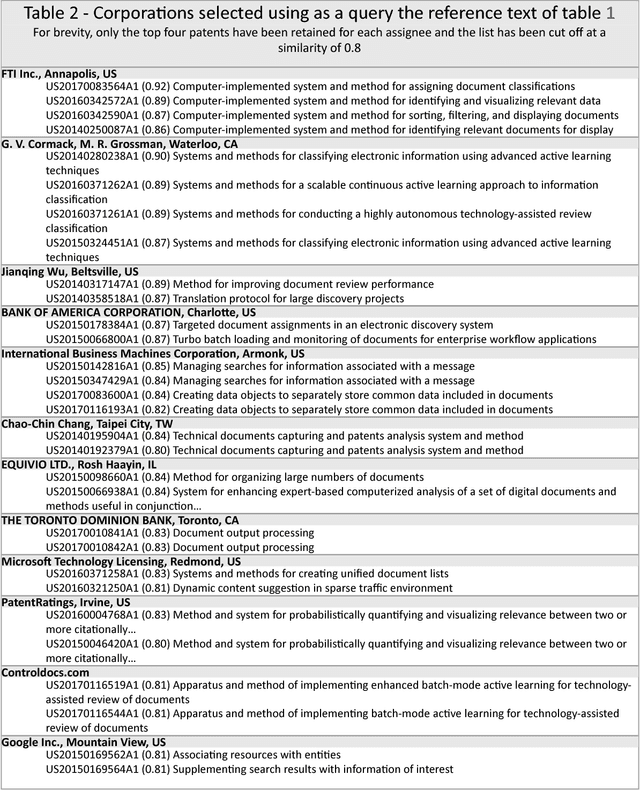
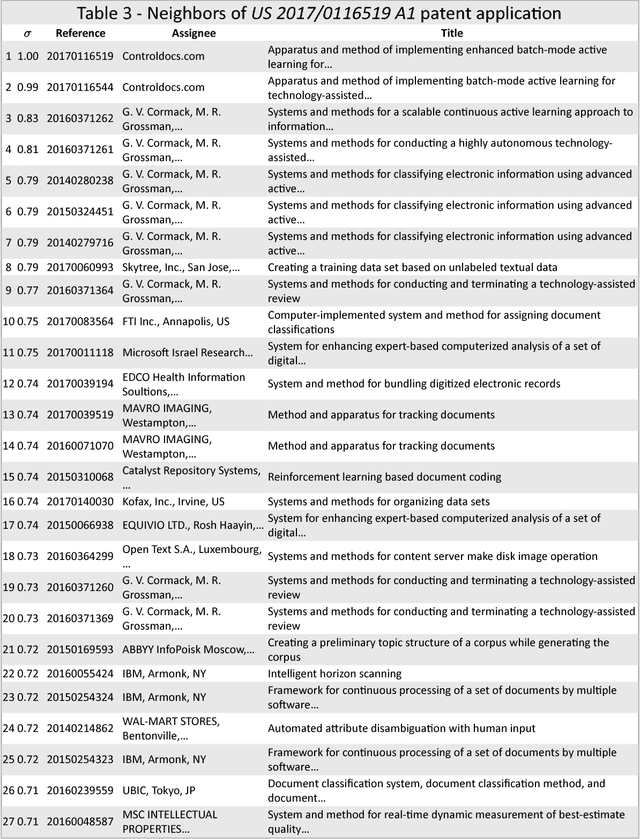
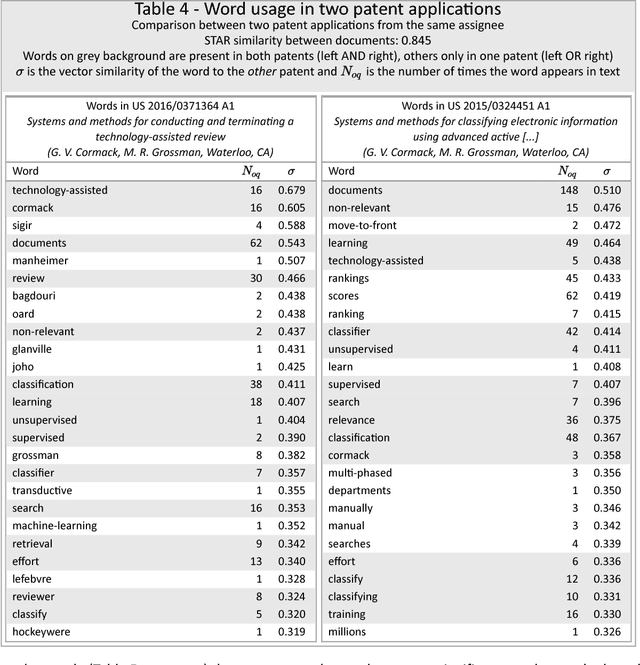
The review and analysis of large collections of documents and the periodic monitoring of new additions thereto has greatly benefited from new developments in computer software. This paper demonstrates how using random vectors to construct a low-dimensional Euclidean space embedding words and documents enables fast and accurate computation of semantic similarities between them. With this technique of Semantic Technology-Assisted Review (STAR), documents can be selected, compared, classified, summarized and evaluated very quickly with minimal expert involvement and high-quality results.
* 13 pages, 9 tables, 21 references
View paper on