 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024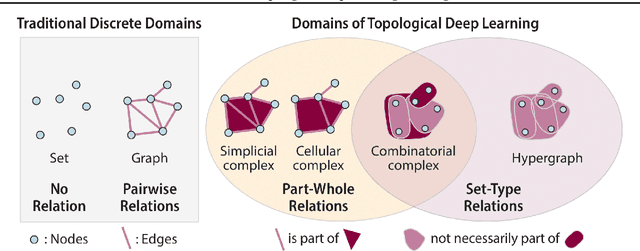
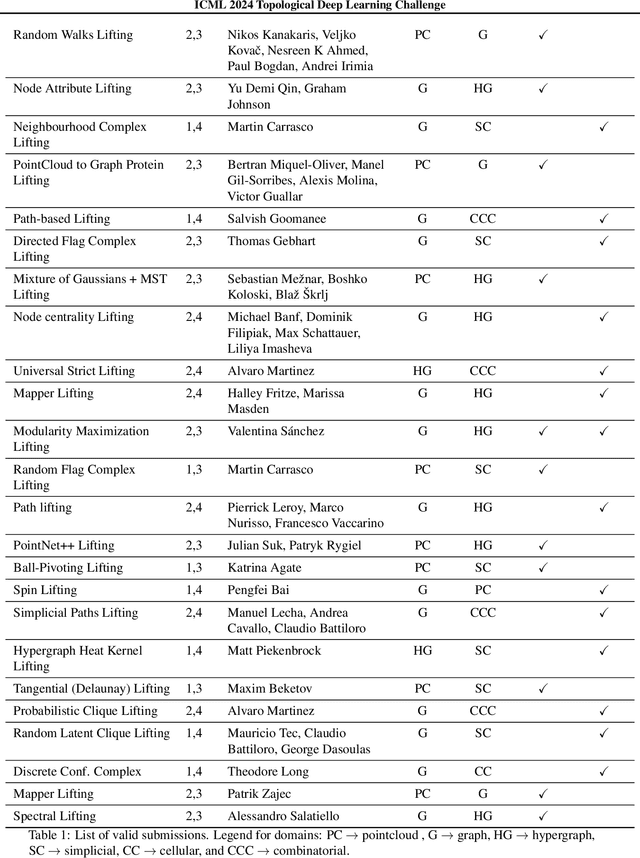
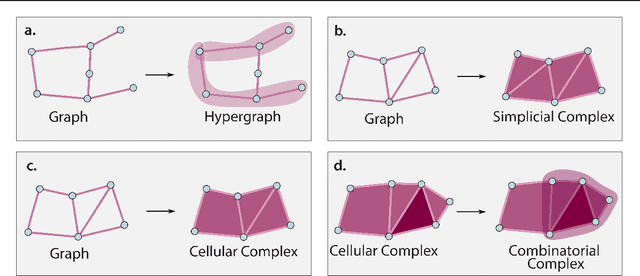
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Robust Anomaly Map Assisted Multiple Defect Detection with Supervised Classification Techniques
Dec 19, 2022



Industry 4.0 aims to optimize the manufacturing environment by leveraging new technological advances, such as new sensing capabilities and artificial intelligence. The DRAEM technique has shown state-of-the-art performance for unsupervised classification. The ability to create anomaly maps highlighting areas where defects probably lie can be leveraged to provide cues to supervised classification models and enhance their performance. Our research shows that the best performance is achieved when training a defect detection model by providing an image and the corresponding anomaly map as input. Furthermore, such a setting provides consistent performance when framing the defect detection as a binary or multiclass classification problem and is not affected by class balancing policies. We performed the experiments on three datasets with real-world data provided by Philips Consumer Lifestyle BV.
Synthetic Data Augmentation Using GAN For Improved Automated Visual Inspection
Dec 19, 2022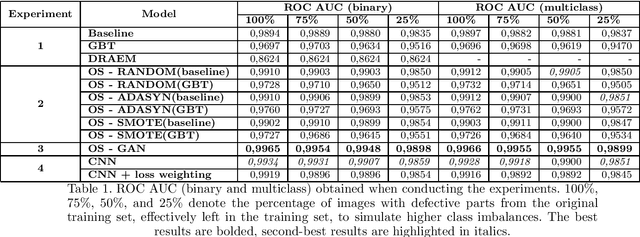
Quality control is a crucial activity performed by manufacturing companies to ensure their products conform to the requirements and specifications. The introduction of artificial intelligence models enables to automate the visual quality inspection, speeding up the inspection process and ensuring all products are evaluated under the same criteria. In this research, we compare supervised and unsupervised defect detection techniques and explore data augmentation techniques to mitigate the data imbalance in the context of automated visual inspection. Furthermore, we use Generative Adversarial Networks for data augmentation to enhance the classifiers' discriminative performance. Our results show that state-of-the-art unsupervised defect detection does not match the performance of supervised models but can be used to reduce the labeling workload by more than 50%. Furthermore, the best classification performance was achieved considering GAN-based data generation with AUC ROC scores equal to or higher than 0,9898, even when increasing the dataset imbalance by leaving only 25\% of the images denoting defective products. We performed the research with real-world data provided by Philips Consumer Lifestyle BV.
Active Learning and Approximate Model Calibration for Automated Visual Inspection in Manufacturing
Sep 12, 2022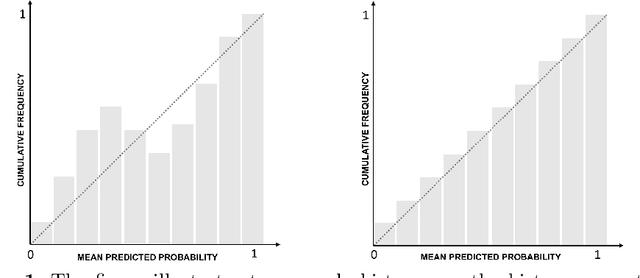
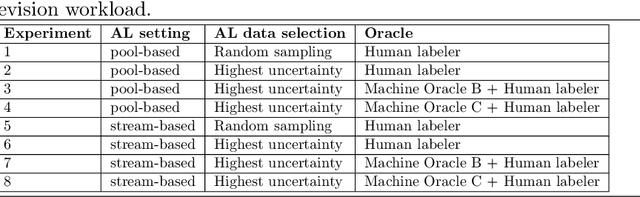
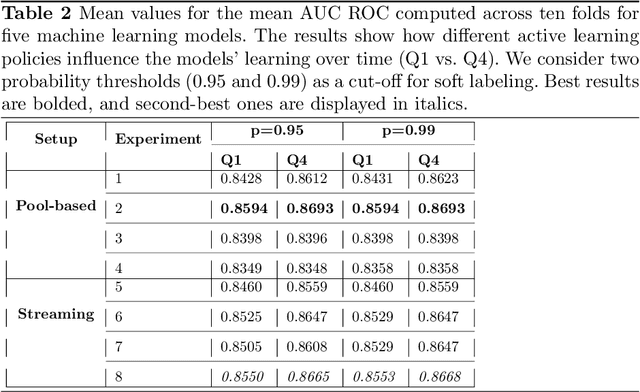

Quality control is a crucial activity performed by manufacturing enterprises to ensure that their products meet quality standards and avoid potential damage to the brand's reputation. The decreased cost of sensors and connectivity enabled increasing digitalization of manufacturing. In addition, artificial intelligence enables higher degrees of automation, reducing overall costs and time required for defect inspection. This research compares three active learning approaches (with single and multiple oracles) to visual inspection. We propose a novel approach to probabilities calibration of classification models and two new metrics to assess the performance of the calibration without the need for ground truth. We performed experiments on real-world data provided by Philips Consumer Lifestyle BV. Our results show that explored active learning settings can reduce the data labeling effort by between three and four percent without detriment to the overall quality goals, considering a threshold of p=0.95. Furthermore, we show that the proposed metrics successfully capture relevant information otherwise available to metrics used up to date only through ground truth data. Therefore, the proposed metrics can be used to estimate the quality of models' probability calibration without committing to a labeling effort to obtain ground truth data.
Enriching Artificial Intelligence Explanations with Knowledge Fragments
Apr 12, 2022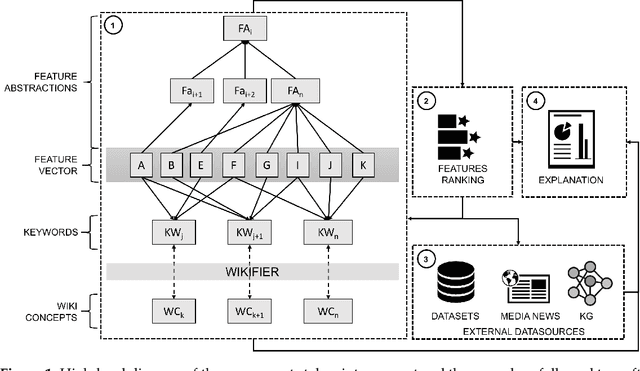
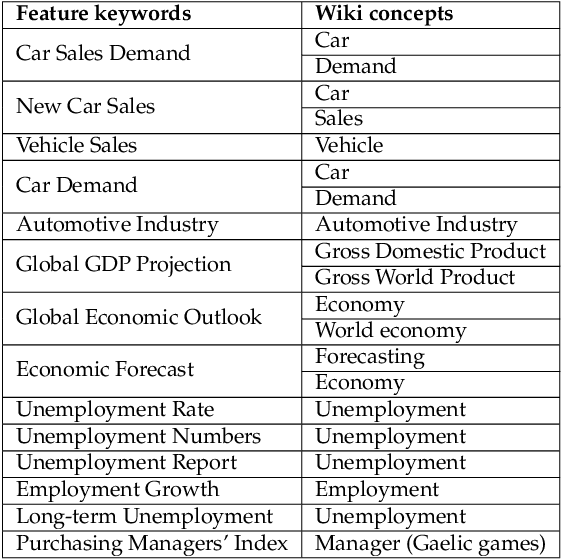
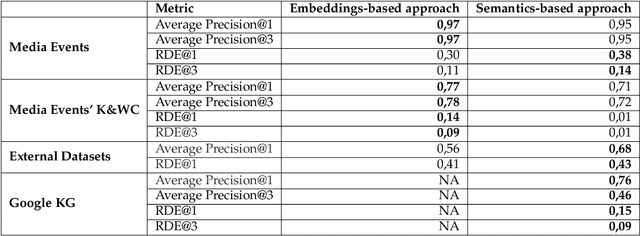
Artificial Intelligence models are increasingly used in manufacturing to inform decision-making. Responsible decision-making requires accurate forecasts and an understanding of the models' behavior. Furthermore, the insights into models' rationale can be enriched with domain knowledge. This research builds explanations considering feature rankings for a particular forecast, enriching them with media news entries, datasets' metadata, and entries from the Google Knowledge Graph. We compare two approaches (embeddings-based and semantic-based) on a real-world use case regarding demand forecasting.
Human-Centric Artificial Intelligence Architecture for Industry 5.0 Applications
Mar 21, 2022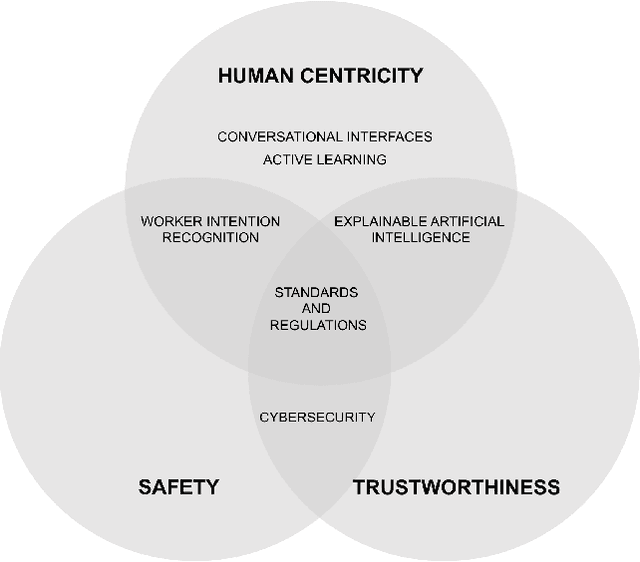
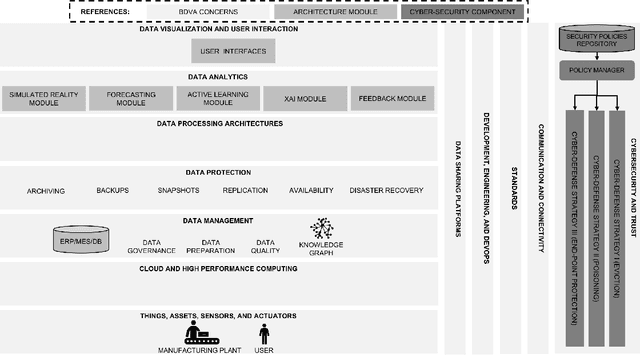
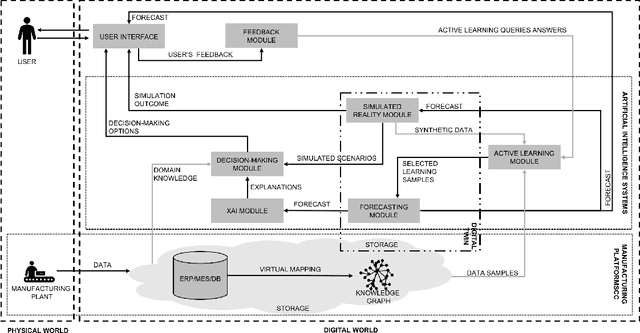

Human-centricity is the core value behind the evolution of manufacturing towards Industry 5.0. Nevertheless, there is a lack of architecture that considers safety, trustworthiness, and human-centricity at its core. Therefore, we propose an architecture that integrates Artificial Intelligence (Active Learning, Forecasting, Explainable Artificial Intelligence), simulated reality, decision-making, and users' feedback, focusing on synergies between humans and machines. Furthermore, we align the proposed architecture with the Big Data Value Association Reference Architecture Model. Finally, we validate it on two use cases from real-world case studies.
XAI-KG: knowledge graph to support XAI and decision-making in manufacturing
May 06, 2021The increasing adoption of artificial intelligence requires accurate forecasts and means to understand the reasoning of artificial intelligence models behind such a forecast. Explainable Artificial Intelligence (XAI) aims to provide cues for why a model issued a certain prediction. Such cues are of utmost importance to decision-making since they provide insights on the features that influenced most certain forecasts and let the user decide if the forecast can be trusted. Though many techniques were developed to explain black-box models, little research was done on assessing the quality of those explanations and their influence on decision-making. We propose an ontology and knowledge graph to support collecting feedback regarding forecasts, forecast explanations, recommended decision-making options, and user actions. This way, we provide means to improve forecasting models, explanations, and recommendations of decision-making options. We tailor the knowledge graph for the domain of demand forecasting and validate it on real-world data.
STARdom: an architecture for trusted and secure human-centered manufacturing systems
Apr 02, 2021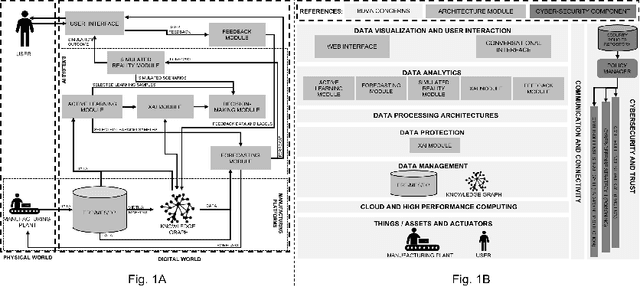
There is a lack of a single architecture specification that addresses the needs of trusted and secure Artificial Intelligence systems with humans in the loop, such as human-centered manufacturing systems at the core of the evolution towards Industry 5.0. To realize this, we propose an architecture that integrates forecasts, Explainable Artificial Intelligence, supports collecting users' feedback, and uses Active Learning and Simulated Reality to enhance forecasts and provide decision-making recommendations. The architecture security is addressed as a general concern. We align the proposed architecture with the Big Data Value Association Reference Architecture Model. We tailor it for the domain of demand forecasting and validate it on a real-world case study.
Towards Active Learning Based Smart Assistant for Manufacturing
Mar 30, 2021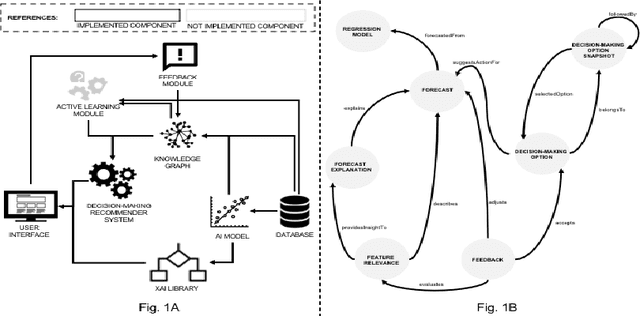
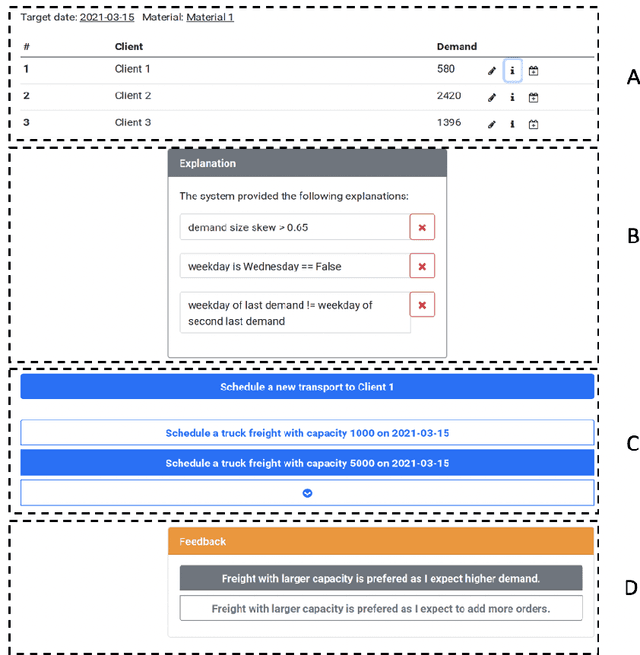
A general approach for building a smart assistant that guides a user from a forecast generated by a machine learning model through a sequence of decision-making steps is presented. We develop a methodology to build such a system. The system is demonstrated on a demand forecasting use case in manufacturing. The methodology can be extended to several use cases in manufacturing. The system provides means for knowledge acquisition, gathering data from users. We envision active learning can be used to get data labels where labeled data is scarce.