 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Student Interactions with a Pedagogical AI-Assistant for Essay Writing and their Impact on Students Writing Quality
Dec 09, 2025The dynamic nature of interactions between students and GenAI, as well as their relationship to writing quality, remains underexplored. While most research has examined how general-purpose GenAI can support writing, fewer studies have investigated how students interact with pedagogically designed systems across different phases of the writing process. To address this gap, we evaluated a GenAI-driven essay-writing assistant (EWA) designed to support higher education students in argumentative writing. Drawing on 1,282 interaction logs from 32 undergraduates during a two-hour writing session, Sequential Pattern Mining and K-Means clustering were used to identify behavioral patterns. Two clusters emerged: Cluster 1 emphasized outline planning and essay structure, while Cluster 2 focused on content development. A Mann-Whitney U test revealed a moderate effect size (r = 0.36) in the essay Organization dimension, with Cluster 1 showing higher scores. Qualitative analysis indicated that students with better performance actively wrote and shared essay sections with EWA for feedback, rather than interacted passively by asking questions. These findings suggest implications for teaching and system design. Teachers can encourage active engagement, while future EWAs may integrate automatic labeling and monitoring to prompt students to move from questioning to writing, enabling fuller benefits from GenAI-supported learning.
A Novel Approach to Scalable and Automatic Topic-Controlled Question Generation in Education
Jan 09, 2025The development of Automatic Question Generation (QG) models has the potential to significantly improve educational practices by reducing the teacher workload associated with creating educational content. This paper introduces a novel approach to educational question generation that controls the topical focus of questions. The proposed Topic-Controlled Question Generation (T-CQG) method enhances the relevance and effectiveness of the generated content for educational purposes. Our approach uses fine-tuning on a pre-trained T5-small model, employing specially created datasets tailored to educational needs. The research further explores the impacts of pre-training strategies, quantisation, and data augmentation on the model's performance. We specifically address the challenge of generating semantically aligned questions with paragraph-level contexts, thereby improving the topic specificity of the generated questions. In addition, we introduce and explore novel evaluation methods to assess the topical relatedness of the generated questions. Our results, validated through rigorous offline and human-backed evaluations, demonstrate that the proposed models effectively generate high-quality, topic-focused questions. These models have the potential to reduce teacher workload and support personalised tutoring systems by serving as bespoke question generators. With its relatively small number of parameters, the proposals not only advance the capabilities of question generation models for handling specific educational topics but also offer a scalable solution that reduces infrastructure costs. This scalability makes them feasible for widespread use in education without reliance on proprietary large language models like ChatGPT.
Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Apr 02, 2024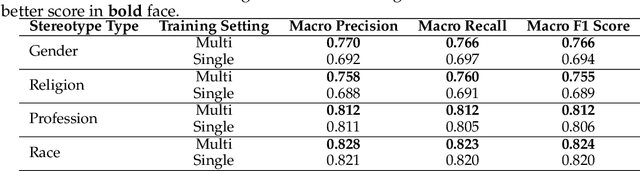


Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
A Toolbox for Modelling Engagement with Educational Videos
Dec 30, 2023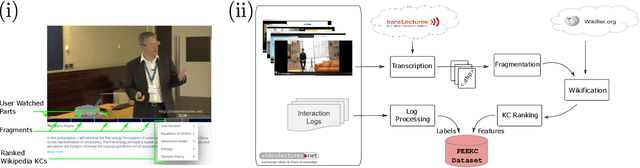

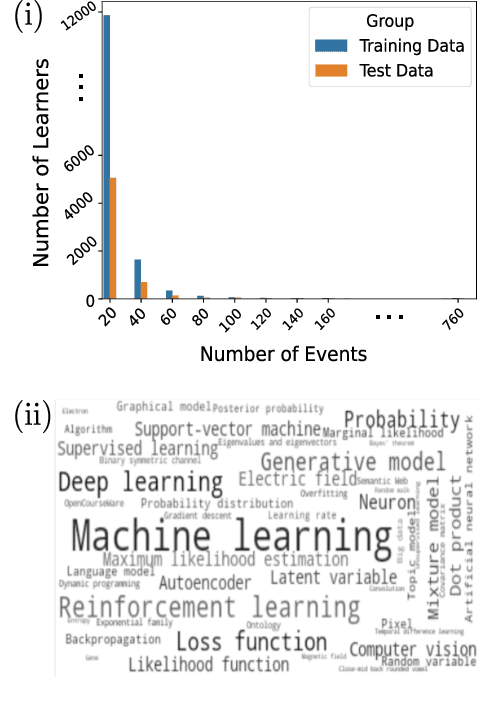
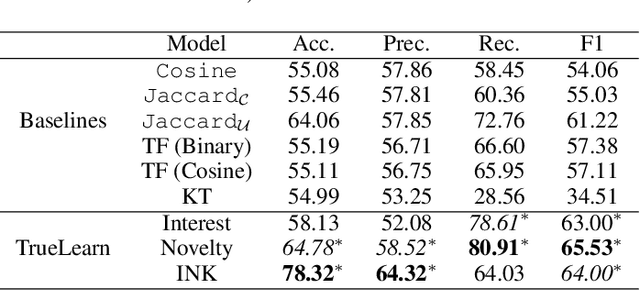
With the advancement and utility of Artificial Intelligence (AI), personalising education to a global population could be a cornerstone of new educational systems in the future. This work presents the PEEKC dataset and the TrueLearn Python library, which contains a dataset and a series of online learner state models that are essential to facilitate research on learner engagement modelling.TrueLearn family of models was designed following the "open learner" concept, using humanly-intuitive user representations. This family of scalable, online models also help end-users visualise the learner models, which may in the future facilitate user interaction with their models/recommenders. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytics practitioners. The experiments show the utility of both the dataset and the library with predictive performance significantly exceeding comparative baseline models. The dataset contains a large amount of AI-related educational videos, which are of interest for building and validating AI-specific educational recommenders.
Towards Auditing Large Language Models: Improving Text-based Stereotype Detection
Nov 23, 2023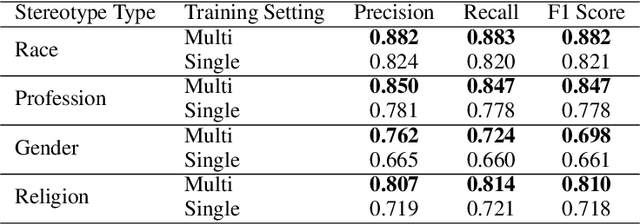
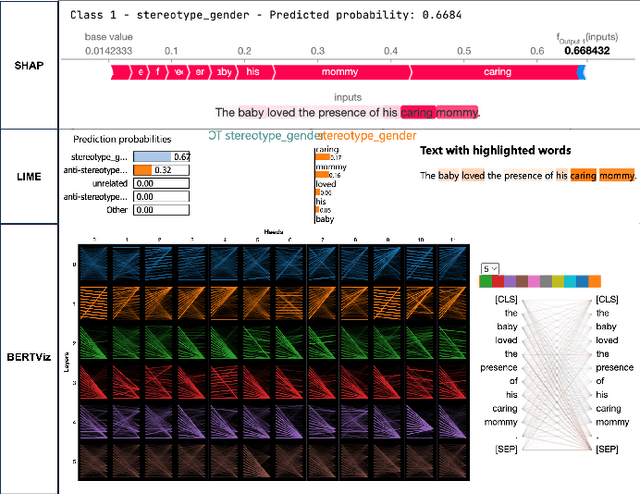

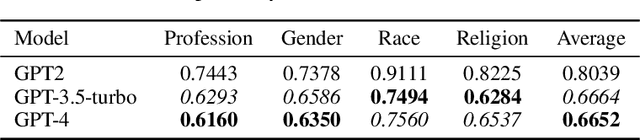
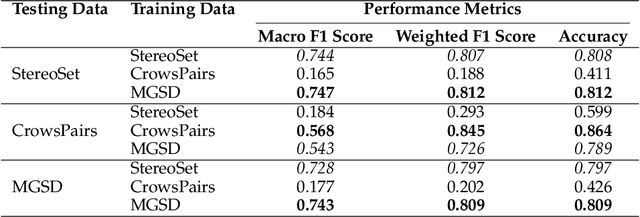
Large Language Models (LLM) have made significant advances in the recent past becoming more mainstream in Artificial Intelligence (AI) enabled human-facing applications. However, LLMs often generate stereotypical output inherited from historical data, amplifying societal biases and raising ethical concerns. This work introduces i) the Multi-Grain Stereotype Dataset, which includes 52,751 instances of gender, race, profession and religion stereotypic text and ii) a novel stereotype classifier for English text. We design several experiments to rigorously test the proposed model trained on the novel dataset. Our experiments show that training the model in a multi-class setting can outperform the one-vs-all binary counterpart. Consistent feature importance signals from different eXplainable AI tools demonstrate that the new model exploits relevant text features. We utilise the newly created model to assess the stereotypic behaviour of the popular GPT family of models and observe the reduction of bias over time. In summary, our work establishes a robust and practical framework for auditing and evaluating the stereotypic bias in LLM.
TrueLearn: A Python Library for Personalised Informational Recommendations with (Implicit) Feedback
Sep 20, 2023This work describes the TrueLearn Python library, which contains a family of online learning Bayesian models for building educational (or more generally, informational) recommendation systems. This family of models was designed following the "open learner" concept, using humanly-intuitive user representations. For the sake of interpretability and putting the user in control, the TrueLearn library also contains different representations to help end-users visualise the learner models, which may in the future facilitate user interaction with their own models. Together with the library, we include a previously publicly released implicit feedback educational dataset with evaluation metrics to measure the performance of the models. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytic practitioners. The library and the support documentation with examples are available at https://truelearn.readthedocs.io/en/latest.
Scalable Educational Question Generation with Pre-trained Language Models
May 13, 2023The automatic generation of educational questions will play a key role in scaling online education, enabling self-assessment at scale when a global population is manoeuvring their personalised learning journeys. We develop \textit{EduQG}, a novel educational question generation model built by adapting a large language model. Our extensive experiments demonstrate that \textit{EduQG} can produce superior educational questions by further pre-training and fine-tuning a pre-trained language model on the scientific text and science question data.
Pre-Training With Scientific Text Improves Educational Question Generation
Dec 07, 2022

With the boom of digital educational materials and scalable e-learning systems, the potential for realising AI-assisted personalised learning has skyrocketed. In this landscape, the automatic generation of educational questions will play a key role, enabling scalable self-assessment when a global population is manoeuvring their personalised learning journeys. We develop EduQG, a novel educational question generation model built by adapting a large language model. Our initial experiments demonstrate that EduQG can produce superior educational questions by pre-training on scientific text.
Towards Proactive Information Retrieval in Noisy Text with Wikipedia Concepts
Oct 18, 2022
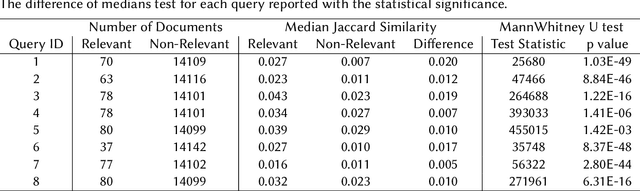


Extracting useful information from the user history to clearly understand informational needs is a crucial feature of a proactive information retrieval system. Regarding understanding information and relevance, Wikipedia can provide the background knowledge that an intelligent system needs. This work explores how exploiting the context of a query using Wikipedia concepts can improve proactive information retrieval on noisy text. We formulate two models that use entity linking to associate Wikipedia topics with the relevance model. Our experiments around a podcast segment retrieval task demonstrate that there is a clear signal of relevance in Wikipedia concepts while a ranking model can improve precision by incorporating them. We also find Wikifying the background context of a query can help disambiguate the meaning of the query, further helping proactive information retrieval.
Can Population-based Engagement Improve Personalisation? A Novel Dataset and Experiments
Jun 22, 2022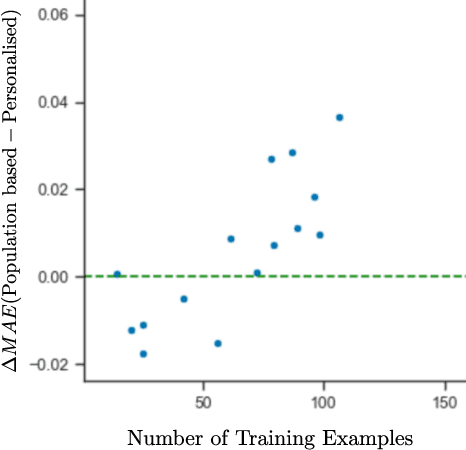
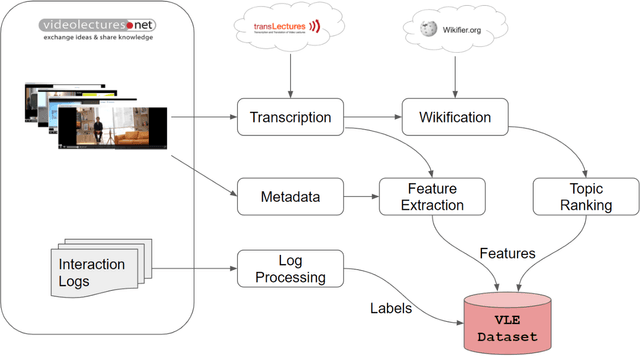
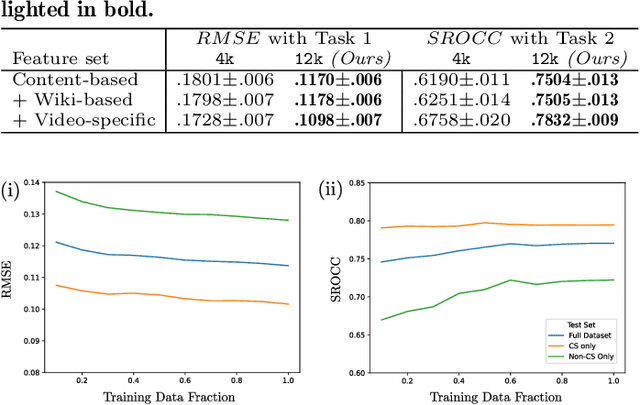
This work explores how population-based engagement prediction can address cold-start at scale in large learning resource collections. The paper introduces i) VLE, a novel dataset that consists of content and video based features extracted from publicly available scientific video lectures coupled with implicit and explicit signals related to learner engagement, ii) two standard tasks related to predicting and ranking context-agnostic engagement in video lectures with preliminary baselines and iii) a set of experiments that validate the usefulness of the proposed dataset. Our experimental results indicate that the newly proposed VLE dataset leads to building context-agnostic engagement prediction models that are significantly performant than ones based on previous datasets, mainly attributing to the increase of training examples. VLE dataset's suitability in building models towards Computer Science/ Artificial Intelligence education focused on e-learning/ MOOC use-cases is also evidenced. Further experiments in combining the built model with a personalising algorithm show promising improvements in addressing the cold-start problem encountered in educational recommenders. This is the largest and most diverse publicly available dataset to our knowledge that deals with learner engagement prediction tasks. The dataset, helper tools, descriptive statistics and example code snippets are available publicly.